Die Qwen-Familie von Visionsprachmodellen entwickelt sich weiterentwickelt, wobei die Freisetzung von Qwen2.5-VL einen bedeutenden Sprung nach vorne markiert. Auf dem Erfolg von QWEN2-VL, der vor fünf Monaten eingeführt wurde, profitiert QWEN2.5-VL von wertvollem Suggestions und Beiträgen der Entwicklergemeinschaft. Dieses Suggestions hat eine Schlüsselrolle bei der Verfeinerung des Modells, der Hinzufügen neuer Funktionen und der Optimierung seiner Fähigkeiten gespielt. In diesem Artikel werden wir die Architektur von QWEN2.5-VL sowie ihre Funktionen und Fähigkeiten untersuchen.
Was ist Qwen2.5-VL?
Das QWEN-Modell von Alibaba Cloud hat mit dem neuen QWEN2.5-VL ein Imaginative and prescient-Improve erhalten. Es ist so konzipiert, dass es modernste Sichtfunktionen für komplexe reale Aufgaben bietet. Hier ist, was die erweiterten Funktionen dieses neuen Modells tun können:
- Omnidocument Parsing: Erweitert die Texterkennung, um mehrsprachige Dokumente zu verarbeiten, einschließlich handschriftlicher Notizen, Tabellen, Diagramme, chemischen Formeln und Musikblättern.
- Präzisionsobjekt Erdung: Erkennt und lokalisiert Objekte mit verbesserter Genauigkeit und unterstützt absolute Koordinaten und JSON -Formate für die fortschrittliche räumliche Analyse.
- Extremely langer Videoverständnis: Verarbeitet mehrstündige Movies durch dynamische Body-Price-Stichproben und zeitliche Auflösung, wodurch eine präzise Ereignissegmentierung ermöglicht wird.
- Verbesserte Agentenfunktionen: Ermächtigt Geräte wie Smartphones und Pc mit überlegener Entscheidungsfindung, Erdung und Begründung für interaktive Aufgaben.
- Langform-Videoverständnis: Verarbeitet stundenlange Movies mit dynamischer Body-Price-Stichproben und zeitlicher Codierung, ermöglichen eine präzise Ereignislokalisierung, die Erstellung der Zusammenfassung und die gezielte Informationsextraktion.
- Integration mit Workflows: Automatisiert die Dokumentenverarbeitung, die Objektverfolgung und die Videoindexierung mit strukturierten JSON -Ausgängen und QWENVL HTML, wobei die KI -Funktionen nahtlos mit Unternehmens -Workflows verbunden sind.
Lesen Sie auch: Chinesische Riesengefühl: Deepseek-V3 gegen Qwen2.5
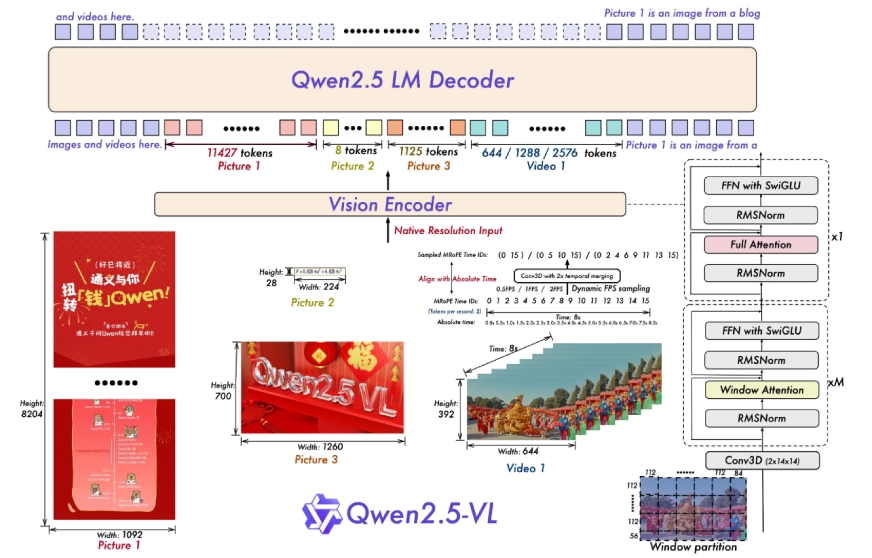
QWEN2.5-VL: Modellarchitektur
In der Architektur des Modells werden zwei wichtige Innovationen eingeführt:
- Dynamische Auflösung und Bildrate -Coaching: Es passt die Bildrate (FPS) von Movies an unterschiedliche zeitliche Bedingungen an. Es verwendet MROPE (mehrdimensionale Rotationspositionsinbettierung), um Zeitdaten auszurichten und Momente in Movies genau zu verfolgen.

