
In vielen realen Anwendungen bestehen die Daten nicht nur aus Textual content – sie können auch Bilder, Tabellen und Diagramme enthalten, die zur Untermauerung der Erzählung beitragen. Mit einem multimodalen Berichtsgenerator können Sie sowohl Textual content als auch Bilder in eine Endausgabe integrieren, wodurch Ihre Berichte dynamischer und visuell ansprechender werden.
In diesem Artikel wird beschrieben, wie Sie eine solche Pipeline erstellen, indem Sie Folgendes verwenden:
- LamaIndex zur Orchestrierung von Dokumentenparsing und Abfrage-Engines,
- OpenAI Sprachmodelle zur Textanalyse,
- LamaParse um sowohl Textual content als auch Bilder aus PDF-Dokumenten zu extrahieren,
- Ein Observability-Setup mit Arize Phoenix (über LlamaTrace) zum Protokollieren und Debuggen.
Das Endergebnis ist eine Pipeline, die ein gesamtes PDF-Foliendeck – sowohl Textual content als auch Bilder – verarbeiten und einen strukturierten Bericht generieren kann, der sowohl Textual content als auch Bilder enthält.
Lernziele
- Verstehen Sie, wie Sie mithilfe multimodaler Pipelines Textual content und visuelle Elemente für eine effektive Erstellung von Finanzberichten integrieren.
- Erfahren Sie, wie Sie LlamaIndex und LlamaParse für eine verbesserte Erstellung von Finanzberichten mit strukturierten Ausgaben nutzen.
- Entdecken Sie LlamaParse zum effektiven Extrahieren von Textual content und Bildern aus PDF-Dokumenten.
- Richten Sie die Beobachtbarkeit mit Arize Phoenix (über LlamaTrace) zum Protokollieren und Debuggen komplexer Pipelines ein.
- Erstellen Sie eine strukturierte Abfrage-Engine, um Berichte zu generieren, die Textzusammenfassungen mit visuellen Elementen verknüpfen.
Dieser Artikel wurde im Rahmen der veröffentlicht Information Science-Blogathon.
Überblick über den Prozess
Beim Aufbau eines multimodalen Berichtsgenerators muss eine Pipeline erstellt werden, die Textual content- und visuelle Elemente aus komplexen Dokumenten wie PDFs nahtlos integriert. Der Prozess beginnt mit der Set up der erforderlichen Bibliotheken, z. B. LlamaIndex zum Parsen von Dokumenten und Abfrageorchestrierung sowie LlamaParse zum Extrahieren von Textual content und Bildern. Die Beobachtbarkeit wird mithilfe von Arize Phoenix (über LlamaTrace) zur Überwachung und Fehlerbehebung der Pipeline hergestellt.
Sobald die Einrichtung abgeschlossen ist, verarbeitet die Pipeline ein PDF-Dokument, analysiert seinen Inhalt in strukturierten Textual content und rendert visuelle Elemente wie Tabellen und Diagramme. Diese analysierten Elemente werden dann verknüpft, wodurch ein einheitlicher Datensatz entsteht. Ein SummaryIndex wird erstellt, um umfassende Einblicke zu ermöglichen, und eine strukturierte Abfrage-Engine wird entwickelt, um Berichte zu generieren, die Textanalysen mit relevanten visuellen Elementen verbinden. Das Ergebnis ist ein dynamischer und interaktiver Berichtsgenerator, der statische Dokumente in umfangreiche, multimodale Ausgaben umwandelt, die auf Benutzeranfragen zugeschnitten sind.
Schrittweise Umsetzung
Befolgen Sie diese ausführliche Anleitung, um einen multimodalen Berichtsgenerator zu erstellen, von der Einrichtung von Abhängigkeiten bis zur Generierung strukturierter Ausgaben mit integriertem Textual content und Bildern. Jeder Schritt gewährleistet eine nahtlose Integration von LlamaIndex, LlamaParse und Arize Phoenix für eine effiziente und dynamische Pipeline.
