
Bewertung Großspracher Modelle (LLMs) ist wesentlich. Sie müssen verstehen, wie intestine sie funktionieren und sicherstellen, dass sie Ihren Requirements entsprechen. Die Umarmungsgesichts -Evaluieren -Bibliothek bietet eine hilfreiche Instruments für diese Aufgabe. Dieser Leitfaden zeigt, wie Sie die Evaluierenbibliothek verwenden, um LLMs mit praktischen Codebeispielen zu bewerten.
Verständnis der umarmenden Gesichtsbewertung Bibliothek
Die Umarmungsgesichts -Evaluse -Bibliothek bietet Instruments für unterschiedliche Bewertungsanforderungen. Diese Werkzeuge fallen in drei Hauptkategorien:
- Metriken: Diese messen die Leistung eines Modells, indem er seine Vorhersagen mit Bodenwahrheitsbezeichnungen verglichen. Beispiele sind Genauigkeit, F1-Rating, Bleu und Rouge.
- Vergleiche: Diese helfen dabei, zwei Modelle zu vergleichen, häufig untersucht, wie ihre Vorhersagen miteinander oder mit Referenzetiketten übereinstimmen.
- Messungen: Diese Instruments untersuchen die Eigenschaften von Datensätzen selbst, z. B. die Berechnung der Textkomplexität oder die Beschriftung von Verteilungen.
Sie können über eine einzelne Funktion auf alle diese Bewertungsmodule zugreifen: consider.load ().
Erste Schritte
Set up
Zuerst müssen Sie die Bibliothek installieren. Öffnen Sie Ihr Terminal oder Eingabeaufforderung und führen Sie aus:
pip set up consider
pip set up rouge_score # Wanted for textual content technology metrics
pip set up consider(visualization) # For plotting capabilitiesDiese Befehle installieren die Core Evaluse -Bibliothek, das Rouge_Score -Paket (erforderlich für die ROUGE Metrik häufig in Zusammenfassung verwendet) und optionale Abhängigkeiten für die Visualisierung wie Radarplots.
Laden eines Bewertungsmoduls
Um ein bestimmtes Bewertungstool zu verwenden, laden Sie es mit Namen. Zum Beispiel zum Laden der Genauigkeitsmetrik:
import consider
accuracy_metric = consider.load("accuracy")
print("Accuracy metric loaded.")Ausgabe:

Dieser Code importiert die Evaluse -Bibliothek und lädt das Genauigkeitsmetrikobjekt. Sie werden dieses Objekt verwenden, um die Genauigkeitswerte zu berechnen.
Grundlegende Bewertungsbeispiele
Gehen wir durch einige gemeinsame Bewertungsszenarien.
Computergenauigkeit direkt
Sie können eine Metrik berechnen, indem Sie alle Referenzen (Grundwahrheit) und Vorhersagen gleichzeitig bereitstellen.
import consider
# Load the accuracy metric
accuracy_metric = consider.load("accuracy")
# Pattern floor reality and predictions
references = (0, 1, 0, 1)
predictions = (1, 0, 0, 1)
# Compute accuracy
end result = accuracy_metric.compute(references=references, predictions=predictions)
print(f"Direct computation end result: {end result}")
# Instance with exact_match metric
exact_match_metric = consider.load('exact_match')
match_result = exact_match_metric.compute(references=('whats up world'), predictions=('whats up world'))
no_match_result = exact_match_metric.compute(references=('whats up'), predictions=('hell'))
print(f"Actual match end result (match): {match_result}")
print(f"Actual match end result (no match): {no_match_result}")Ausgabe:

Erläuterung:
- Wir definieren zwei Hear: Referenzen enthält die richtigen Beschriftungen und Vorhersagen hält die Ausgaben des Modells.
- Die Rechenmethode nimmt diese Hear an und berechnet die Genauigkeit und gibt das Ergebnis als Wörterbuch zurück.
- Wir zeigen auch die exakt_match -Metrik, die überprüft, ob die Vorhersage perfekt mit der Referenz übereinstimmt.
