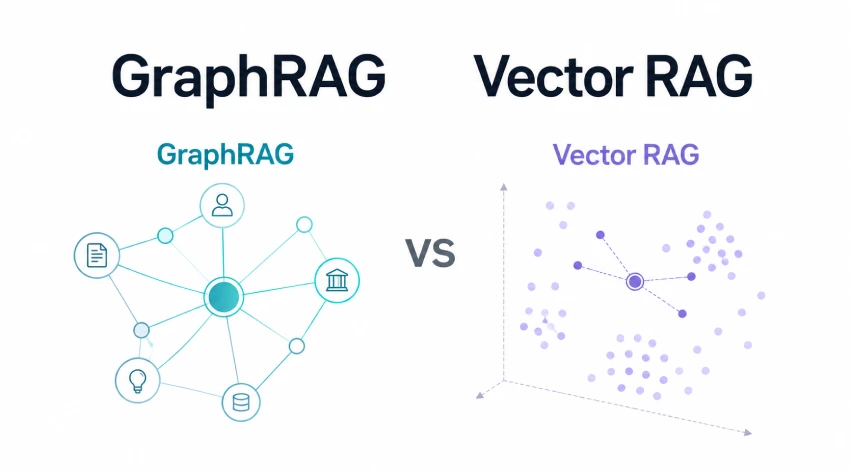
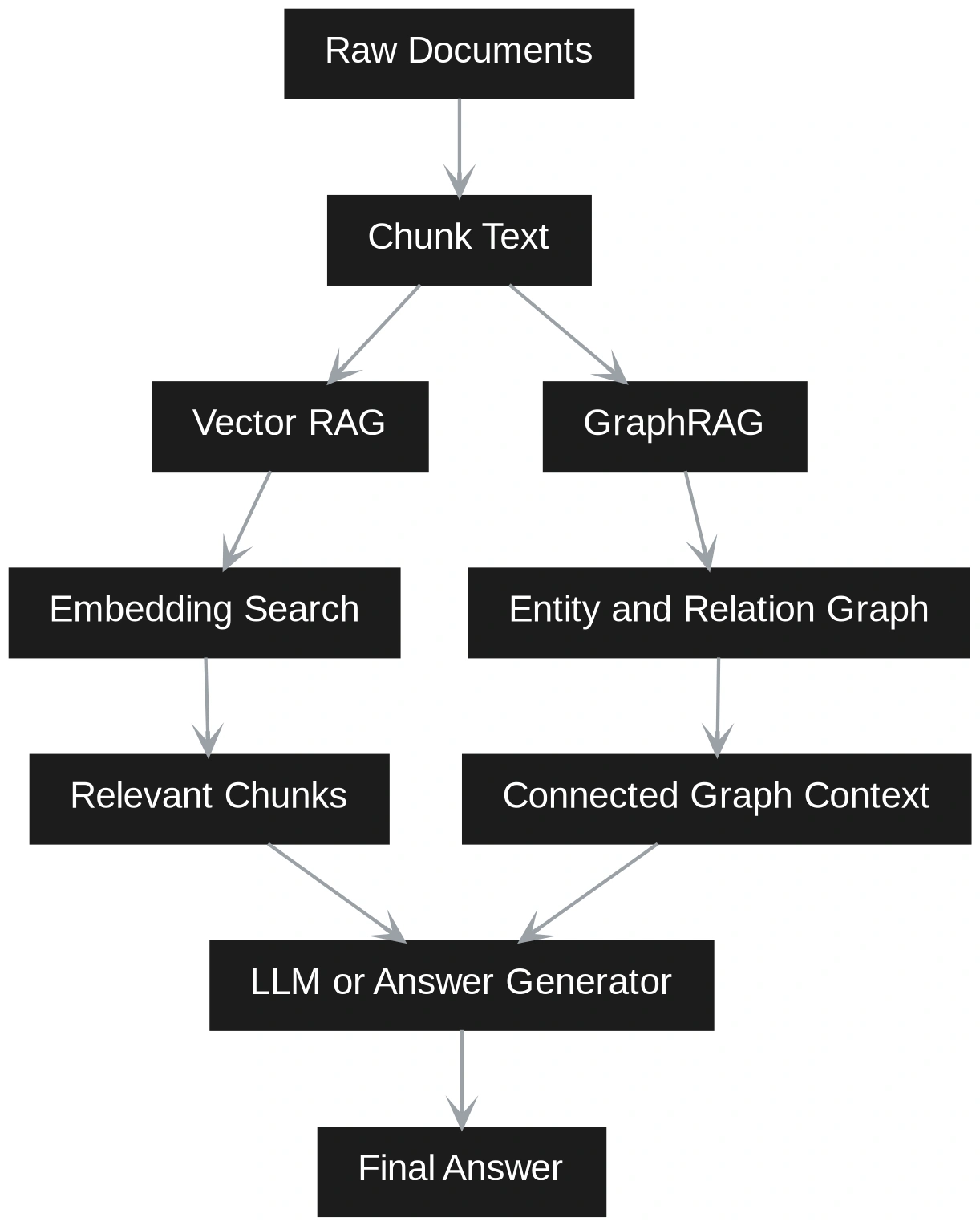
GraphRAG und Vector RAG erfüllen unterschiedliche Abrufanforderungen. Vector RAG teilt Dokumente in Blöcke auf, bettet sie ein, ruft semantisch ähnliche Passagen ab und sendet sie an ein LLM. Es ist einfach, schnell zu erstellen und funktioniert am besten, wenn die Antworten in einem oder zwei relevanten Blöcken liegen.
