

# Einführung
Ausbildung a Modell für maschinelles Lernen Und die Beobachtung des Rückgangs des Verlusts ist ein Gefühl des Fortschritts, bis die Validierungsgenauigkeit ein Plateau erreicht oder der Verlust zu steigen beginnt und Sie nicht sicher sind, was ihn verursacht hat. An diesem Punkt fügen die meisten Leute mehr Protokollierung hinzu oder beginnen mit der Optimierung von Hyperparametern, in der Hoffnung, dass sich etwas ändert. Was die meisten Analysten in dieser Section übersehen, ist die tatsächliche Einsicht in die Vorgänge im Modell während des Trainings. Visuelle Debugging-Instruments können in dieser Section nützliche Erkenntnisse liefern.
In diesem Artikel behandeln wir drei Themen: Was während des Trainings visualisiert werden soll (Verläufe, Verluste und Einbettungen), die Instruments, die diese Visualisierungen bereitstellen (TensorBoard und seine Hauptalternativen) und die Methoden zur direkten Erfassung von Modellberechnungen mithilfe von Hooks und Haltepunkten.
# Visualisierung von Verläufen, Verlusten und Einbettungen
// Verlustkurven
Beim Coaching eines Modells wird normalerweise zuerst die Verlustkurve überprüft. Wenn sowohl der Trainingsverlust als auch der Validierungsverlust abnehmen und nahe beieinander bleiben, deutet dies darauf hin, dass das Coaching intestine voranschreitet. Wenn der Validierungsverlust zu steigen beginnt, während der Trainingsverlust weiter sinkt, liegt eine Überanpassung des Modells vor. Wenn beide Kurven früh ein Plateau erreichen, lernt das Modell nicht, was normalerweise auf ein Downside mit den Daten oder der Lernrate hinweist.
Darüber hinaus ist auch der Gradientenfluss wichtig. Das Downside des verschwindenden Gradienten kann sich in der Praxis manifestieren, wenn die Verlustkurven gleichmäßig, aber zu langsam abfallen, was darauf hindeutet, dass die Gradienten zu klein sind, wenn sie frühe Schichten erreichen.
Das unten gezeigte Diagramm simuliert ein typisches Überanpassungsmuster. Beide Verluste nehmen in den ersten zehn Epochen zusammen ab, und dann beginnt der Validierungsverlust zuzunehmen, während der Trainingsverlust weiter sinkt.
Die rot gepunktete Linie markiert, wo die Divergenz beginnt: In einem echten Lauf ist das der Punkt, an dem man mit der Untersuchung der Regularisierung oder des frühen Stoppens beginnen sollte.
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
mannequin = nn.Sequential(nn.Linear(16, 16), nn.Tanh(),
nn.Linear(16, 16), nn.Tanh(),
nn.Linear(16, 1))
grad_magnitudes = {}
def grad_hook(identify):
