

# Einführung
Ich weiß, dass die Dinge zunächst einfach erscheinen, wenn Anfänger anfangen, maschinelles Lernen zu erlernen. Sie folgen einem Tutorial, in dem Sie aufgefordert werden, einen Datensatz zu laden und ein Modell zu trainieren, und dann sehen Sie etwa Folgendes: loss = "mse" oder criterion = nn.CrossEntropyLoss().
Und schon beginnt das Tutorial, über Gleichungen, Verläufe, Optimierung und griechische Buchstaben zu sprechen. Wenn Sie jemals mitgenickt haben, ohne wirklich zu verstehen, was eine Verlustfunktion bewirkt, sind Sie nicht allein. Verlustfunktionen werden oft rückwärts erklärt. Die meisten Tutorials beginnen mit der Formel, obwohl sie mit der Idee beginnen sollten. Dieser Artikel ist Teil meiner Noob-Serie, in der ich Ihnen das Verständnis erleichtern werde. Additionally, fangen wir an.
# Was ist eine Verlustfunktion?
Eine Verlustfunktion gibt an, wie ein Modell für maschinelles Lernen weiß, wie falsch es ist. Das ist buchstäblich das ganze Konzept. Das Modell macht eine Vorhersage. Die Verlustfunktion vergleicht diese Vorhersage mit der richtigen Antwort. Dann gibt es dem Modell eine Zahl, die besagt: „So schlimm battle Ihr Fehler.“
A hoher Verlust bedeutet, dass das Modell battle sehr falsch.
A geringer Verlust bedeutet, dass das Modell battle schließen.
Während des Trainings passt sich das Modell ständig an, um den Verlust zu verringern.
So geschieht Lernen. Wenn Sie ein Dartspiel gespielt haben, ist es sehr ähnlich. Du wirfst den Pfeil. Um sich zu verbessern, brauchen Sie Suggestions. Sie müssen wissen, ob Ihr Pfeil etwas daneben, zu weit weg, zu hoch oder zu weit hyperlinks battle. Ohne dieses Suggestions können Sie sich nicht verbessern. Das Bullauge ist additionally grundsätzlich die richtige Antwort und der Pfeil die Vorhersage. Sie messen den Abstand zwischen dem Pfeil und dem Bullseye. Die Verlustfunktion misst, wie weit entfernt der Pfeil gelandet ist. Dieser Abstand wird zum Feedbacksignal des Modells. So würde es aussehen, wenn Sie eine Visualisierung bevorzugen.
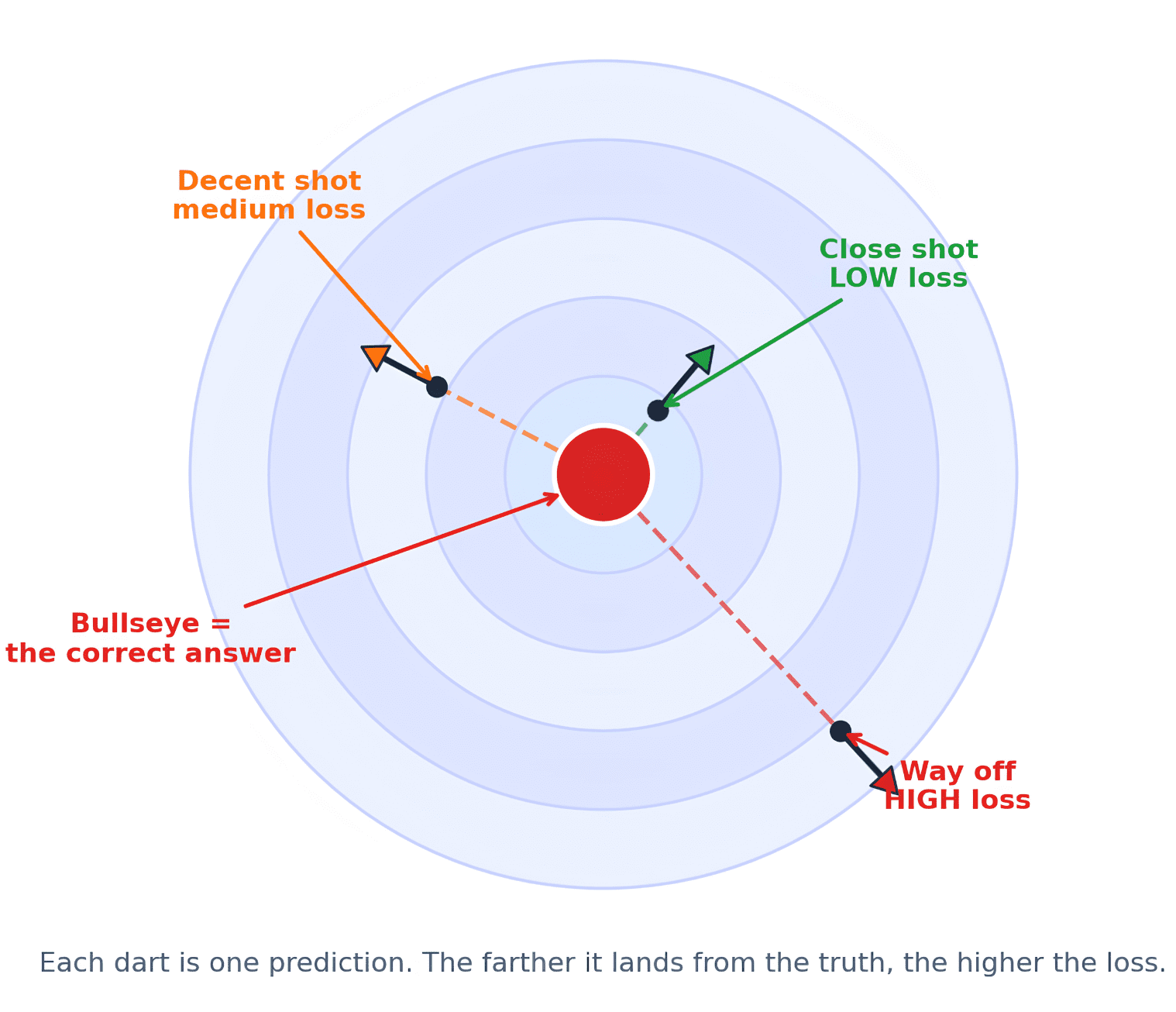
Genauso wie der Abstand zur Mitte wichtig ist, ist ein zu großer Abstand nicht gleichbedeutend mit einem weit entfernten Wurf. Ebenso reicht es bei Modellen nicht aus, nur zu wissen, dass die Antwort falsch ist. Um sich zu verbessern, muss das Modell wissen, wie stark es versagt hat.