Schritt 1: Abhängigkeiten installieren und importieren
Sie müssen die folgenden Bibliotheken ausführen Python 3.9.9:
- Lama-Index
- Lama-Parse (für Textual content- und Bildanalyse)
- Lama-Index-Callbacks-Arize-Phoenix (zur Beobachtbarkeit/Protokollierung)
- nest_asyncio (um asynchrone Ereignisschleifen in Notebooks zu verarbeiten)
!pip set up -U llama-index-callbacks-arize-phoenix
import nest_asyncio
nest_asyncio.apply()Schritt 2: Observability einrichten
Wir integrieren mit LlamaTrace – LlamaCloud API (Arize Phoenix). Besorgen Sie sich zunächst einen API-Schlüssel von llamatrace.comund richten Sie dann Umgebungsvariablen ein, um Ablaufverfolgungen an Phoenix zu senden.
Den Phoenix-API-Schlüssel erhalten Sie, indem Sie sich bei LlamaTrace anmelden Hier navigieren Sie dann zum unteren linken Bereich und klicken Sie auf „Schlüssel“, wo Sie Ihren API-Schlüssel finden sollten.
Zum Beispiel:
PHOENIX_API_KEY = "<PHOENIX_API_KEY>"
os.environ("OTEL_EXPORTER_OTLP_HEADERS") = f"api_key={PHOENIX_API_KEY}"
llama_index.core.set_global_handler(
"arize_phoenix", endpoint="https://llamatrace.com/v1/traces"
)Schritt 3: Laden Sie die Daten – Besorgen Sie sich Ihr Foliendeck
Zur Demonstration verwenden wir das Foliendeck zum Investorentreffen 2023 von ConocoPhillips. Wir laden das PDF herunter:
import os
import requests
# Create the directories (ignore errors in the event that they exist already)
os.makedirs("knowledge", exist_ok=True)
os.makedirs("data_images", exist_ok=True)
# URL of the PDF
url = "https://static.conocophillips.com/recordsdata/2023-conocophillips-aim-presentation.pdf"
# Obtain and save to knowledge/conocophillips.pdf
response = requests.get(url)
with open("knowledge/conocophillips.pdf", "wb") as f:
f.write(response.content material)
print("PDF downloaded to knowledge/conocophillips.pdf")Überprüfen Sie, ob sich das PDF-Diadeck im Datenordner befindet. Wenn nicht, platzieren Sie es im Datenordner und benennen Sie es nach Ihren Wünschen.
Schritt 4: Modelle einrichten
Sie benötigen ein Einbettungsmodell und ein LLM. In diesem Beispiel:
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding(mannequin="text-embedding-3-large")
llm = OpenAI(mannequin="gpt-4o")Als Nächstes registrieren Sie diese als Customary für LlamaIndex:
from llama_index.core import Settings
Settings.embed_model = embed_model
Settings.llm = llmSchritt 5: Analysieren Sie das Dokument mit LlamaParse
LlamaParse kann Textual content und Bilder extrahieren (über ein multimodales großes Modell). Für jede PDF-Seite wird Folgendes zurückgegeben:
- Markdown-Textual content (mit Tabellen, Überschriften, Aufzählungspunkten usw.)
- Ein gerendertes Bild (lokal gespeichert)
print(f"Parsing slide deck...")