Inkrementelle Bewertung (mit add_batch)
Für große Datensätze können die Verarbeitung von Vorhersagen in Stapeln speichereffizienter sein. Sie können inkrementell Stapel hinzufügen und die Endergebnis am Ende berechnen.
import consider
# Load the accuracy metric
accuracy_metric = consider.load("accuracy")
# Pattern batches of refrences and predictions
references_batch1 = (0, 1)
predictions_batch1 = (1, 0)
references_batch2 = (0, 1)
predictions_batch2 = (0, 1)
# Add batches incrementally
accuracy_metric.add_batch(references=references_batch1, predictions=predictions_batch1)
accuracy_metric.add_batch(references=references_batch2, predictions=predictions_batch2)
# Compute ultimate accuracy
final_result = accuracy_metric.compute()
print(f"Incremental computation end result: {final_result}")Ausgabe:

Erläuterung:
- Wir simulieren Verarbeitungsdaten in zwei Chargen.
- Add_Batch aktualisiert den internen Standing der Metrik mit jeder Stapel.
- Das Aufrufen von compute () ohne Argumente berechnet die Metrik über alle hinzugefügten Chargen.
Kombinieren mehrerer Metriken
Sie möchten oft mehrere Metriken gleichzeitig berechnen (z. B. Genauigkeit, F1, Präzision, Rückruf zur Klassifizierung). Der consider.mix Funktion vereinfacht dies.
import consider
# Mix a number of classification metrics
clf_metrics = consider.mix(("accuracy", "f1", "precision", "recall"))
# Pattern information
predictions = (0, 1, 0)
references = (0, 1, 1) # Notice: The final prediction is inaccurate
# Compute all metrics without delay
outcomes = clf_metrics.compute(predictions=predictions, references=references)
print(f"Mixed metrics end result: {outcomes}")Ausgabe:

Erläuterung:
- consider.mix Nimmt eine Liste metrischer Namen und gibt ein kombiniertes Bewertungsobjekt zurück.
- Das Aufrufen von Pc auf diesem Objekt berechnet alle angegebenen Metriken mit denselben Eingabedaten.
Verwenden von Messungen
Messungen können zur Analyse von Datensätzen verwendet werden. Hier erfahren Sie, wie Sie die Messung word_length verwenden:
import consider
# Load the word_length measurement
# Notice: Could require NLTK information obtain on first run
attempt:
word_length = consider.load("word_length", module_type="measurement")
information = ("whats up world", "that is one other sentence")
outcomes = word_length.compute(information=information)
print(f"Phrase size measurement end result: {outcomes}")
besides Exception as e:
print(f"Couldn't run word_length measurement, presumably NLTK information lacking: {e}")
print("Making an attempt NLTK obtain...")
import nltk
nltk.obtain('punkt') # Uncomment and run if wantedAusgabe:

Erläuterung:
- Wir laden Word_Length und geben module_type = ”Messung an.
- Die Computermethode nimmt den Datensatz (eine Liste von Zeichenfolgen hier) als Eingabe.
- Es gibt Statistiken über die Wortlängen in den bereitgestellten Daten zurück. (Hinweis: Erfordert NLTK und seine Punkt -Tokenizer -Daten).
Bewertung spezifischer NLP -Aufgaben
Unterschiedliche NLP -Aufgaben erfordern spezifische Metriken. Umarme Gesichtsbewertung umfasst viele Normal.
Maschinelle Übersetzung (Bleu)
Bleu (zweisprachige Bewertungsstuddie) ist für die Übersetzungsqualität üblich. Es misst die n-Gramm-Überlappung zwischen der Translation (Hypothese) und Referenzübersetzungen des Modells.
import consider
def evaluate_machine_translation(hypotheses, references):
"""Calculates BLEU rating for machine translation."""
bleu_metric = consider.load("bleu")
outcomes = bleu_metric.compute(predictions=hypotheses, references=references)
# Extract the principle BLEU rating
bleu_score = outcomes("bleu")
return bleu_score
# Instance hypotheses (mannequin translations)
hypotheses = ("the cat sat on mat.", "the canine performed in backyard.")