GraphRAG fügt Struktur hinzu, indem es Entitäten, Beziehungen und Gemeinschaften extrahiert, wodurch es für Multi-Hop-Argumentation, Erklärbarkeit und korpusweite Synthese über verbundene Ideen hinweg stärker wird. In diesem Artikel, einem praktischen Vergleich von GraphRAG und Vector RAG, werden wir aufschlüsseln, wo jeder Ansatz am besten passt.
Definitionen und Architektur
Vector RAG funktioniert durch die Aufteilung von Dokumenten in kleine Textblöcke. Jeder Chunk wird in eine Einbettung umgewandelt und in einer Vektordatenbank gespeichert. Wenn ein Benutzer eine Frage stellt, wird die Frage auch in eine Einbettung umgewandelt. Das System findet dann die ähnlichsten Chunks und sendet sie an das LLM, um eine Antwort zu generieren.
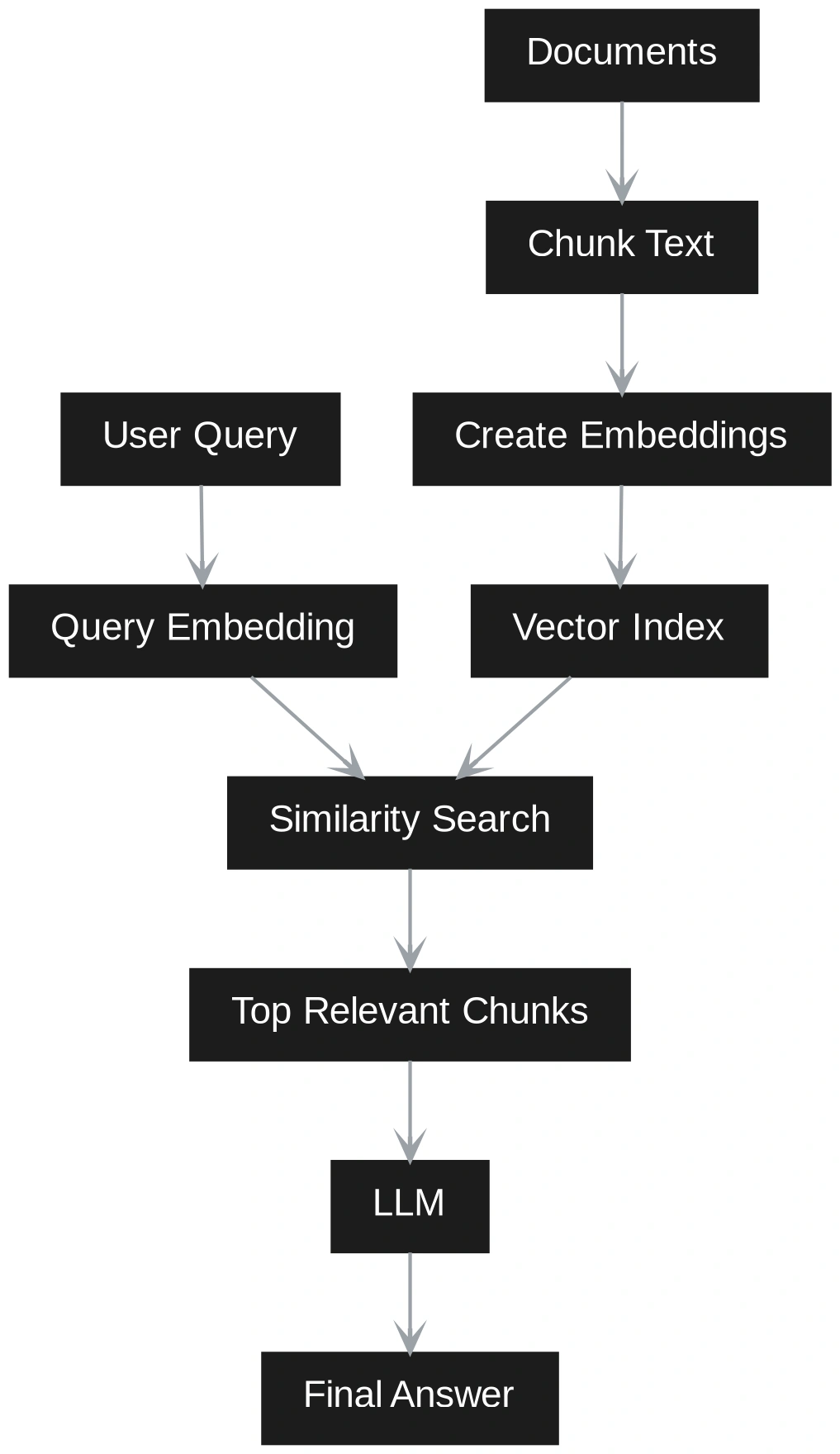
Vector RAG ist einfach, schnell und leicht zu aktualisieren. Es eignet sich intestine für direkte Sachfragen. Die Bedeutung wird jedoch hauptsächlich durch Einbettungen und Textual content gespeichert, nicht durch explizite Entitäten oder Beziehungen. Aus diesem Grund kann es bei Fragen zu Problemen kommen, die Verbindungen über mehrere Blöcke hinweg erfordern.