def hook(module, grad_input, grad_output):
grad_magnitudes(identify) = grad_output(0).abs().imply().merchandise()
return hook
for i, layer in enumerate(mannequin):
layer.register_backward_hook(grad_hook(f"Layer {i}"))
output = mannequin(torch.randn(32, 16))
output.imply().backward()
plt.bar(grad_magnitudes.keys(), grad_magnitudes.values())
plt.title("Imply Gradient Magnitude per Layer")
plt.ylabel("Imply |gradient|")
plt.xticks(rotation=15)
plt.tight_layout()
plt.present()Es wird ausgegeben:
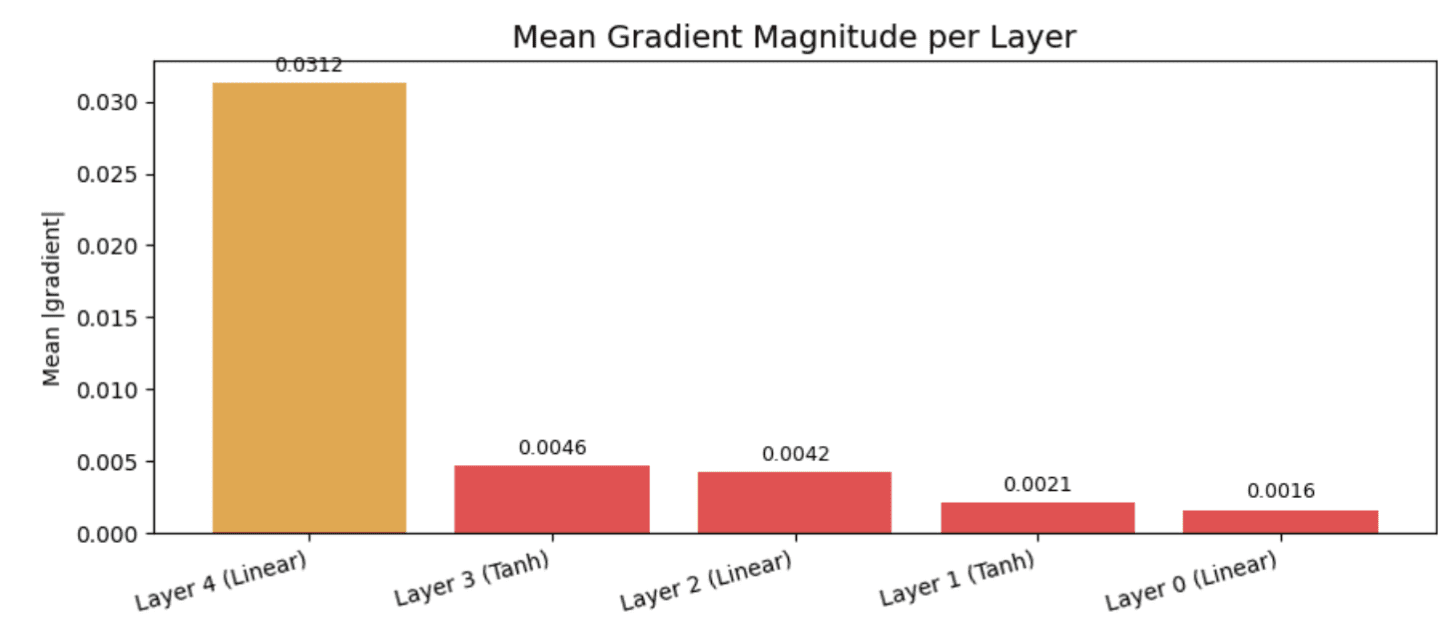
// Rohgradientengrößen
Layer 4 (Linear): 0.031250
Layer 3 (Tanh): 0.004646
Layer 2 (Linear): 0.004241
Layer 1 (Tanh): 0.002126
Layer 0 (Linear): 0.001631Das Diagramm lautet von rechts nach hyperlinks: Schicht 4 stellt die Ausgabeschicht dar und Schicht 0 ist die erste. Die Ausgabeebene erhält einen Gradienten von 0,031, aber bis sie Ebene 0 erreicht, ist dieser Wert auf 0,0016 gesunken – etwa 20-mal kleiner.
Der rote Balken, der auf jeder der ersten drei Ebenen erscheint, zeigt an, dass sich die Steigungen bereits in der Risikozone befinden, bevor sie überhaupt den Anfang des Netzwerks erreichen. Bei einem echten Trainingslauf auf einem tieferen Modell würden diese ersten Schichten ihre Gewichte so langsam anpassen, dass sie kaum etwas lernen würden.
Dies ist ein praktisches Beispiel für das Downside des verschwindenden Gradienten: Die frühen Schichten werden stillschweigend untertrainiert, was ohne diese Artwork von Diagramm nicht sichtbar ist.
// Gradientenvisualisierung
Die schichtweise Darstellung der Gradientengrößen während des Trainings gibt einen direkten Überblick darüber, ob die Gradienten die frühen Teile des Netzwerks mit beträchtlichen Werten erreichen. In tiefen Modellen können Farbverläufe verschwinden, wenn sie sich rückwärts durch die Schichten bewegen. Die während des Trainings aufgezeichneten Gradientenwerthistogramme für jede Schicht können dieses Muster aufdecken und uns dabei helfen, das Downside frühzeitig zu erkennen.
PyTorch‚S register_backward_hook Mit der Funktion können wir Gradiententensoren aus jeder Ebene erhalten, ohne die Trainingsschleife zu ändern. Wir verbinden einen Hook mit einem Modul, das bei jedem Rückwärtsdurchlauf aktiviert wird und die Gradiententensoren an einen angegebenen Rückruf sendet.
Das folgende Histogramm zeigt die vollständige Verteilung der Gradientenwerte für jede Ebene nach einem Rückwärtsdurchlauf. Jede Unterhandlung stellt eine einzelne Ebene dar, geordnet von der ersten bis zur letzten Ebene.
Der Code hierfür ist zu finden Hier.