# Instance references (right translations, can have a number of per speculation)
references = (("the cat sat on the mat."), ("the canine performed within the backyard."))
bleu_score = evaluate_machine_translation(hypotheses, references)
print(f"BLEU Rating: {bleu_score:.4f}") # Format for readabilityAusgabe:

Erläuterung:
- Die Funktion lädt die BLEU -Metrik.
- Es berechnet den Rating, in dem die vorhergesagten Übersetzungen (Hypothesen) mit einem oder mehreren korrekten Referenzen verglichen werden.
- Ein höherer BLEU -Rating (näher an 1,0) zeigt im Allgemeinen eine bessere Übersetzungsqualität an, was auf mehr Überlappung mit Referenzübersetzungen hinweist. Eine Punktzahl von rund 0,51 deutet auf eine mäßige Überlappung hin.
Genannte Entitätserkennung (NER – mit Seqeval)
Für Sequenzmarkierungsaufgaben wie NER sind Metriken wie Präzision, Rückruf und F1-Rating professional Entitätstyp nützlich. Das seqevale metrische behandelt dieses Format (z. B. B-per, i-per, o-Tags).
Um den folgenden Code auszuführen, wäre die Seqeval Library erforderlich. Es könnte installiert werden, indem der folgende Befehl ausgeführt wird:
pip set up seqevalCode:
import consider
# Load the seqeval metric
attempt:
seqeval_metric = consider.load("seqeval")
# Instance labels (utilizing IOB format)
true_labels = (('O', 'B-PER', 'I-PER', 'O'), ('B-LOC', 'I-LOC', 'O'))
predicted_labels = (('O', 'B-PER', 'I-PER', 'O'), ('B-LOC', 'I-LOC', 'O')) # Instance: Excellent prediction right here
outcomes = seqeval_metric.compute(predictions=predicted_labels, references=true_labels)
print("Seqeval Outcomes (per entity sort):")
# Print outcomes properly
for key, worth in outcomes.gadgets():
if isinstance(worth, dict):
print(f" {key}: Precision={worth('precision'):.2f}, Recall={worth('recall'):.2f}, F1={worth('f1'):.2f}, Quantity={worth('quantity')}")
else:
print(f" {key}: {worth:.4f}")
besides ModuleNotFoundError:
print("Seqeval metric not put in. Run: pip set up seqeval")Ausgabe:
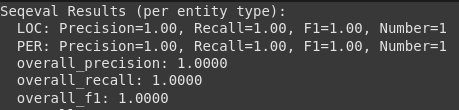
Erläuterung:
- Wir laden die seqevale Metrik.
- Es werden Hear der Hear entnommen, wobei jede innere Liste die Tags für einen Satz darstellt.
- Die Rechenmethode gibt detaillierte Werte für Präzisions-, Rückruf- und F1 -Ergebnisse für jeden identifizierten Entitätstyp (wie per für Particular person, LOC für den Standort) und Gesamtbewertungen zurück.
Textübersicht (Rouge)
Rouge (Rückruf-orientierte Zweitbesetzung für die Gisting-Bewertung) vergleicht eine generierte Zusammenfassung mit Referenzzusammenfassungen, wobei sich die Konzentration auf überlappende N-Gramm und die längsten häufigen Subsequenzen konzentriert.
import consider
def simple_summarizer(textual content):
"""A really fundamental summarizer - simply takes the primary sentence."""
attempt:
sentences = textual content.break up(".")
return sentences(0).strip() + "." if sentences(0).strip() else ""
besides:
return "" # Deal with empty or malformed textual content
# Load ROUGE metric
rouge_metric = consider.load("rouge")
# Instance textual content and reference abstract
textual content = "Immediately is a lovely day. The solar is shining and the birds are singing. I'm going for a stroll within the park."
reference = "The climate is nice as we speak."