md_json_objs = parser.get_json_result("knowledge/conocophillips.pdf")
md_json_list = md_json_objs(0)("pages")
print(md_json_list(10)("md"))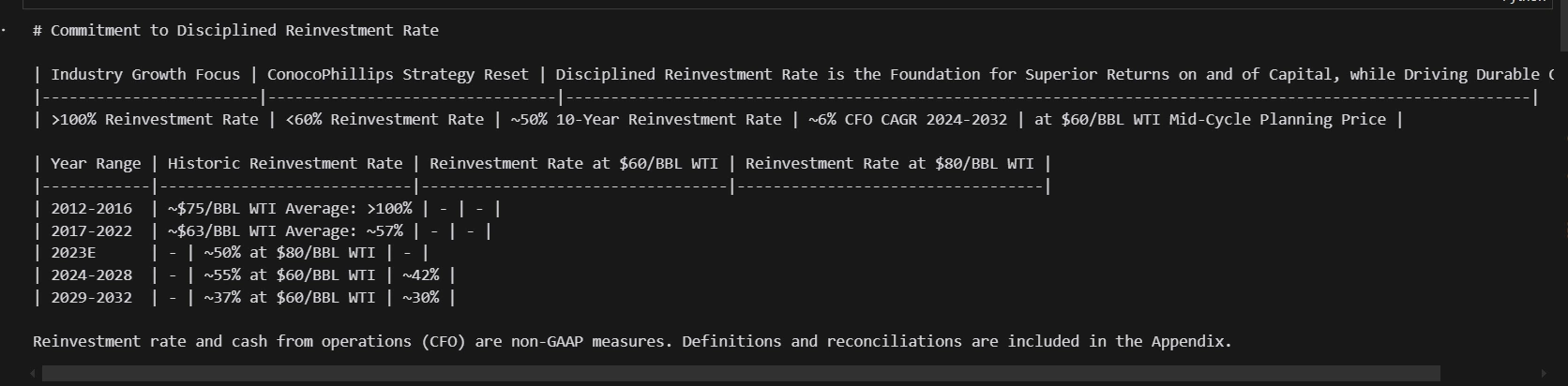
print(md_json_list(1).keys())
image_dicts = parser.get_images(md_json_objs, download_path="data_images")
Schritt 6: Verknüpfen Sie Textual content und Bilder
Wir erstellen eine Liste von TextNode Objekte (Datenstruktur von LlamaIndex) für jede Seite. Jeder Knoten verfügt über Metadaten zur Seitenzahl und zum entsprechenden Bilddateipfad:
from llama_index.core.schema import TextNode
from typing import Non-obligatory
# get pages loaded via llamaparse
import re
def get_page_number(file_name):
match = re.search(r"-page-(d+).jpg$", str(file_name))
if match:
return int(match.group(1))
return 0
def _get_sorted_image_files(image_dir):
"""Get picture recordsdata sorted by web page."""
raw_files = (f for f in record(Path(image_dir).iterdir()) if f.is_file())
sorted_files = sorted(raw_files, key=get_page_number)
return sorted_files
from copy import deepcopy
from pathlib import Path
# connect picture metadata to the textual content nodes
def get_text_nodes(json_dicts, image_dir=None):
"""Cut up docs into nodes, by separator."""
nodes = ()
image_files = _get_sorted_image_files(image_dir) if image_dir just isn't None else None
md_texts = (d("md") for d in json_dicts)
for idx, md_text in enumerate(md_texts):
chunk_metadata = {"page_num": idx + 1}
if image_files just isn't None:
image_file = image_files(idx)
chunk_metadata("image_path") = str(image_file)
chunk_metadata("parsed_text_markdown") = md_text
node = TextNode(
textual content="",
metadata=chunk_metadata,
)
nodes.append(node)
return nodes
# this may cut up into pages
text_nodes = get_text_nodes(md_json_list, image_dir="data_images")
print(text_nodes(10).get_content(metadata_mode="all"))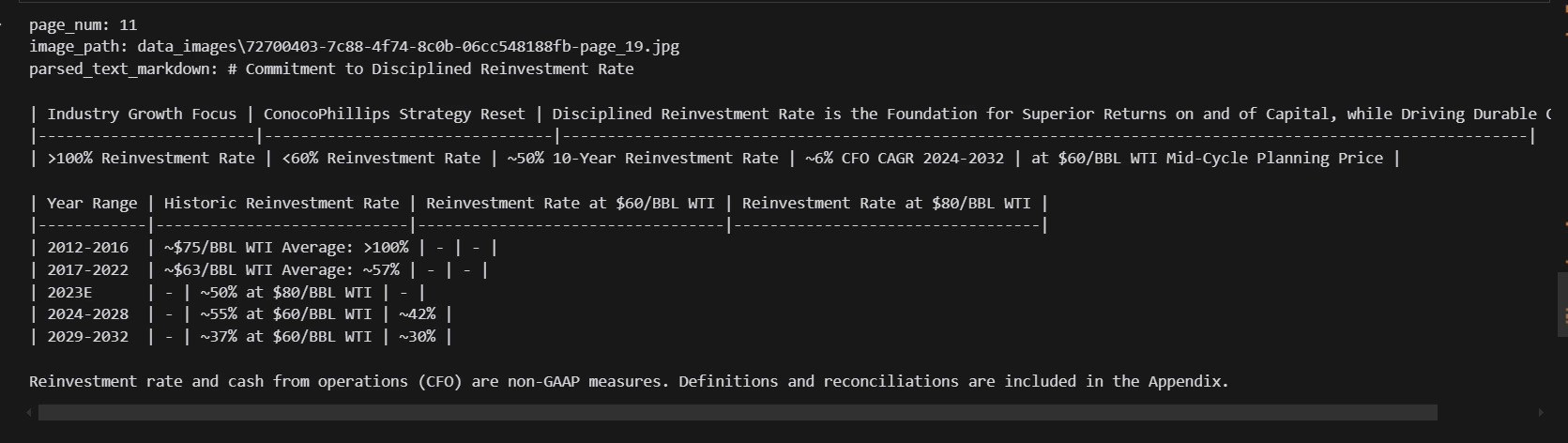
Schritt 7: Erstellen Sie einen zusammenfassenden Index
Mit diesen Textknoten können Sie einen SummaryIndex erstellen:
import os
from llama_index.core import (
StorageContext,
SummaryIndex,
load_index_from_storage,
)
if not os.path.exists("storage_nodes_summary"):
index = SummaryIndex(text_nodes)
# save index to disk
index.set_index_id("summary_index")
index.storage_context.persist("./storage_nodes_summary")
else:
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="storage_nodes_summary")