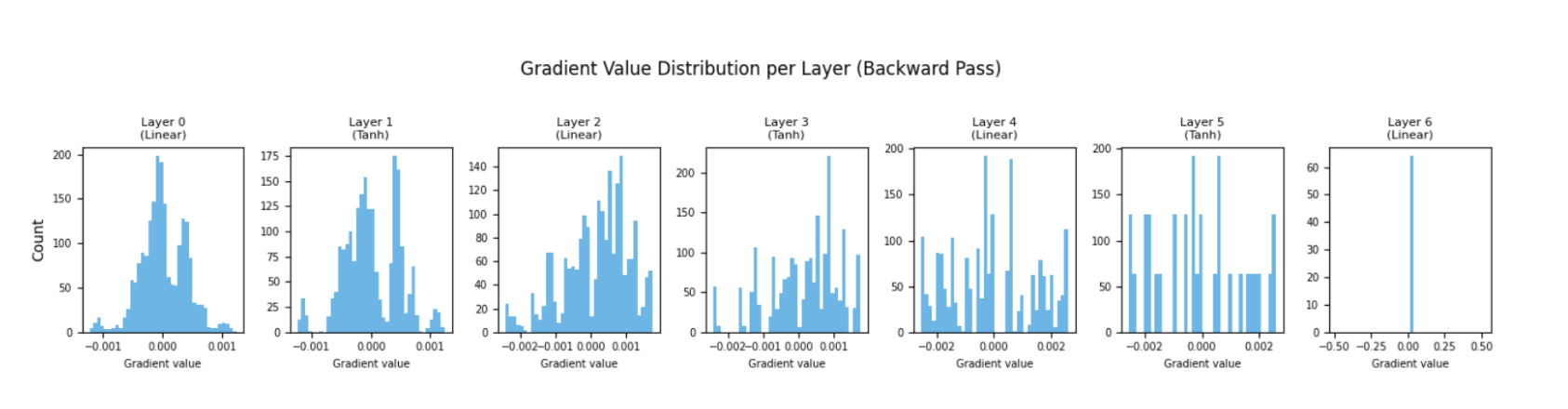
Was wir in einem gesunden Netzwerk suchen, sind Histogramme über Schichten hinweg mit ungefähr ähnlichen Spreads.
Wenn die frühen Schichten eine sehr schmale, spitzenartige Verteilung aufweisen, die eng bei Null zentriert ist, könnte das ein Warnsignal für verschwindende Gradienten sein.
Die Farbverläufe existieren immer noch, aber sie sind so klein, dass sie quick keine Lerninformationen enthalten. Diese Visualisierung kann uns helfen, dieses Muster bereits nach den ersten paar Chargen zu erkennen, und nicht erst nach einem vollständigen Trainingslauf.
// Einbettungen
Wenn ein Modell Eingaben einer erlernten Darstellung zuordnet, verrät uns die Visualisierung dieser Darstellung, ob das Modell die Daten wie erwartet trennt. Der gebräuchlichste Ansatz besteht darin, die Einbettungen einem trainierten (oder teilweise trainierten) Modell zu entnehmen und ihre Dimensionalität mithilfe von zu reduzieren t-SNE oder UMAPund plotten Sie sie mit Klassenbezeichnungen als Farben.
Wenn die Klassen eng und intestine getrennt sind, bedeutet das, dass das Modell eine sinnvolle Trennung gelernt hat. Überlappende Klassen bedeuten, dass das Modell die Konzepte noch nicht getrennt hat. Dieser Schritt ist nützlich zum Debuggen von Modellen, die auf Textual content oder Bildern trainiert wurden, bevor die endgültige Klassifizierungsebene hinzugefügt wird.