Nachdem wir nun verstanden haben, was eine Verlustfunktion ist und warum wir sie brauchen, schauen wir uns einige davon an Häufige Verlustfunktionen, die beim maschinellen Lernen verwendet werden.
# Mittlerer quadratischer Fehler
Der häufigste Verlust bei der Vorhersage von Zahlen ist der mittlere quadratische Fehler (MSE). Es wird häufig verwendet, wenn das Modell Zahlen wie Immobilienpreise, Temperaturen oder Lieferzeiten vorhersagt. Die Idee ist sehr einfach.
- Fehler: Berücksichtigen Sie für jede Vorhersage die Lücke zwischen der Vermutung und der Wahrheit.
- Kariert: Multiplizieren Sie jede Lücke mit sich selbst.
- Bedeuten: Berechnen Sie den Durchschnitt aller quadratischen Lücken.
Sie können es in Python wie folgt schreiben:
def mean_squared_error(predictions, actuals):
squared_errors = ((p - a) ** 2 for p, a in zip(predictions, actuals))
return sum(squared_errors) / len(squared_errors)Nun weiß ich, dass es intuitiv sinnvoll ist, die Fehler zu nehmen und dann einen Mittelwert über die Vorhersagen zu bilden, aber zu verstehen, warum wir sie quadrieren, kann verwirrend sein. Dies geschieht aus zwei Gründen:
- Durch die Quadrierung wird jeder Fehler positiv. Ein Fehler von +3 und ein Fehler von -3 sind gleich schlimm, und durch Quadrieren werden beide zu 9, sodass sie sich nicht mehr gegenseitig aufheben.
- Beim Quadrieren werden große Fehler viel härter bestraft als kleine. Das ist für viele Anwendungsfälle intestine. Wenn Sie beispielsweise Immobilienpreise vorhersagen, sollte ein Fehler von 1.000 $ gegenüber 200.000 $ entsprechend bestraft werden.
# Mittlerer absoluter Fehler
Eine weitere häufige Verlustfunktion ist der mittlere absolute Fehler (MAE). MAE misst auch die Lücke zwischen Vorhersagen und tatsächlichen Werten, quadriert den Fehler jedoch nicht. Stattdessen, es nimmt einfach den absoluten Wert an.
Hier ist die Python-Funktion zum Schreiben:
def mean_absolute_error(predictions, actuals):
absolute_errors = (abs(p - a) for p, a in zip(predictions, actuals))
return sum(absolute_errors) / len(absolute_errors)Es bestraft additionally große Fehler, aber nicht so hart wie MSE.