# Generate abstract utilizing the straightforward perform
prediction = simple_summarizer(textual content)
print(f"Generated Abstract: {prediction}")
print(f"Reference Abstract: {reference}")
# Compute ROUGE scores
rouge_results = rouge_metric.compute(predictions=(prediction), references=(reference))
print(f"ROUGE Scores: {rouge_results}")Ausgabe:
Generated Abstract: Immediately is a lovely day.Reference Abstract: The climate is nice as we speak.
ROUGE Scores: {'rouge1': np.float64(0.4000000000000001), 'rouge2':
np.float64(0.0), 'rougeL': np.float64(0.20000000000000004), 'rougeLsum':
np.float64(0.20000000000000004)}
Erläuterung:
- Wir laden die Rouge -Metrik.
- Wir definieren einen simplen Zusammenfassung zur Demonstration.
- Berechnen berechnet verschiedene Rouge -Scores:
- Die Bewertungen näher an 1.0 zeigen eine höhere Ähnlichkeit mit der Referenzübersicht an. Die niedrigen Ergebnisse hier spiegeln die grundlegende Natur unseres Simple_Summarisators wider.
Frage Beantwortung (Kader)
Die Squad -Metrik wird für die Beantwortung von Benchmarks für extraktive Frage verwendet. Es berechnet die genaue Übereinstimmung (EM) und F1-Rating.
import consider
# Load the SQuAD metric
squad_metric = consider.load("squad")
# Instance predictions and references format for SQuAD
predictions = ({'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'})
references = ({'solutions': {'answer_start': (97), 'textual content': ('1976')}, 'id': '56e10a3be3433e1400422b22'})
outcomes = squad_metric.compute(predictions=predictions, references=references)
print(f"SQuAD Outcomes: {outcomes}")Ausgabe:

Erläuterung:
- Lädt die Kadermetrik.
- Nimmt Vorhersagen und Referenzen in einem bestimmten Wörterbuchformat, einschließlich des vorhergesagten Textes und der Grundwahrheit, mit ihren Startpositionen.
- exact_match: Prozentsatz der Vorhersagen, die genau mit einer der Grundwahrheitsantworten übereinstimmen.
- F1: Durchschnittlicher F1 -Punktzahl über alle Fragen, unter Berücksichtigung von teilweisen Übereinstimmungen auf Token -Ebene.
Erweiterte Bewertung mit der Evaluator -Klasse
Die Evaluator -Klasse optimiert den Prozess durch Integration von Modellbelastungen, Inferenz und Metrikberechnung. Es ist besonders nützlich für Standardaufgaben wie die Textklassifizierung.
# Notice: Requires transformers and datasets libraries
# pip set up transformers datasets torch # or tensorflow/jax
import consider
from consider import evaluator
from transformers import pipeline
from datasets import load_dataset
# Load a pre-trained textual content classification pipeline
# Utilizing a smaller mannequin for probably sooner execution
attempt:
pipe = pipeline("text-classification", mannequin="distilbert-base-uncased-finetuned-sst-2-english", gadget=-1) # Use CPU
besides Exception as e:
print(f"Couldn't load pipeline: {e}")
pipe = None
if pipe:
# Load a small subset of the IMDB dataset
attempt:
information = load_dataset("imdb", break up="take a look at").shuffle(seed=42).choose(vary(100)) # Smaller subset for velocity
besides Exception as e:
print(f"Couldn't load dataset: {e}")
information = None
if information:
# Load the accuracy metric
accuracy_metric = consider.load("accuracy")
# Create an evaluator for the duty
task_evaluator = evaluator("text-classification")
# Right label_mapping for IMDB dataset
label_mapping = {
'NEGATIVE': 0, # Map NEGATIVE to 0
'POSITIVE': 1 # Map POSITIVE to 1
}
# Compute outcomes
eval_results = task_evaluator.compute(
model_or_pipeline=pipe,
information=information,
metric=accuracy_metric,
input_column="textual content", # Specify the textual content column
label_column="label", # Specify the label column
label_mapping=label_mapping # Cross the corrected label mapping