# load index
index = load_index_from_storage(storage_context, index_id="summary_index")Der SummaryIndex stellt sicher, dass Sie problemlos Zusammenfassungen auf hoher Ebene über das gesamte Dokument abrufen oder erstellen können.
Schritt 8: Definieren Sie ein strukturiertes Ausgabeschema
Unsere Pipeline zielt darauf ab, eine endgültige Ausgabe mit verschachtelten Textblöcken und Bildblöcken zu erzeugen. Dazu erstellen wir ein benutzerdefiniertes Pydantic-Modell (unter Verwendung von Pydantic v2 oder unter Sicherstellung der Kompatibilität) mit zwei Blocktypen:TextBlock Und ImageBlock– und ein übergeordnetes Modell ReportOutput:
from llama_index.llms.openai import OpenAI
from pydantic import BaseModel, Subject
from typing import Checklist
from IPython.show import show, Markdown, Picture
from typing import Union
class TextBlock(BaseModel):
"""Textual content block."""
textual content: str = Subject(..., description="The textual content for this block.")
class ImageBlock(BaseModel):
"""Picture block."""
file_path: str = Subject(..., description="File path to the picture.")
class ReportOutput(BaseModel):
"""Information mannequin for a report.
Can comprise a mixture of textual content and picture blocks. MUST comprise not less than one picture block.
"""
blocks: Checklist(Union(TextBlock, ImageBlock)) = Subject(
..., description="A listing of textual content and picture blocks."
)
def render(self) -> None:
"""Render as HTML on the web page."""
for b in self.blocks:
if isinstance(b, TextBlock):
show(Markdown(b.textual content))
else:
show(Picture(filename=b.file_path))
system_prompt = """
You're a report technology assistant tasked with producing a well-formatted context given parsed context.
You may be given context from a number of reviews that take the type of parsed textual content.
You might be accountable for producing a report with interleaving textual content and pictures - within the format of interleaving textual content and "picture" blocks.
Since you can't immediately produce a picture, the picture block takes in a file path - it is best to write within the file path of the picture as a substitute.
How have you learnt which picture to generate? Every context chunk will comprise metadata together with a picture render of the supply chunk, given as a file path.
Embody ONLY the pictures from the chunks which have heavy visible components (you may get a touch of this if the parsed textual content comprises plenty of tables).