GraphRAG fügt mehr Struktur hinzu. Es extrahiert Entitäten, Beziehungen, Ansprüche und Communities aus den Dokumenten. Anschließend wird ein Diagramm erstellt, das zeigt, wie verschiedene Informationen miteinander verbunden sind.
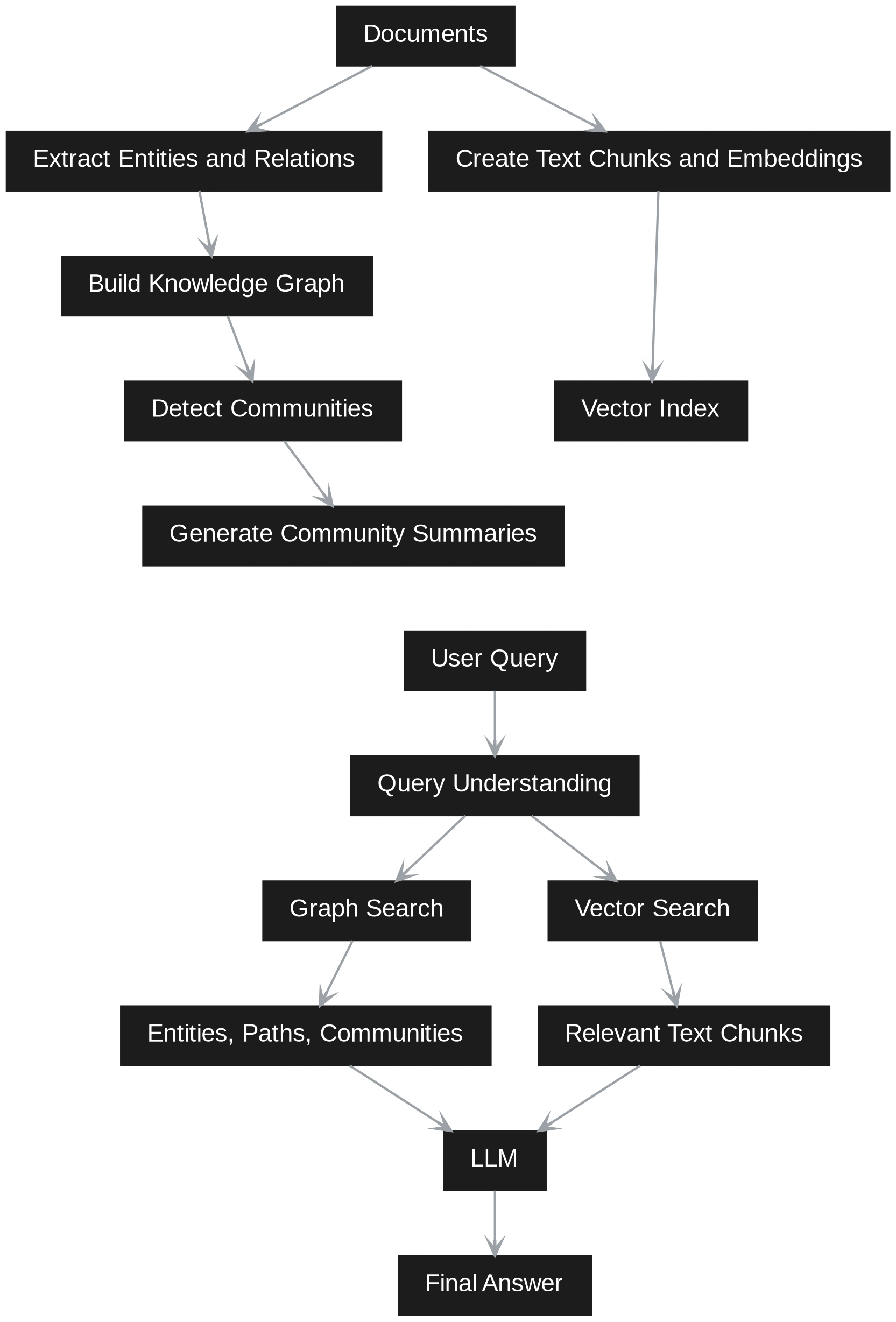
Dadurch eignet sich GraphRAG besser für beziehungsbasierte Fragen, mehrstufiges Denken und ein umfassendes Verständnis einer großen Menge von Dokumenten. Der Nachteil besteht darin, dass die Erstellung mehr Aufwand und Kosten erfordert, da Diagrammerstellung, Neighborhood-Erkennung und Zusammenfassung erforderlich sind.
In der Praxis nutzen viele Systeme beides. Die Vektorsuche findet schnell relevanten Textual content, während das Abrufen von Diagrammen zusammenhängenden Kontext und bessere Argumentation hinzufügt.
So funktioniert der Abruf zum Zeitpunkt der Abfrage
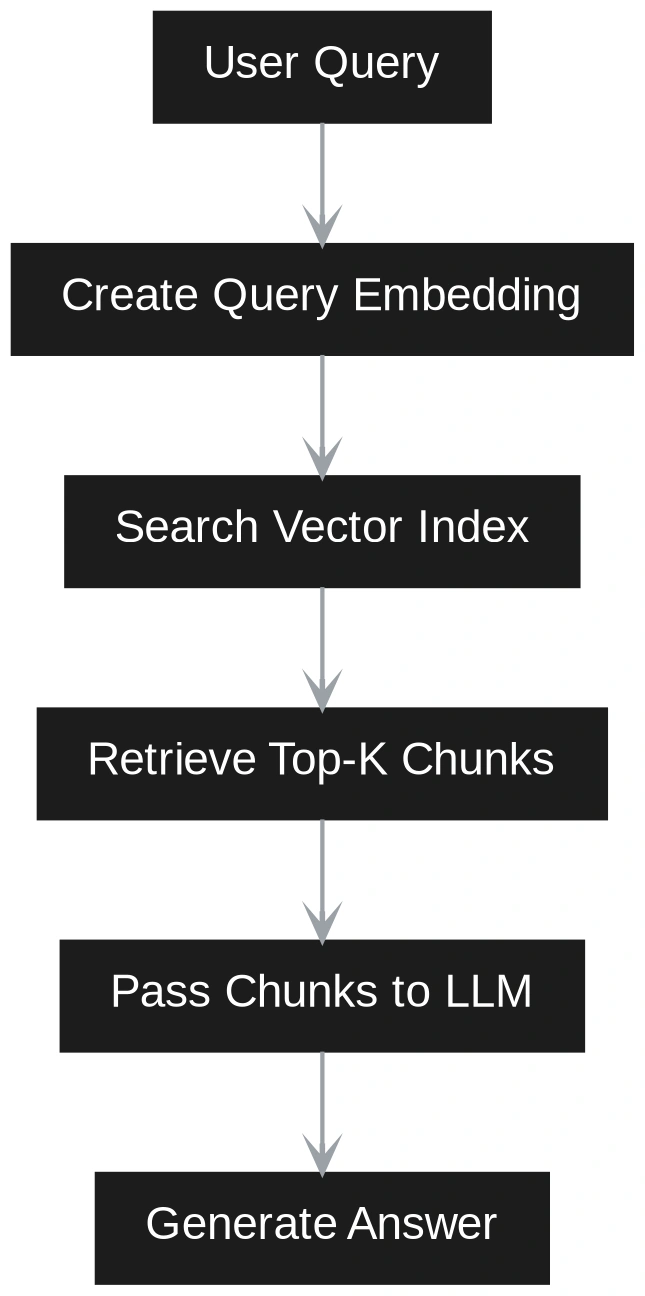
Der größte Unterschied zwischen Vector RAG und GraphRAG wird zum Zeitpunkt der Abfrage deutlich. In Vector RAG wird die Abfrage als semantisches Suchproblem behandelt. Die Benutzerfrage wird in eine Einbettung umgewandelt. Das System vergleicht diese Abfrageeinbettung