)
print("nEvaluator Outcomes:")
print(eval_results)
# Compute with bootstrapping for confidence intervals
bootstrap_results = task_evaluator.compute(
model_or_pipeline=pipe,
information=information,
metric=accuracy_metric,
input_column="textual content",
label_column="label",
label_mapping=label_mapping, # Cross the corrected label mapping
technique="bootstrap",
n_resamples=10 # Use fewer resamples for sooner demo
)
print("nEvaluator Outcomes with Bootstrapping:")
print(bootstrap_results)Ausgabe:
Machine set to make use of cpuEvaluator Outcomes:
{'accuracy': 0.9, 'total_time_in_seconds': 24.277618517999997,
'samples_per_second': 4.119020155368932, 'latency_in_seconds':
0.24277618517999996}Evaluator Outcomes with Bootstrapping:
{'accuracy': {'confidence_interval': (np.float64(0.8703044820750653),
np.float64(0.9335706530476571)), 'standard_error':
np.float64(0.02412928142780514), 'rating': 0.9}, 'total_time_in_seconds':
23.871316319000016, 'samples_per_second': 4.189128017226537,
'latency_in_seconds': 0.23871316319000013}
Erläuterung:
- Wir laden eine Transformatoren -Pipeline für die Textklassifizierung und ein Beispiel des IMDB -Datensatzes.
- Wir erstellen einen Evaluator speziell für „Textklassifizierung“.
- Die Rechenmethode übernimmt die Fütterungsdaten (Textspalte) mit der Pipeline, das Abrufen von Vorhersagen, das Vergleich mit den True Labels (Beschriftungsspalte) mit der angegebenen Metrik und Anwendung des Label_Mapping.
- Es gibt die Metrikbewertung zusammen mit Leistungsstatistiken wie Gesamtzeit und Proben professional Sekunde zurück.
- Die Verwendung von Technique = ”Bootstrap” führt Resampling durch, um Konfidenzintervalle und Standardfehler für die Metrik abzuschätzen, was ein Gefühl für die Stabilität der Punktzahl gibt.
Verwenden von Bewertungssuiten
Evaluierungssuiten bündeln mehrere Bewertungen, die häufig auf bestimmte Benchmarks wie Klebstoff abzielen. Dies ermöglicht es, ein Modell gegen einen Standardaufgabensatz auszuführen.
# Notice: Working a full suite could be computationally intensive and time-consuming.
# This instance demonstrates the idea however may take a very long time or require vital assets.
# It additionally installs a number of datasets and will require particular mannequin configurations.
import consider
attempt:
print("nLoading GLUE analysis suite (this may obtain datasets)...")
# Load the GLUE activity immediately
# Utilizing "mrpc" for example activity, however you may select from the legitimate ones listed above
activity = consider.load("glue", "mrpc") # Specify the duty like "mrpc", "sst2", and so on.
print("Activity loaded.")
# Now you can run the duty on a mannequin (for instance: "distilbert-base-uncased")
# WARNING: This may take time for inference or fine-tuning.
# outcomes = activity.compute(model_or_pipeline="distilbert-base-uncased")
# print("nEvaluation Outcomes (MRPC Activity):")
# print(outcomes)
print("Skipping mannequin inference for brevity on this instance.")
print("Confer with Hugging Face documentation for full EvaluationSuite utilization.")
besides Exception as e:
print(f"Couldn't load or run analysis suite: {e}")Ausgabe:
Loading GLUE analysis suite (this may obtain datasets)...Activity loaded.
Skipping mannequin inference for brevity on this instance.
Confer with Hugging Face documentation for full EvaluationSuite utilization.
Erläuterung:
- Evaluationsuite.load lädt einen vordefinierten Satz von Bewertungsaufgaben (hier nur die MRPC -Aufgabe aus dem Klebstoff -Benchmark für die Demonstration).
- Der Befehl Suite.run („model_name“) würde das Modell in jedem Datensatz in der Suite normalerweise ausführen und die relevanten Metriken berechnen.