# TensorBoard und seine Alternativen
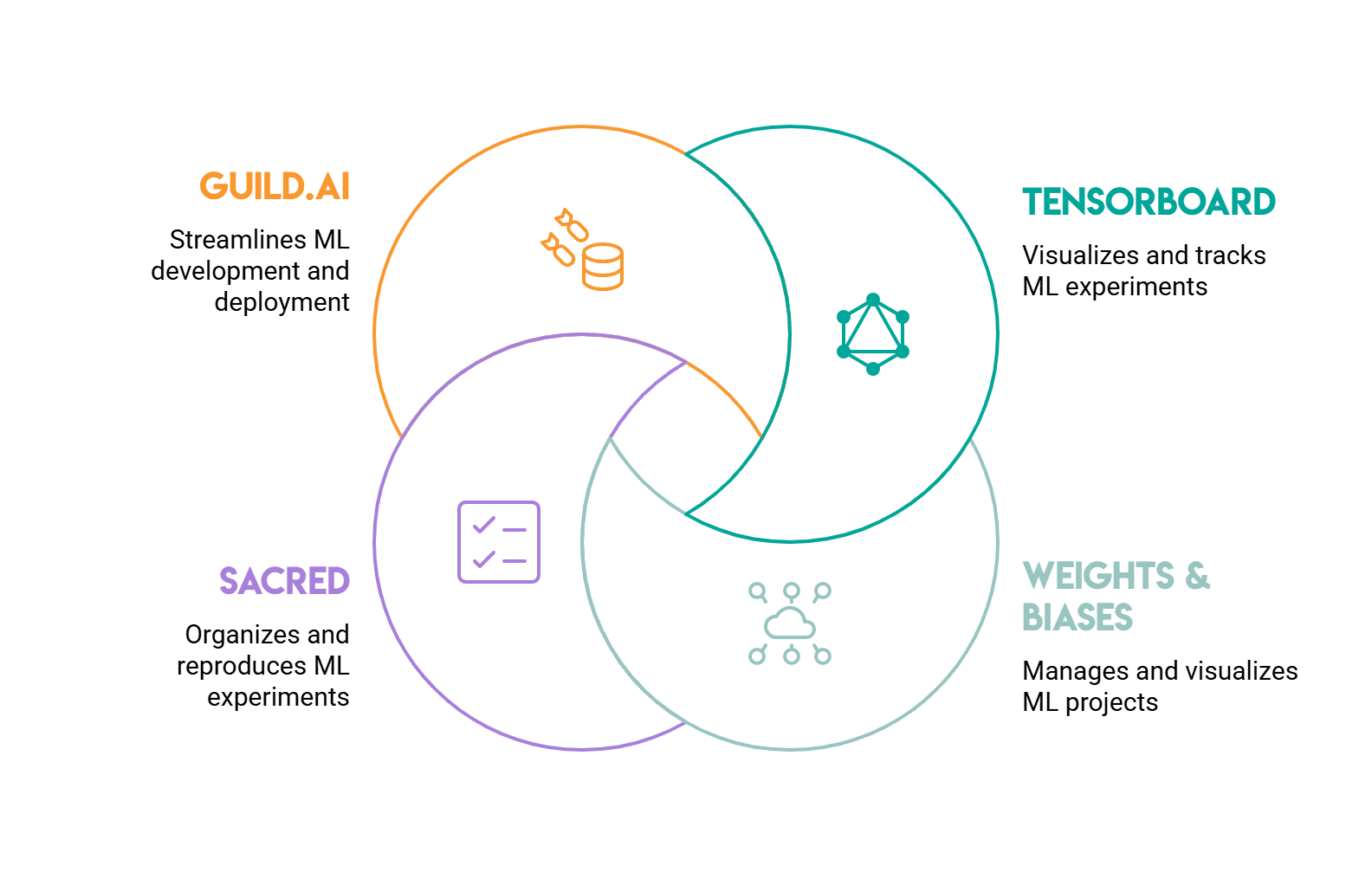
// TensorBoard
TensorBoard ist Ihr Standardstartpunkt. Ursprünglich gebaut für TensorFlowes funktioniert mit PyTorch durch torch.utils.tensorboard. Die Daten können über a protokolliert werden SummaryWriter Objekt, und Sie können die Ergebnisse in einer Browser-Registerkarte anzeigen. Es verarbeitet Skalare (Verlust, Genauigkeit), Histogramme (Gewichts- und Gradientenverteilungen), Bilder und einen Einbettungsprojektor zur Visualisierung hochdimensionaler Darstellungen.
Die Hauptbeschränkung ist die Lokalität. Um Ihre Ergebnisse mit einem Staff zu teilen, müssen Sie einen gemeinsamen Speicher für Protokolldateien einrichten oder TensorBoard.dev verwenden, dessen Unterstützung begrenzt ist.
// Gewichte und Voreingenommenheiten
Gewichte und Voreingenommenheiten (W&B) wird von den meisten maschinellen Lernteams für die Zusammenarbeit oder eine detailliertere Nachverfolgung verwendet.
Die Einrichtung erfolgt mit zwei Zeilen: wandb.init() zu Beginn eines Laufs und wandb.log() innerhalb der Trainingsschleife. Alles wird automatisch mit einem Cloud-Dashboard synchronisiert und die Ausführungen werden nach Projekt gruppiert, was den Vergleich von Experimenten vereinfacht.