mit gespeicherten Chunk-Einbettungen. Es ruft die nächstgelegenen Chunks ab und sendet sie an das LLM. Der LLM antwortet dann nur mit diesen Blöcken als Kontext. Dies funktioniert intestine, wenn die Antwort direkt in einer kleinen Anzahl ähnlicher Passagen verfügbar ist.
GraphRAG behandelt die Abfrage unterschiedlich. Zunächst wird versucht zu verstehen, ob die Frage lokal oder international ist. Bei einer lokalen Frage geht es um eine bestimmte Entität, ein bestimmtes Ereignis, einen bestimmten Kunden, ein bestimmtes Produkt oder ein bestimmtes Dokument. Eine globale Frage fragt nach Themen, Mustern, Risiken, Zusammenfassungen oder Beziehungen im gesamten Korpus.
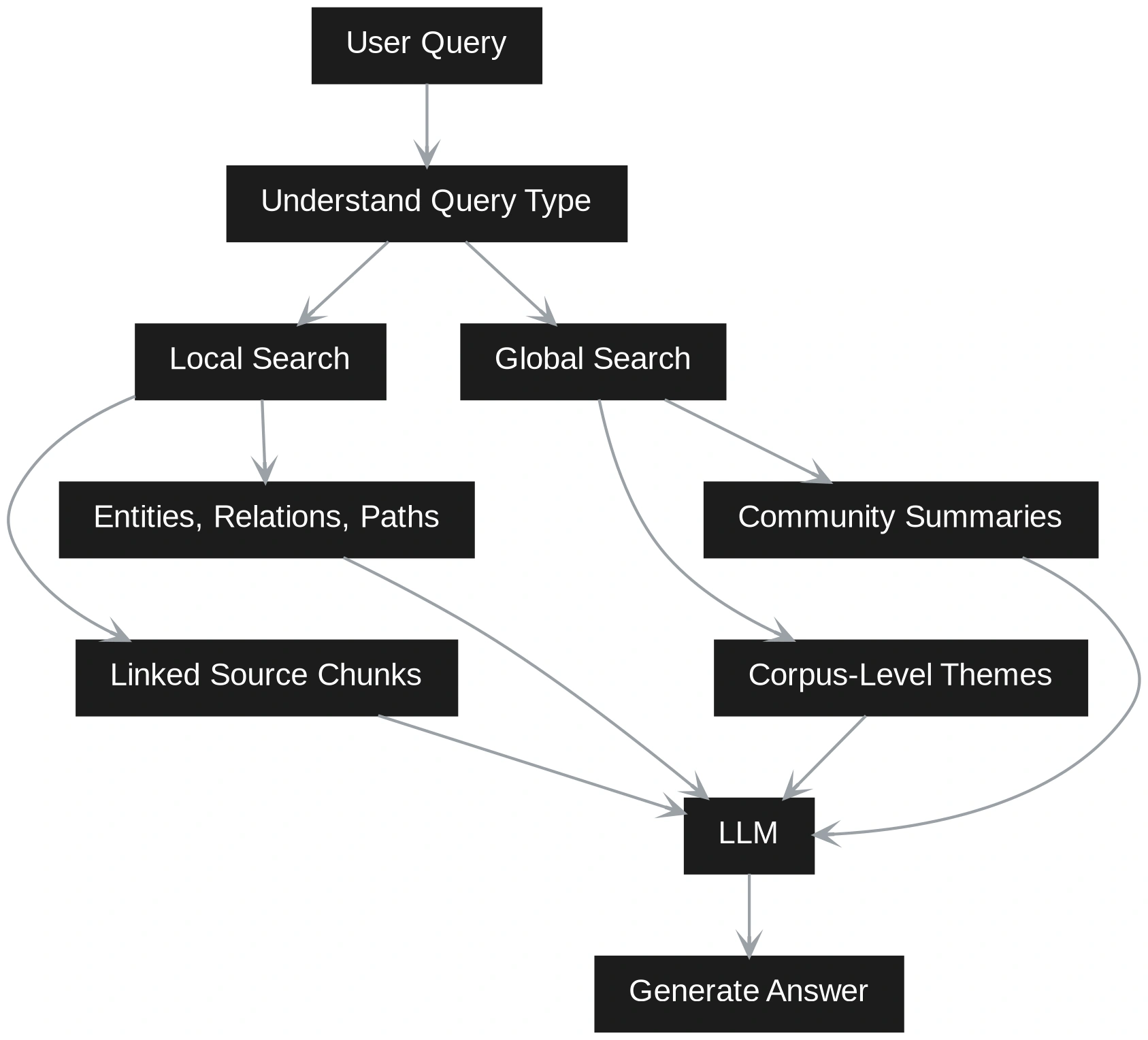
Das bedeutet, dass Vector RAG nach Ähnlichkeit sucht, während GraphRAG nach Struktur und Bedeutung zusammen sucht. Vector RAG ist schneller und einfacher, wenn die Frage eng ist. GraphRAG ist stärker, wenn die Antwort von Verbindungen über viele Dokumente hinweg abhängt. Ein Hybridsystem kann beide Pfade nutzen. Es kann zunächst relevante Blöcke über die Vektorsuche abrufen und dann den Kontext mithilfe von Diagrammbeziehungen erweitern. Dies gibt dem LLM sowohl textliche Beweise als auch eine strukturierte Grundlage.