- Die Ausgabe ist normalerweise eine Liste von Wörterbüchern, die jeweils die Ergebnisse für eine Aufgabe in der Suite enthalten. (HINWEIS: Dies erfordert häufig spezifische Umgebungsumstellungen und eine erhebliche Berechnung.)
Visualisierung der Bewertungsergebnisse
Visualisierungen helfen dabei, mehrere Modelle über verschiedene Metriken hinweg zu vergleichen. Dafür sind Radardiagramme wirksam.
import consider
import matplotlib.pyplot as plt # Guarantee matplotlib is put in
from consider.visualization import radar_plot
# Pattern information for a number of fashions throughout a number of metrics
# Decrease latency is healthier, so we would invert it or think about it individually.
information = (
{"accuracy": 0.99, "precision": 0.80, "f1": 0.95, "latency_inv": 1/33.6},
{"accuracy": 0.98, "precision": 0.87, "f1": 0.91, "latency_inv": 1/11.2},
{"accuracy": 0.98, "precision": 0.78, "f1": 0.88, "latency_inv": 1/87.6},
{"accuracy": 0.88, "precision": 0.78, "f1": 0.81, "latency_inv": 1/101.6}
)
model_names = ("Mannequin A", "Mannequin B", "Mannequin C", "Mannequin D")
# Generate the radar plot
# Larger values are typically higher on a radar plot
attempt:
# Generate radar plot (make sure you go an accurate format and that information is legitimate)
plot = radar_plot(information=information, model_names=model_names)
# Show the plot
plt.present() # Explicitly present the plot, is perhaps essential in some environments
# To save lots of the plot to a file (uncomment to make use of)
# plot.savefig("model_comparison_radar.png")
plt.shut() # Shut the plot window after displaying/saving
besides ImportError:
print("Visualization requires matplotlib. Run: pip set up matplotlib")
besides Exception as e:
print(f"Couldn't generate plot: {e}")Ausgabe:
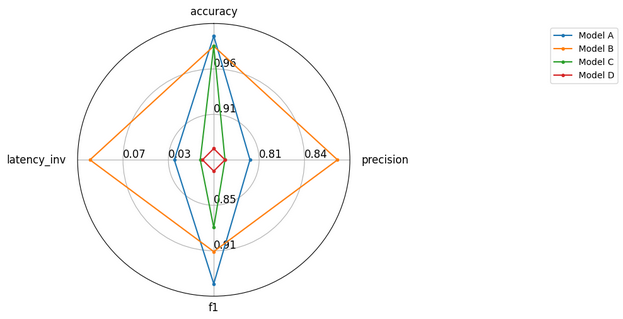
Erläuterung:
- Wir bereiten die Probenergebnisse für vier Modelle über Genauigkeit, Präzision, F1 und umgekehrte Latenz vor (so höher ist besser).
- Radar_Plot erstellt ein Diagramm, bei dem jede Achse eine Metrik darstellt und zeigt, wie Modelle visuell vergleichen.
Bewertungsergebnisse sparen
Sie können Ihre Bewertungsergebnisse in einer Datei, häufig im JSON-Format, zur Aufzeichnung oder späteren Analyse speichern.
import consider
from pathlib import Path
# Carry out an analysis
accuracy_metric = consider.load("accuracy")
end result = accuracy_metric.compute(references=(0, 1, 0, 1), predictions=(1, 0, 0, 1))
print(f"Consequence to save lots of: {end result}")
# Outline hyperparameters or different metadata
hyperparams = {"model_name": "my_custom_model", "learning_rate": 0.001}
run_details = {"experiment_id": "run_42"}
# Mix outcomes and metadata
save_data = {**end result, **hyperparams, **run_details}
# Outline save listing and filename
save_dir = Path("./evaluation_results")
save_dir.mkdir(exist_ok=True) # Create listing if it would not exist
# Use consider.save to retailer the outcomes
attempt:
saved_path = consider.save(save_directory=save_dir, **save_data)
print(f"Outcomes saved to: {saved_path}")
# You may also manually save as JSON
import json
manual_save_path = save_dir / "manual_results.json"
with open(manual_save_path, 'w') as f:
json.dump(save_data, f, indent=4)
print(f"Outcomes manually saved to: {manual_save_path}")
besides Exception as e:
# Catch potential git-related errors if run outdoors a repo
print(f"consider.save encountered a problem (presumably git associated): {e}")
print("Making an attempt guide JSON save as an alternative.")