2. Stromlinien -Visionscodierer: Es verbessert den Sehtransformator (VIT) durch Verbesserung der Aufmerksamkeitsmechanismen und Aktivierungsfunktionen. Dies erleichtert schnelleres und effizienteres Coaching und Inferenz, sodass es mit dem Sprachmodell von Qwen2.5 nahtlos funktioniert.
QWEN2.5-VL: Modellfunktionen
Probieren wir nun einige Eingabeaufforderungen aus und testen die Fähigkeiten von Qwen2.5-VL.
1. Globale Bilderkennung
QWEN2.5-VL kann eine erweiterte Kategorienspanne identifizieren, darunter Flora, Fauna, globale Sehenswürdigkeiten, Movie/TV-IPs und kommerzielle Produkte.
Testen wir es mit einem Beispiel.
Immediate: „Was sind diese Attraktionen? Bitte geben Sie ihre Namen in Hindi und Englisch an. “

Antwort durch QWEN2.5-VL-72B-Instruct:
Die Attraktionen in den Bildern sind:
- Rote Fort (लाल क़िला) – Das Bild zeigt einen Teil der roten Fort, ein historisches Fort in Delhi, Indien.
- Humayuns Seize (हुमायूँ का मकबमकबा) – Dies ist ein Mogul -Architekturgrab in Delhi.
- India Gate (इंडिया गेट) – Ein Kriegsdenkmal, das sich auf dem Rajpath befindet, am östlichen Rand der ‚zeremoniellen Achse‘ von Neu -Delhi.
- QUTUB MINAR (क़ुतुब मीनार) – Ein Minarett- und „Siegerturm“, der Teil des QUTB -Komplexes ist, ein UNESCO -Weltkulturerbe in der Area Mehauli in Neu -Delhi.
2. Präzise Objekt Erdung
Das Modell verwendet Begrenzungsboxen und Punktkoordinaten für die hierarchische Objektlokalisierung und gibt standardisierte JSON für räumliches Denken aus.
Immediate: „Suchen Sie jeden Kuchen und beschreiben Sie ihre Merkmale, geben Sie die Boxkoordinaten im JSON -Format aus.“

Antwort von Qwen2.5-VL:

3.. Erweiterte Texterkennung
Verbesserte OCR-Funktionen unterstützen mehrsprachige, multi-orientierende Textextraktion, entscheidend für Finanzprüfungen und Compliance-Workflows.
Immediate: „Erkennen Sie den gesamten Textual content im Bild mit Zeilenebene und Ausgabe im JSON-Format.“

Antwort von Qwen2.5-VL:

4. Dokument analysieren mit Qwenvl HTML
Ein proprietäres Format extrahiert Layoutdaten (Überschriften, Absätze, Bilder) aus Magazinen, Forschungsarbeiten und mobilen Screenshots.
Immediate: „Strukturieren Sie diesen technischen Bericht in HTML mit Begrenzungsboxen für Titel, Abstracts und Figuren.“

Antwort von Qwen2.5-VL:

QWEN2.5-VL: Leistungsvergleich
Qwen2.5-VL zeigt hochmoderne Ergebnisse in verschiedenen Benchmarks und festigt seine Place als führend bei sehverzügigen Aufgaben. Das Flaggschiff QWEN2.5-VL-72B-Instruct ist in Problemlösungen auf Faculty-Ebene, mathematischem Denken, Dokumentenverständnis, Videoanalyse und agentenbasierten Anwendungen hervorgerufen. Insbesondere übertrifft es die Wettbewerber im Dokument-/Diagrammverständnis und fungiert als visuelles Agent ohne aufgabenspezifische Feinabstimmung.
Das Modell übertrifft Konkurrenten wie Gemini-2 Flash, GPT-4O und Claude3.5 Sonett über Benchmarks wie MMMU (70,2), Docvqa (96,4) und Videomme (73,3/79.1).

Für kleinere Modelle übertrifft Qwen2.5-VL-7B-Instruct GPT-4O-Mini in mehreren Aufgaben Effizienz ohne Kompromissfähigkeit.