Praktisch: Erstellen Sie Vector RAG und GraphRAG von Anfang bis Ende
In diesem praktischen Abschnitt werden wir sowohl Vector RAG als auch GraphRAG auf demselben kleinen Korpus aufbauen. Das Ziel ist einfach. Wir möchten zeigen, wie Vector RAG ähnliche Textblöcke abruft, während GraphRAG Entitäten, Beziehungen und verbundenen Kontext abruft. Wir werden Python, SentenceTransformers für Einbettungen, FAISS für die Vektorsuche und NetworkX für die Speicherung und Durchquerung von Diagrammen verwenden. SentenceTransformers unterstützt die Codierung von Textual content in Einbettungen, FAISS ist für eine effiziente Vektorähnlichkeitssuche konzipiert und NetworkX speichert Diagramme als Knoten und Kanten mit Attributen.
Installieren Sie zunächst die erforderlichen Bibliotheken.
pip set up sentence-transformers faiss-cpu networkx pandas numpyErstellen Sie nun ein kleines Demo-Korpus. Dieser Korpus ist absichtlich klein, sodass der Unterschied leicht dargestellt werden kann.
docs = (
{
"id": "doc1",
"textual content": "NourishCo is going through rising logistics prices in its North area. The operations workforce believes the difficulty is linked to poor demand forecasting.",
},
{
"id": "doc2",
"textual content": "The North area makes use of Vendor A for chilly chain supply. Vendor A has repeated supply delays throughout high-demand weeks.",
},
{
"id": "doc3",
"textual content": "The analytics workforce proposed a machine studying forecasting mannequin to cut back stockouts and enhance provide planning.",
},
{
"id": "doc4",
"textual content": "The finance workforce is worried that Vendor A delays are rising working capital stress as a result of stock buffers are rising.",
},
{
"id": "doc5",
"textual content": "The management workforce desires an AI roadmap that connects demand forecasting, logistics optimization, and vendor efficiency monitoring.",
},
)Definieren Sie nun eine einfache Chunking-Funktion. In dieser Demo ist jedes Dokument bereits kurz, daher behandeln wir jedes Dokument als einen Block.
chunks = ()
for doc in docs:
chunks.append({
"chunk_id": doc("id"),
"textual content": doc("textual content"),
})
print(chunks)Erstellen Sie nun den Vector RAG-Index.