import json
manual_save_path = save_dir / "manual_results_fallback.json"
with open(manual_save_path, 'w') as f:
json.dump(save_data, f, indent=4)
print(f"Outcomes manually saved to: {manual_save_path}")Ausgabe:
Consequence to save lots of: {'accuracy': 0.5}consider.save encountered a problem (presumably git associated): save() lacking 1
required positional argument: 'path_or_file'
Making an attempt guide JSON save as an alternative.
Outcomes manually saved to: evaluation_results/manual_results_fallback.json
Erläuterung:
- Wir kombinieren das Pc -Ergebnis -Wörterbuch mit anderen Metadaten wie Hyperparamen.
- consider.save versucht, diese Daten im angegebenen Verzeichnis in einer JSON -Datei zu speichern. Es könnte versuchen, hinzuzufügen Git Commit Informationen, wenn Sie in einem Repository ausgeführt werden, was sonst zu Fehlern führen kann (wie im ursprünglichen Protokoll angezeigt).
- Wir fügen einen Fallback hinzu, um das Wörterbuch manuell als JSON -Datei zu retten, was häufig ausreicht.
Auswahl der richtigen Metrik
Die Auswahl der entsprechenden Metrik ist entscheidend. Betrachten Sie diese Punkte:
- Aufgabentyp: Ist es Klassifizierung, Übersetzung, Zusammenfassung, Ner, QA? Verwenden Sie den Metrikenstandard für diese Aufgabe (Genauigkeit/F1 für die Klassifizierung, Bleu/Rouge für die Era, SEQEVAL FÜR NER, KAPPE FÜR QA).
- Datensatz: Einige Benchmarks (wie Kleber, Kader) haben spezifische zugehörige Metriken. Ranglisten (z. B. auf Papieren mit Code) zeigen häufig häufig verwendete Metriken für bestimmte Datensätze.
- Ziel: Welcher Aspekt der Leistung ist am wichtigsten?
- Genauigkeit: Gesamt Korrektheit (intestine für ausgewogene Klassen).
- Präzision/Rückruf/F1: Wichtig für unausgewogene Klassen oder wenn falsch optimistic Aspekte/Adverse unterschiedliche Kosten haben.
- Bleu/Rouge: Fließende und Inhaltsüberlappung in der Textgenerierung.
- Verwirrung: Wie intestine ein Sprachmodell eine Probe vorhersagt (niedriger ist besser, oft für generative Modelle verwendet).
- Metrische Karten: Lesen Sie die umarmenden Gesichtskarten (Dokumentation) für detaillierte Erklärungen, Einschränkungen und angemessene Anwendungsfälle (z. B., z. BleukarteAnwesend Kaderkarte).
Abschluss
Die Umarmungsgesichts-Evaluieren-Bibliothek bietet eine vielseitige und benutzerfreundliche Methode zur Beurteilung von großsprachigen Modellen und Datensätzen. Es bietet Standardmetriken, Datensatzmessungen und Instruments wie die Bewerter Und Bewertungen Um den Prozess zu optimieren. Durch die Verwendung dieser Instruments und die Auswahl von Metriken, die für Ihre Aufgabe geeignet sind, können Sie klare Einblicke in die Stärken und Schwächen Ihres Modells erhalten.
Weitere Informationen und fortgeschrittene Nutzung erhalten Sie in den offiziellen Ressourcen:
Harsh Mishra ist ein KI/ML -Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit tatsächlichen Menschen. Leidenschaft über Genai, NLP und Maschinen schlauer (damit sie ihn noch nicht ersetzen). Wenn er Fashions nicht optimiert, optimiert er wahrscheinlich seine Kaffeeaufnahme. 🚀☕
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.