- Ein Fehler von 10 kostet 10 und ein Fehler von 20 kostet 20.
- Wenn Ihre Daten von Natur aus einige Ausreißer aufweisen und Sie nicht möchten, dass Ihr Modell überreagiert, ist MAE eine gute Wahl.
Lassen Sie mich eine kurze Grafik zeigen, die die MSE- und MAE-Kurven vergleicht.

# Kreuzentropieverlust
Bisher haben wir über die Vorhersage von Zahlen gesprochen. Bei vielen Problemen des maschinellen Lernens geht es jedoch um die Vorhersage von Kategorien.
Handelt es sich bei dieser E-Mail um Spam oder nicht?
Ist das ein Bild einer Katze, eines Hundes oder eines Fisches?
Ist eine bestimmte Transaktion betrügerisch oder nicht?
Für Klassifizierungsaufgaben geben Modelle normalerweise Wahrscheinlichkeiten aus wie:
Canine: 70%
Cat: 20%
Fish: 10%Wenn es sich bei dem Bild tatsächlich um einen Hund handelt, ist das eine gute Vorhersage. Wenn es sich jedoch um eine Katze handelt, muss das Modell dafür bestraft werden, dass es der richtigen Antwort eine geringere Wahrscheinlichkeit zuordnet.
Die Instinct ist additionally:
- Korrekt und sicher – geringer Verlust
- Richtig, aber unsicher – mittlerer Verlust
- Falsch und zuversichtlich – hoher Verlust
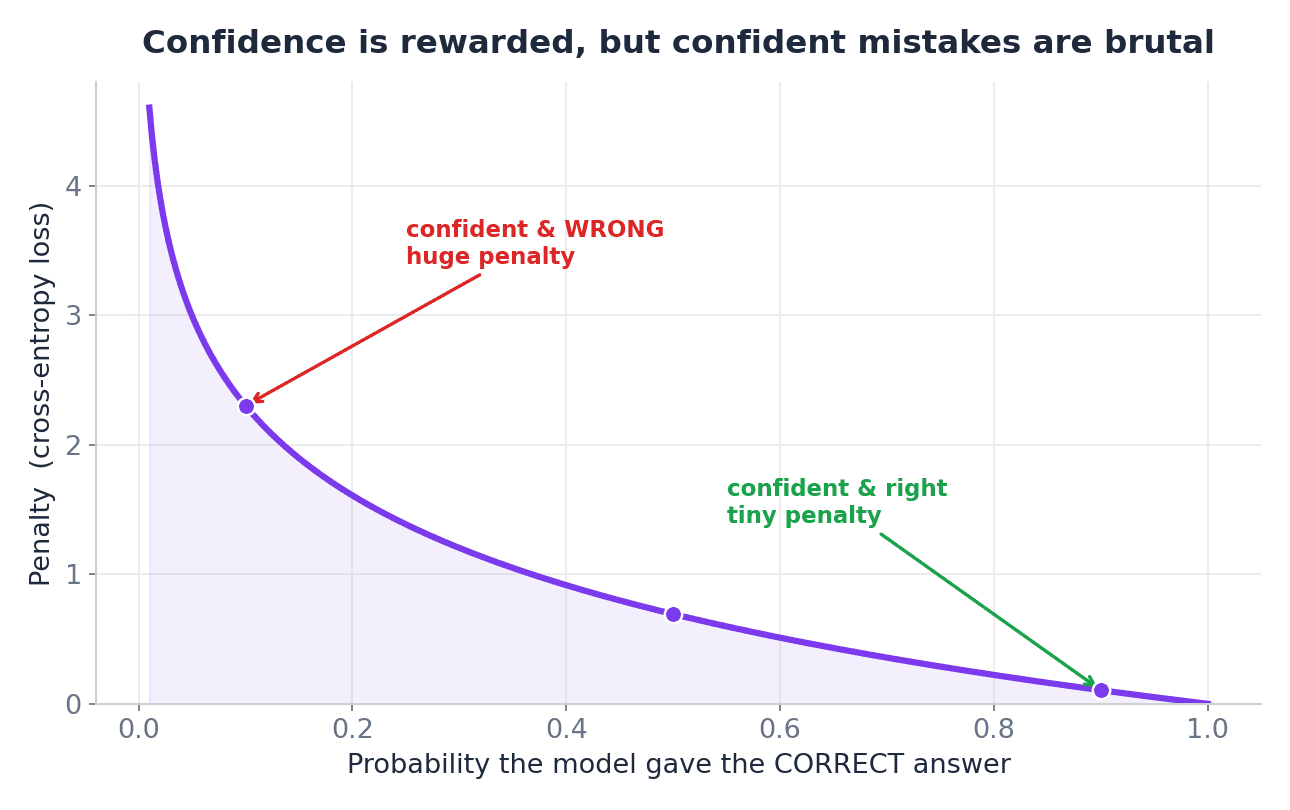
Aus diesem Grund wird die Kreuzentropie so häufig zur Klassifizierung verwendet. Es kommt nicht nur darauf an, ob das Modell richtig battle. Es kommt auch darauf an, wie sicher das Modell battle.