Sehen Sie sich den folgenden Codeausschnitt an:
import wandb
wandb.init(venture="my-model", config={"lr": 0.001, "epochs": 20, "batch_size": 32})
for epoch in vary(wandb.config.epochs):
train_loss = 1 / (1 + 0.3 * epoch) # simulated
val_loss = train_loss + max(0, 0.04 * (epoch - 10)) # simulated
wandb.log({"epoch": epoch, "train_loss": train_loss, "val_loss": val_loss})
wandb.end()Sobald der Lauf abgeschlossen ist, können die protokollierten Metriken im W&B-Dashboard zusammen mit der Konfiguration, die sie erzeugt hat, angezeigt werden. Der Vergleich zweier Läufe mit unterschiedlichen Parametern kann einfach durch Auswahl in der Benutzeroberfläche durchgeführt werden, ohne dass eine manuelle Protokollanalyse erforderlich ist.
W&B unterstützt auch Hyperparameter-Sweeps mit integrierter Visualisierung, die zeigt, welche Hyperparameter das Ergebnis am meisten beeinflusst haben.
Systemmetriken wie GPU-Auslastung und Speichernutzung werden ebenfalls automatisch protokolliert. Für Groups, die viele Experimente parallel durchführen, entfällt durch den gemeinsamen Arbeitsbereich ein Großteil des manuellen Aufwands, den Überblick über die Versuche zu behalten.
// Heilig
Heilig verfolgt einen anderen Ansatz. Es konzentriert sich eher auf Reproduzierbarkeit als auf Visualisierung. Wir kommentieren ein Trainingsskript mit dem Experiment Decorator von Sacred, das die gesamte Konfiguration, alle während der Laufzeit vorgenommenen Änderungen und alle aufgezeichneten Metriken in einer Datenbank (normalerweise MongoDB) aufzeichnet. So wird jeder Lauf und seine genauen Einstellungen zu einer dauerhaften Aufzeichnung.
Für den Visualisierungsteil wird Sacred mit Frontends wie Omniboard oder Sacredboard kombiniert. Dies erhöht die Komplexität im Vergleich zu TensorBoard oder W&B, aber die Stärke liegt in der Überprüfbarkeit: Jeder Lauf aus der Vergangenheit kann genau so reproduziert werden, wie er konfiguriert wurde.
// Guild.ai
Guild.ai funktioniert über die Befehlszeile und erfordert keine Änderung des Trainingscodes. Wir führen ein Trainingsskript über Guild aus guild run practice.pydas alle vom Skript erstellten Protokolle zusammen mit allen Ausgabedateien aufzeichnet und sie mit dieser bestimmten Ausführung verknüpft. Metriken und Laufvergleiche sind über die Befehlszeilenschnittstelle (CLI) von Guild oder die lokale Benutzeroberfläche verfügbar.
Dieses Framework ist eine gute Wahl, wenn Sie mit vorhandenen Skripten oder Code von Drittanbietern arbeiten, den wir lieber nicht ändern möchten. Es bietet weniger Funktionen als W&B, aber die Einrichtungskosten sind auch geringer.
# Verwendung von Haltepunkten und Hooks für maschinelle Lernberechnungen
// Vorwärts- und Rückwärtshaken
Mit dem Hook-System von PyTorch können wir Berechnungen an jedem Punkt im Vorwärts- oder Rückwärtsdurchlauf eines Modells abfangen. Der register_forward_hook Die Funktion fügt einen Rückruf an eine beliebige Ebene an und wird jedes Mal ausgelöst, wenn diese Ebene einen Stapel verarbeitet. Der Rückruf erfasst die Eingabe- und Ausgabetensoren der Ebene, die wir dann protokollieren, auf NaN-Werte prüfen oder grafisch darstellen können.
Der register_backward_hook Die Funktion macht dasselbe für den Rückwärtsdurchlauf und gibt uns Zugriff auf die Gradiententensoren, die durch jede Schicht fließen. Zusammen decken diese beiden Hooks den Großteil dessen ab, was wir während des Trainings überprüfen möchten, ohne die Modelldefinition oder die Trainingsschleife zu ändern.
Eine praktische Anwendung ist die Erkennung von NaN-Werten. Ein Vorwärtshaken, der auswertet tensor.isnan().any() Bei der Ausgabe jeder Ebene wird numerische Instabilität sofort erkannt und verhindert, dass sie sich ausbreitet und den Relaxation des Trainings beschädigt.