So greifen Sie auf QWEN2.5-VL zu
Sie können auf 2 Arten auf QWEN2.5VL zugreifen – indem Sie Huggin -Gesichtstransformatoren oder mit der API verwenden. Lassen Sie uns beide Wege verstehen.
Durch umarmende Gesichtstransformatoren
Um auf das QWEN2.5-VL-Modell mit dem Umarmungsgesicht zuzugreifen, folgen Sie folgenden Schritten:
1. Installieren Sie Abhängigkeiten
Stellen Sie zunächst sicher, dass Sie die neueste Model von Hugging Face -Transformers haben und beschleunigen, indem Sie sie aus der Quelle installieren:
pip set up git+https://github.com/huggingface/transformers speed upInstallieren Sie auch QWEN-VL-UTILS zum Umgang mit verschiedenen Arten von visuellen Eingaben:
pip set up qwen-vl-utils(decord)==0.0.8
Wenn Sie nicht unter Linux sind, können Sie ohne die (Decord) -Funktion installieren. Wenn Sie es jedoch benötigen, versuchen Sie es jedoch mit der Quelle zu installieren.
2. Laden Sie das Modell und den Tokenizer
Verwenden Sie den folgenden Code, um das QWEN2.5-VL-Modell und das Tokenizer vom Umarmungsgesicht zu laden:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
# Load the mannequin
mannequin = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct", torch_dtype="auto", device_map="auto"
)
# Load the processor for dealing with inputs (pictures, textual content, and many others.)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct")
3. Bereiten Sie die Eingabe vor (Bild + Textual content)
Sie können Bilder und Textual content in verschiedenen Formaten (URLs, Base64 oder lokale Pfade) bereitstellen. Hier ist ein Beispiel mit einer Bild -URL:
messages = (
{
"position": "person",
"content material": (
{"kind": "picture", "picture": "https://path.to/your/picture.jpg"},
{"kind": "textual content", "textual content": "Describe this picture."}
)
}
)
4. Verarbeiten Sie die Eingänge
Bereiten Sie die Eingabe für das Modell mit Bildern und Textual content vor und tokenisieren den Textual content:
# Course of the messages (pictures + textual content)
textual content = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
textual content=(textual content),
pictures=image_inputs,
movies=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda") # Transfer the enter to GPU if obtainable
5. Erzeugen Sie den Ausgang
Generieren Sie die Ausgabe des Modells basierend auf den Eingängen:
# Generate the output from the mannequin
generated_ids = mannequin.generate(**inputs, max_new_tokens=128)
# Decode the output
generated_ids_trimmed = (
out_ids(len(in_ids):) for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
)
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(output_text)
API -Zugang
So können Sie auf die API zugreifen DashScope:
import dashscope
# Set your Dashscope API key
dashscope.api_key = "your_api_key"
# Make the API name with the specified mannequin and messages
response = dashscope.MultiModalConversation.name(
mannequin="qwen2.5-vl-72b-instruct",
messages=({"position": "person", "content material": ({"picture": "image_url"}, {"textual content": "Question"})})
)
# You'll be able to entry the response right here
print(response)
Stellen Sie sicher, dass Sie „your_api_key“ durch Ihre tatsächliche API -Style und „Image_url“ durch die URL des Bildes zusammen mit dem Abfragetext ersetzen.
Anwendungsfälle im wirklichen Leben
Die Upgrades von Qwen2.5-VL entsperren verschiedene Anwendungen in Branchen und verändern die Interaktion von Fachleuten mit visuellen und textuellen Daten. Hier sind einige seiner realen Anwendungsfälle:
1. Dokumentanalyse
Das Modell revolutioniert Workflows, indem komplexe Materialien wie mehrsprachige Forschungsarbeiten, handgeschriebene Notizen, Finanzrechnungen und technische Diagramme mühelos analysieren.
- In der Bildung hilft es Schülern und Forschern, Formeln oder Daten aus gescannten Lehrbüchern zu extrahieren.
- Banken können es verwenden, um Compliance -Überprüfungen durch Lesen von Tabellen in Verträgen zu automatisieren.
- Anwaltskanzleien können mit diesem Modell schnell mehrsprachige Rechtsdokumente analysieren.
2. Industrieautomatisierung
Bei der Erkennung von Pinpoint-Objekten und den JSON-formatierten Koordinaten steigert Qwen2.5-VL die Präzision in Fabriken und Lagern.