You MUST embody not less than one picture block within the output.
You MUST output your response as a software name with the intention to adhere to the required output format. Do NOT give again regular textual content.
"""
llm = OpenAI(mannequin="gpt-4o", api_key="OpenAI_API_KEY", system_prompt=system_prompt)
sllm = llm.as_structured_llm(output_cls=ReportOutput)Der entscheidende Punkt: ReportOutput erfordert mindestens einen Bildblock, um sicherzustellen, dass die endgültige Antwort multimodal ist.
Schritt 9: Erstellen Sie eine strukturierte Abfrage-Engine
Mit LlamaIndex können Sie ein „strukturiertes LLM“ verwenden (d. h. ein LLM, dessen Ausgabe automatisch in ein bestimmtes Schema geparst wird). So geht’s:
query_engine = index.as_query_engine(
similarity_top_k=10,
llm=sllm,
# response_mode="tree_summarize"
response_mode="compact",
)
response = query_engine.question(
"Give me a abstract of the monetary efficiency of the Alaska/Worldwide phase vs. the decrease 48 phase"
)
response.response.render()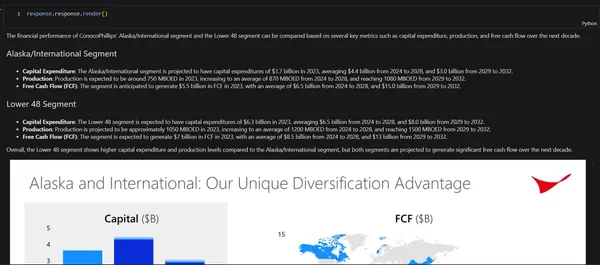
# Output
The monetary efficiency of ConocoPhillips' Alaska/Worldwide phase and the Decrease 48 phase may be in contrast primarily based on a number of key metrics reminiscent of capital expenditure, manufacturing, and free money circulate over the following decade.
Alaska/Worldwide Phase
Capital Expenditure: The Alaska/Worldwide phase is projected to have capital expenditures of $3.7 billion in 2023, averaging $4.4 billion from 2024 to 2028, and $3.0 billion from 2029 to 2032.
Manufacturing: Manufacturing is anticipated to be round 750 MBOED in 2023, rising to a median of 870 MBOED from 2024 to 2028, and reaching 1080 MBOED from 2029 to 2032.
Free Money Movement (FCF): The phase is anticipated to generate $5.5 billion in FCF in 2023, with a median of $6.5 billion from 2024 to 2028, and $15.0 billion from 2029 to 2032.
Decrease 48 Phase
Capital Expenditure: The Decrease 48 phase is anticipated to have capital expenditures of $6.3 billion in 2023, averaging $6.5 billion from 2024 to 2028, and $8.0 billion from 2029 to 2032.
Manufacturing: Manufacturing is projected to be roughly 1050 MBOED in 2023, rising to a median of 1200 MBOED from 2024 to 2028, and reaching 1500 MBOED from 2029 to 2032.
Free Money Movement (FCF): The phase is anticipated to generate $7 billion in FCF in 2023, with a median of $8.5 billion from 2024 to 2028, and $13 billion from 2029 to 2032.