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
mannequin = SentenceTransformer("all-MiniLM-L6-v2")
texts = (chunk("textual content") for chunk in chunks)
embeddings = mannequin.encode(texts, convert_to_numpy=True)
dimension = embeddings.form(1)
index = faiss.IndexFlatL2(dimension)
index.add(embeddings)
print("Vector index created with", index.ntotal, "chunks")
Erstellen Sie nun eine Vector RAG-Abruffunktion.
def vector_rag_search(question, top_k=3):
query_embedding = mannequin.encode((question), convert_to_numpy=True)
distances, indices = index.search(query_embedding, top_k)
outcomes = ()
for idx in indices(0):
outcomes.append(chunks(idx))
return outcomes
# Check the Vector RAG pipeline
question = "Why are logistics prices rising within the North area?"
vector_results = vector_rag_search(question)
for end in vector_results:
print(end result("chunk_id"), ":", end result("textual content"))
Dadurch werden Blöcke abgerufen, die der Frage semantisch nahe kommen. Es sollten Dokumente über die Area Nord, Logistikkosten, Lieferant A und Verzögerungen zurückgegeben werden. Dies ist nützlich, wenn die Antwort in einem oder zwei ähnlichen Blöcken vorliegt.
Jetzt lasst uns das bauen GraphRAG Model. In einem Produktionssystem werden Entitäten und Beziehungen normalerweise mit einem LLM oder einem Informationsextraktionsmodell extrahiert. Für diese praktische Demo definieren wir sie manuell, damit der Ablauf leicht zu verstehen und zu erklären ist.
import networkx as nx
G = nx.Graph()
entities = (
"NourishCo",
"North Area",
"Logistics Prices",
"Demand Forecasting",
"Vendor A",
"Supply Delays",
"Analytics Workforce",
"ML Forecasting Mannequin",
"Stockouts",
"Provide Planning",
"Finance Workforce",
"Working Capital Strain",
"Stock Buffers",
"Management Workforce",
"AI Roadmap",
"Logistics Optimization",
"Vendor Efficiency Monitoring",
)
G.add_nodes_from(entities)
relationships = (
("NourishCo", "North Area", "operates in"),
("North Area", "Logistics Prices", "has situation"),
("Logistics Prices", "Demand Forecasting", "linked to"),
("North Area", "Vendor A", "makes use of"),
("Vendor A", "Supply Delays", "causes"),
("Supply Delays", "Logistics Prices", "will increase"),
("Analytics Workforce", "ML Forecasting Mannequin", "proposed"),
("ML Forecasting Mannequin", "Demand Forecasting", "improves"),
("ML Forecasting Mannequin", "Stockouts", "reduces"),
("ML Forecasting Mannequin", "Provide Planning", "improves"),
("Finance Workforce", "Working Capital Strain", "involved about"),
("Vendor A", "Working Capital Strain", "contributes to"),
("Stock Buffers", "Working Capital Strain", "improve"),
("Supply Delays", "Stock Buffers", "improve"),
("Management Workforce", "AI Roadmap", "desires"),
("AI Roadmap", "Demand Forecasting", "contains"),
("AI Roadmap", "Logistics Optimization", "contains"),
("AI Roadmap", "Vendor Efficiency Monitoring", "contains"),
)
for supply, goal, relation in relationships:
G.add_edge(supply, goal, relation=relation)
print(
"Graph created with",
G.number_of_nodes(),
"nodes and",
G.number_of_edges(),
"edges",
)
Erstellen Sie nun eine Funktion zum Überprüfen der Diagrammnachbarn.
def get_graph_context(entity, depth=1):
if entity not in G:
return ()
context = ()
visited = set((entity))
frontier = (entity)
for _ in vary(depth):
next_frontier = ()
for node in frontier:
for neighbor in G.neighbors(node):
edge_data = G.get_edge_data(node, neighbor)
relation = edge_data("relation")
context.append({
"supply": node,
"relation": relation,
"goal": neighbor,
})
if neighbor not in visited:
visited.add(neighbor)
next_frontier.append(neighbor)
frontier = next_frontier
return context
# Check the graph retrieval
graph_results = get_graph_context("Vendor A", depth=2)
for merchandise in graph_results:
print(merchandise("supply"), "--", merchandise("relation"), "--", merchandise("goal"))
Dies ergibt einen zusammenhängenden Kontext. Es werden nicht nur ähnliche Blöcke abgerufen. Es zeigt, wie Anbieter A mit Lieferverzögerungen, Logistikkosten, Lagerpuffern und Betriebskapitaldruck zu tun hat.