- Roboter können seine räumliche Argumentation verwenden, um Elemente an Förderbändern zu identifizieren und zu sortieren.
- Qualitätskontrollsysteme können Defekte in Produkten wie Leiterplatten oder Maschinenteilen erkennen.
- Logistikteams können Sendungen in Echtzeit verfolgen, indem sie Warehouse -Kamera -Feeds analysieren.
3. Medienproduktion
Die Videoanalysefähigkeiten des Modells sparen Stunden für Inhaltsersteller. Es kann einen 2-stündigen Dokumentarfilm scannen, um Schlüsselszenen zu taggen, Kapitelzusammenfassungen zu generieren oder Clips bestimmter Ereignisse zu extrahieren (z. B. „alle Aufnahmen des Eiffelturms“).
- Nachrichtenagenturen können es verwenden, um archiviertes Filmmaterial zu indexieren.
- Social-Media-Groups können automatische Bildunterschriften für Videoposten in mehreren Sprachen generieren.
4. Integration intelligenter Geräte
QWEN2.5-VL macht „AI-Assistenten“, die Bildschirminhalte verstehen und Aufgaben automatisieren.
- Auf Smartphones können App -Schnittstellen gelesen werden, um Flüge zu buchen oder Formulare ohne manuelle Eingabe auszufüllen.
- In Good Houses können Roboter durch die Analyse von Kamera -Feeds fehlgeleitete Elemente lokalisieren.
- Büroangestellte können es verwenden, um sich wiederholende Desktop -Aufgaben zu automatisieren, z. B. das Organisieren von Dateien basierend auf Dokumentinhalten.
Abschluss
QWEN2.5-VL ist ein wichtiger Schritt in der AI-Technologie, der Textual content, Bilder und Videoverständnisse kombiniert. In diesen früheren Versionen wird dieses Modell aufgebaut und führt intelligenteren Funktionen wie das Lesen komplexer Dokumente ein, einschließlich handschriftlicher Notizen und Diagramme. Es zeigt auch Objekte in Bildern mit präzisen Koordinaten und analysiert stundenlange Movies, um wichtige Momente zu identifizieren.
QWEN2.5-VL ist einfach zugänglich über Plattformen wie das Umarmen von Gesicht oder APIs und stellt für alle leistungsstarke KI-Instruments zur Verfügung. Durch die Bekämpfung der realen Herausforderungen von der Reduzierung der manuellen Dateneingabe bis zur Beschleunigung der Inhaltserstellung QWEN2.5-VL zeigt, dass die fortgeschrittene KI nicht nur für Labors ist. Es ist ein praktisches Werkzeug, das alltägliche Workflows weltweit umformiert.
Häufig gestellte Fragen
A. Qwen2.5-VL ist ein erweitertes multimodales KI-Modell, das sowohl Bilder als auch Textual content verarbeiten und verstehen kann. Es kombiniert progressive Technologien, um genaue Ergebnisse für Aufgaben wie Dokumentenanalyse, Objekterkennung und Videoanalyse zu liefern.
A. Qwen2.5-VL führt architektonische Verbesserungen wie MROPE ein, um eine bessere räumliche und zeitliche Ausrichtung, einen effizienteren Visionscodierer und ein dynamisches Auflösungstraining zu erzielen, sodass es Modelle wie GPT-4O und Gemini-2-Flash übertreffen kann.
A. Branchen wie Finanzen, Logistik, Medien und Bildung können von den Funktionen von QWEN2.5-VL in Bezug auf Dokumentenverarbeitung, Automatisierung und Videoverständnis profitieren und dazu beitragen, komplexe Herausforderungen mit verbesserter Effizienz zu lösen.
A. Qwen2.5-VL ist über Plattformen wie das Umarmung von Gesicht, APIs und Kanten-kompatible Versionen zugänglich, die auf Geräten mit begrenzter Rechenleistung ausgeführt werden können.
A. Qwen2.5-VL ist aufgrund seiner hochmodernen Leistung, der Fähigkeit, lange Movies, Präzision bei der Objekterkennung und Vielseitigkeit in realen Anwendungen zu verarbeiten, die alle durch fortschrittliche technologische Innovationen erreicht werden.
A. Ja, Qwen2.5-VL zeichnet sich im Dokumenten-Parsen aus und macht es zu einer idealen Lösung für die Handhabung und Analyse großer Mengen von Textual content und Bildern aus Dokumenten in verschiedenen Branchen.
A. Ja, QWEN2.5-VL verfügt über kandidierbare Versionen, mit denen Unternehmen mit begrenzter Verarbeitungsleistung ihre Funktionen nutzen können, wodurch es auch für kleinere Unternehmen oder Umgebungen mit weniger Rechenkapazität zugänglich ist.
Hallo, ich bin Janvi, ein leidenschaftlicher Knowledge -Science -Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Daten der Daten begann mit einer tiefen Neugier darüber, wie wir aus komplexen Datensätzen sinnvolle Erkenntnisse herausholen können.