Total, the Decrease 48 phase reveals larger capital expenditure and manufacturing ranges in comparison with the Alaska/Worldwide phase, however each segments are projected to generate vital free money circulate over the following decade.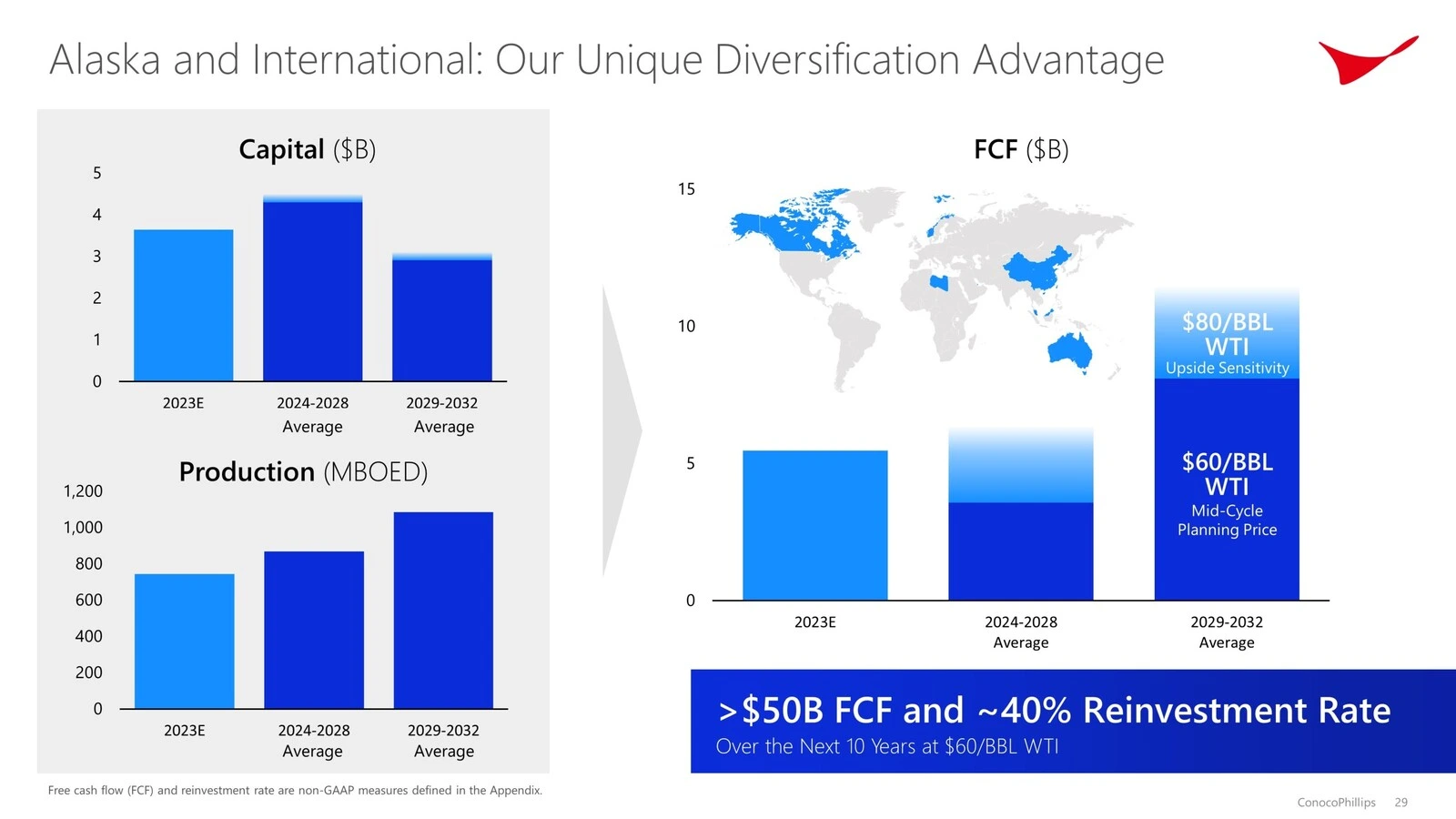
# Attempting one other question
response = query_engine.question(
"Give me a abstract of whether or not you assume the monetary projections are steady, and if not, what are the potential threat elements. "
"Help your analysis with sources."