Hier ist ein minimales Arbeitsbeispiel, bei dem ein dreischichtiges Modell verwendet wird, bei dem an jeder Schicht ein Haken angebracht ist:
import torch
import torch.nn as nn
mannequin = nn.Sequential(nn.Linear(8, 16), nn.ReLU(), nn.Linear(16, 4))
def nan_hook(layer, enter, output):
if output.isnan().any():
print(f"(NaN detected) Layer: {layer.__class__.__name__}")
else:
print(f"(Clear) Layer: {layer.__class__.__name__}, output form: {tuple(output.form)}")
for layer in mannequin:
layer.register_forward_hook(nan_hook)
print("--- Regular enter ---")
mannequin(torch.randn(2, 8))
print("n--- Corrupted enter ---")
bad_input = torch.randn(2, 8)
bad_input(0, 3) = float('nan')
mannequin(bad_input)Erwartete Ausgabe beim Ausführen:
--- Regular enter ---
(Clear) Layer: Linear, output form: (2, 16)
(Clear) Layer: ReLU, output form: (2, 16)
(Clear) Layer: Linear, output form: (2, 4)
--- Corrupted enter ---
(NaN detected) Layer: Linear
(NaN detected) Layer: ReLU
(NaN detected) Layer: LinearIn diesem Beispiel überprüft der Hook den Ausgabetensor nach dem Auslösen jeder Ebene und meldet, ob er sauber oder beschädigt ist.
Die zweimalige Ausführung – einmal mit normaler Eingabe und einmal mit einem einzelnen injizierten NaN – zeigt, wie sich die Instabilität Schicht für Schicht im Netzwerk ausbreitet.
// Debugger-Haltepunkte
Commonplace-Python-Debugger funktionieren innerhalb von Trainingsschleifen einwandfrei.
Fallenlassen import pdb; pdb.set_trace() Pausiert jederzeit die Ausführung und ruft eine interaktive Eingabeaufforderung auf, die es uns ermöglicht, Tensorformen zu untersuchen, zu überprüfen, ob die Datenvorverarbeitung keine unerwarteten Werte erzeugt hat, und den Vorwärtsdurchlauf manuell zu durchlaufen.
Die meisten Entwicklungsumgebungen für maschinelles Lernen – VSCode Und PyCharm Beides – lassen Sie uns Haltepunkte grafisch festlegen und Tensoren in einem speziellen Bereich überprüfen, was eine schnellere Various zur terminalbasierten Methode bietet pdb Schnittstelle.
Haltepunkte sind jedoch während der ersten ein oder zwei Chargen besonders wertvoll, da wir vor Beginn eines vollständigen Trainingslaufs bestätigen, dass die Daten, das Modell und die Verlustfunktion ordnungsgemäß funktionieren.
# Abschluss
Ein Modell zu trainieren, ohne zu visualisieren, was im Inneren passiert, bedeutet, eher Symptome als die tatsächlichen Ursachen zu interpretieren.
Wenn beim Coaching eines Modells die Verlustkurve früh ein Plateau erreicht, Gradienten verschwinden oder sich Einbettungen nicht trennen, macht sich keiner dieser Faktoren ohne die richtige Instrumentierung deutlich bemerkbar.
Die in diesem Artikel behandelten Instruments arbeiten auf verschiedenen Ebenen. Verlustkurven und Gradientenhistogramme geben während des Trainings kontinuierliches Suggestions und erkennen Probleme wie Überanpassung oder verschwindende Gradienten, bevor sie sich verschlimmern und Ihr Framework zerstören.
Die Einbettung von Visualisierungen zeigt, ob das Modell eine gute Trennung aus den Daten lernt. TensorBoard, W&B, Sacred und Guild.ai handhaben die Protokollierungs- und Monitoring-Seite jeweils unterschiedlich, aber sie dienen alle dem gleichen Zweck: den Experimentverlauf durchsuchbar und vergleichbar zu machen, anstatt ihn zu verstreuen. Schließlich gehen Hooks und Debugger noch einen Schritt weiter und ermöglichen es Ihnen, die tatsächlichen Tensoren, die auf jeder Ebene durch das Netzwerk fließen, anzuhalten und zu überprüfen.
Allerdings können diese Instruments ein defektes Modell nicht alleine reparieren. Sie verkürzen den Abstand zwischen einem Fehler und dem Verständnis dafür, warum etwas schiefgeht – was normalerweise die meiste Arbeit ausmacht.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Prime-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Developments auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Knowledge-Science-Projekte vor und behandelt alles rund um SQL.