# Verlust vs. Genauigkeit
Nachdem wir nun verschiedene Verlustfunktionen durchgegangen sind, möchte ich auch den Unterschied zwischen Verlust und Genauigkeit klären. Sie sind nicht dasselbe.
Genauigkeit sagt es dir wie viele Vorhersagen richtig waren.
Aber Verlust sagt es dir wie schlimm die Fehler des Modells waren.
Wenn Sie zwei Modelle haben – Modell A und Modell B – und beide 90 von 100 Vorhersagen richtig machen, haben sie die gleiche Genauigkeit. Aber ein Modell kann bei den richtigen Antworten sehr sicher sein und bei den falschen nur leicht falsch liegen, während das andere bei vielen Beispielen kaum richtig und bei falschen Antworten äußerst sicher sein kann.
In diesem Fall wäre die Genauigkeit gleich, aber der Verlust wäre unterschiedlich.
# Die Trainingsschleife
Sobald das Modell eine Verlustzahl hat, kann es verbessert werden. Die Trainingsschleife sieht so aus:
- Das Modell macht Vorhersagen.
- Die Verlustfunktion misst die Fehler.
- Der Optimierer aktualisiert das Modell.
- Das Modell versucht es erneut.
- Der Verlust wird hoffentlich kleiner.
Beim Coaching eines Modells zeichnen wir auch den Verlust über die Zeit auf. Am Anfang macht das Modell viele Fehler und kann schlecht Vorhersagen treffen, sodass der Verlust hoch ist. Mit fortschreitendem Coaching nimmt der Verlust jedoch ab und das Modell kann besser Vorhersagen treffen.
Eine gesunde Trainingskurve sieht oft so aus:
Hoher Verlust am Anfang → starker Abfall → allmähliche Abflachung
wie Sie in der Abbildung unten sehen können.

Die Abflachung ist regular. Das bedeutet, dass das Modell die einfachen Muster gelernt hat und nun kleinere Verbesserungen vornimmt. Aber wenn der Trainingsverlust sinkt, während der Validierungsverlust zu steigen beginnt, kann das ein Warnsignal sein Überanpassung – was bedeutet, dass das Modell möglicherweise die Trainingsdaten speichert, anstatt verallgemeinernde Muster zu lernen.
# Letzte Gedanken
Eine Verlustfunktion ist die Fehlerbewertung des Modells.
Es teilt dem Modell mit, wie falsch seine Vorhersagen sind, und gibt dem Coaching ein klares Ziel vor: diese Zahl zu verringern.
Sobald Sie Verlustfunktionen verstanden haben, werden viele andere Ideen des maschinellen Lernens leichter zu verstehen – einschließlich Gradientenabstieg, Backpropagation, Optimierung, Überanpassung und Bewertungsmetriken.
Sie müssen nicht mit gruseligen Gleichungen beginnen. Beginnen Sie mit der Idee:
- Das Modell vermutet.
- Die Verlustfunktion bewertet die Schätzung.
- Das Modell aktualisiert sich selbst, um die Punktzahl zu reduzieren.
Das ist das Herzstück des maschinellen Lernens.
Verlust ist, wie ein Modell weiß, dass es falsch ist.
Durch Coaching lernt man, weniger falsch zu liegen.
Damit sind wir am Ende dieses Artikels angelangt. Wir werden in unserer Noob-Serie weiterhin einige interessante Konzepte behandeln.
Kanwal Mehreen ist ein Ingenieur für maschinelles Lernen und ein technischer Redakteur mit einer großen Leidenschaft für Datenwissenschaft und die Schnittstelle zwischen KI und Medizin. Sie ist Mitautorin des E-Books „Maximizing Productiveness with ChatGPT“. Als Google Era Scholar 2022 für APAC setzt sie sich für Vielfalt und akademische Exzellenz ein. Sie ist außerdem als Teradata Range in Tech Scholar, Mitacs Globalink Analysis Scholar und Harvard WeCode Scholar anerkannt. Kanwal ist ein leidenschaftlicher Verfechter von Veränderungen und hat FEMCodes gegründet, um Frauen in MINT-Bereichen zu stärken.