)
response.response.render()
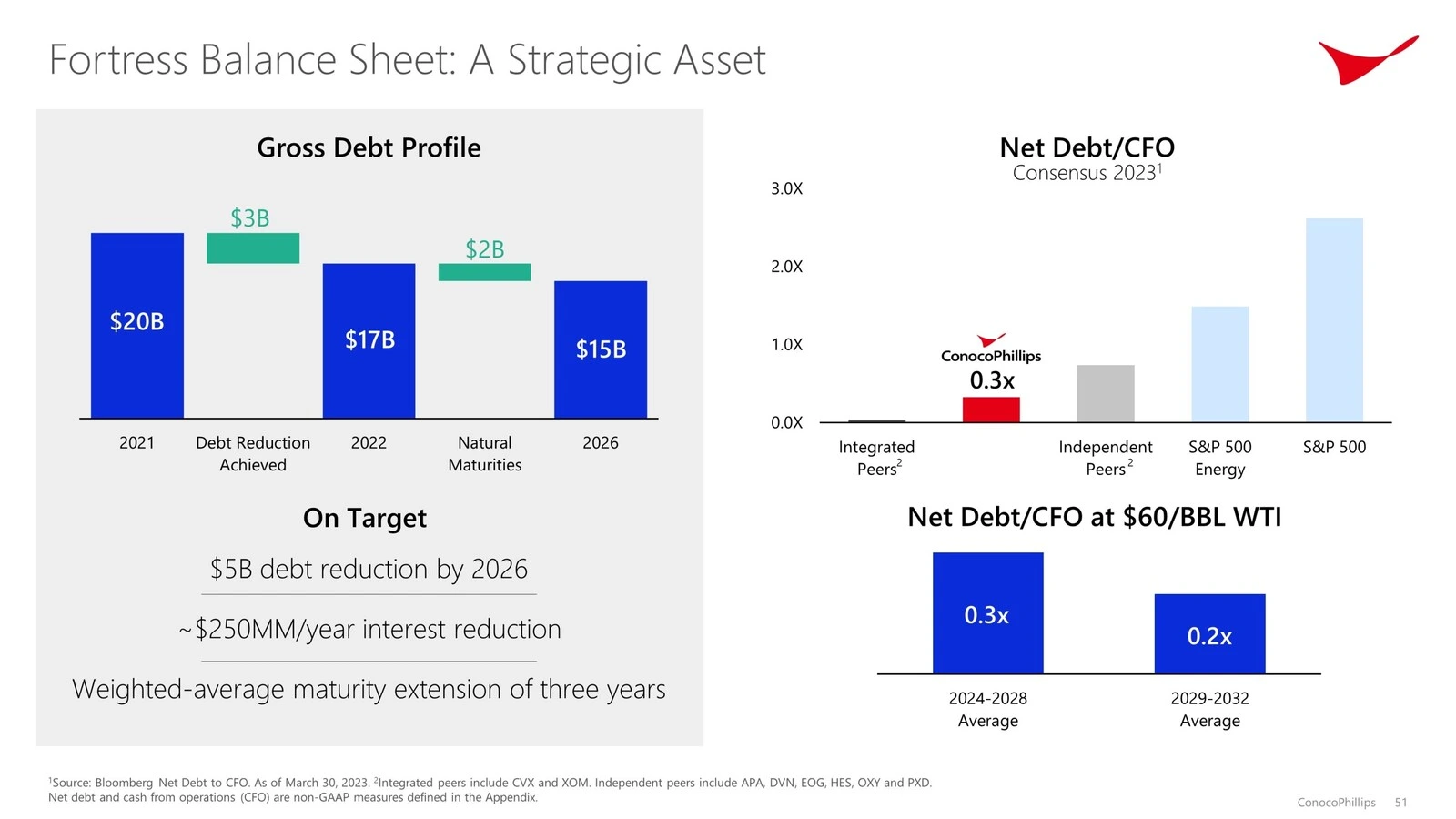
Abschluss
Durch die Kombination von LlamaIndex, LlamaParse und OpenAI können Sie einen multimodalen Berichtsgenerator erstellen, der ein gesamtes PDF (mit Textual content, Tabellen und Bildern) in eine strukturierte Ausgabe verarbeitet. Dieser Ansatz liefert reichhaltigere, visuell informativere Ergebnisse – genau das, was Stakeholder benötigen, um wichtige Erkenntnisse aus komplexen Unternehmens- oder technischen Dokumenten zu gewinnen.
Sie können diese Pipeline gerne an Ihre eigenen Dokumente anpassen, einen Abrufschritt für große Archive hinzufügen oder domänenspezifische Modelle zur Analyse der zugrunde liegenden Bilder integrieren. Mit den hier dargelegten Grundlagen können Sie dynamische, interaktive und visuell ansprechende Berichte erstellen, die weit über einfache textbasierte Abfragen hinausgehen.
Ein großes Dankeschön an Jerry Liu von LlamaIndex für die Entwicklung dieser erstaunlichen Pipeline.
Wichtige Erkenntnisse
- Wandeln Sie PDFs mit Textual content und Bildern in strukturierte Formate um und bewahren Sie gleichzeitig die Integrität des Originalinhalts mithilfe von LlamaParse und LlamaIndex.
- Erstellen Sie visuell angereicherte Berichte, die Textzusammenfassungen und Bilder für ein besseres Kontextverständnis verknüpfen.
- Die Erstellung von Finanzberichten kann durch die Integration von Textual content- und visuellen Elementen verbessert werden, um aufschlussreichere und dynamischere Ergebnisse zu erzielen.
- Die Nutzung von LlamaIndex und LlamaParse rationalisiert den Prozess der Finanzberichterstellung und sorgt für genaue und strukturierte Ergebnisse.
- Rufen Sie relevante Dokumente vor der Verarbeitung ab, um die Berichterstellung für große Archive zu optimieren.
- Verbessern Sie die visuelle Analyse, integrieren Sie diagrammspezifische Analysen und kombinieren Sie Modelle für die Textual content- und Bildverarbeitung für tiefere Einblicke.
Häufig gestellte Fragen
A. Ein multimodaler Berichtsgenerator ist ein System, das Berichte mit mehreren Inhaltstypen – hauptsächlich Textual content und Bilder – in einer zusammenhängenden Ausgabe erstellt. In dieser Pipeline zerlegen Sie ein PDF in Textual content- und visuelle Elemente und kombinieren diese dann in einem einzigen Abschlussbericht.
A. Mit Observability-Instruments wie Arize Phoenix (über LlamaTrace) können Sie das Modellverhalten überwachen und debuggen, Abfragen und Antworten verfolgen und Probleme in Echtzeit identifizieren. Dies ist besonders nützlich, wenn Sie mit großen oder komplexen Dokumenten und mehreren LLM-basierten Schritten arbeiten.
A. Die meisten PDF-Textextraktoren verarbeiten nur Rohtext und verlieren häufig Formatierungen, Bilder und Tabellen. LlamaParse ist in der Lage, sowohl Textual content als auch Bilder (gerenderte Seitenbilder) zu extrahieren, was für den Aufbau multimodaler Pipelines, bei denen Sie auf Tabellen, Diagramme oder andere visuelle Elemente zurückgreifen müssen, von entscheidender Bedeutung ist.
A. SummaryIndex ist eine LlamaIndex-Abstraktion, die Ihre Inhalte (z. B. Seiten einer PDF-Datei) organisiert, sodass schnell umfassende Zusammenfassungen erstellt werden können. Es hilft dabei, umfassende Erkenntnisse aus langen Dokumenten zu gewinnen, ohne diese manuell aufzuteilen oder für jedes Datenelement eine Abrufabfrage ausführen zu müssen.
A. Erzwingen Sie im ReportOutput Pydantic-Modell, dass die Blockliste mindestens einen ImageBlock erfordert. Dies ist in Ihrer Systemeingabeaufforderung und Ihrem Schema angegeben. Der LLM muss diese Regeln befolgen, sonst erzeugt er keine gültige strukturierte Ausgabe.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Hallo! Ich bin Adarsh, ein Enterprise Analytics-Absolvent der ISB, der sich derzeit intensiv mit der Forschung und der Erkundung neuer Grenzen beschäftigt. Ich habe eine große Leidenschaft für Datenwissenschaft, KI und all die innovativen Möglichkeiten, wie sie Branchen verändern können. Ob es darum geht, Modelle zu erstellen, an Datenpipelines zu arbeiten oder in maschinelles Lernen einzutauchen, ich liebe es, mit der neuesten Technologie zu experimentieren. KI ist nicht nur mein Interesse, sie ist auch die Richtung, in die ich die Zukunft sehe, und ich freue mich immer, Teil dieser Reise zu sein!