Jetzt erstellen wir eine einfache GraphRAG-Abfragefunktion. Für die Demo werden wir Abfrageschlüsselwörter Entitäten zuordnen.
def detect_entity(question):
query_lower = question.decrease()
entity_map = {
"vendor": "Vendor A",
"logistics": "Logistics Prices",
"north": "North Area",
"forecasting": "Demand Forecasting",
"working capital": "Working Capital Strain",
"monetary stress": "Working Capital Strain",
"roadmap": "AI Roadmap",
}
for key phrase, entity in entity_map.gadgets():
if key phrase in query_lower:
return entity
return None
def graph_rag_search(question, depth=2):
entity = detect_entity(question)
if not entity:
return ()
return get_graph_context(entity, depth=depth)
# Check GraphRAG
question = "How is Vendor A related to monetary stress?"
graph_context = graph_rag_search(question)
for merchandise in graph_context:
print(merchandise("supply"), "--", merchandise("relation"), "--", merchandise("goal"))
Vergleichen Sie nun beide Methoden für dieselbe Abfrage.
question = "How is Vendor A related to monetary stress?"
print("VECTOR RAG RESULTS")
vector_results = vector_rag_search(question)
for end in vector_results:
print("-", end result("textual content"))
print("nGRAPHRAG RESULTS")
graph_context = graph_rag_search(question)
for merchandise in graph_context:
print("-", merchandise("supply"), merchandise("relation"), merchandise("goal"))
Die Vector RAG-Ausgabe gibt die ähnlichsten Textblöcke zurück. Möglicherweise werden das Finanzdokument und das Dokument von Lieferant A gefunden. GraphRAG zeigt die Beziehungskette klarer. Es kann gezeigt werden, dass Lieferant A Lieferverzögerungen verursacht, dass Lieferverzögerungen die Bestandspuffer erhöhen und dass Bestandspuffer den Druck auf das Betriebskapital erhöhen.
Fügen Sie nun einen einfachen Antwortgenerator hinzu. Diese Model erfordert keine LLM-API. Es erstellt eine lesbare Antwort aus dem abgerufenen Kontext.
def generate_vector_answer(question, retrieved_chunks):
context = " ".be a part of((chunk("textual content") for chunk in retrieved_chunks))
reply = f"""
Query: {question}
Vector RAG Reply:
Primarily based on the retrieved chunks, {context}
"""
return reply
def generate_graph_answer(question, graph_context):
info = ()
for merchandise in graph_context:
info.append(
f"{merchandise('supply')} {merchandise('relation')} {merchandise('goal')}"
)
joined_facts = ". ".be a part of(info)
reply = f"""
Query: {question}
GraphRAG Reply:
Primarily based on the graph relationships, {joined_facts}.
"""
return reply
# Run each reply turbines
question = "How is Vendor A related to monetary stress?"
vector_context = vector_rag_search(question)
graph_context = graph_rag_search(question)
print(generate_vector_answer(question, vector_context))
print(generate_graph_answer(question, graph_context))
Für eine realistischere Demo können Sie diesen Abrufausgang mit einem LLM verbinden. Die LLM-Eingabeaufforderung kann einfach gehalten werden.
def build_llm_prompt(question, vector_context, graph_context):
vector_text = "n".be a part of((chunk("textual content") for chunk in vector_context))
graph_text = "n".be a part of((
f"{merchandise('supply')} -- {merchandise('relation')} -- {merchandise('goal')}"
for merchandise in graph_context
))
immediate = f"""
You're a enterprise analyst.
Reply the query utilizing solely the offered context.
Query:
{question}
Vector Context:
{vector_text}
Graph Context:
{graph_text}
Last Reply:
"""
return immediate
immediate = build_llm_prompt(question, vector_context, graph_context)
print(immediate)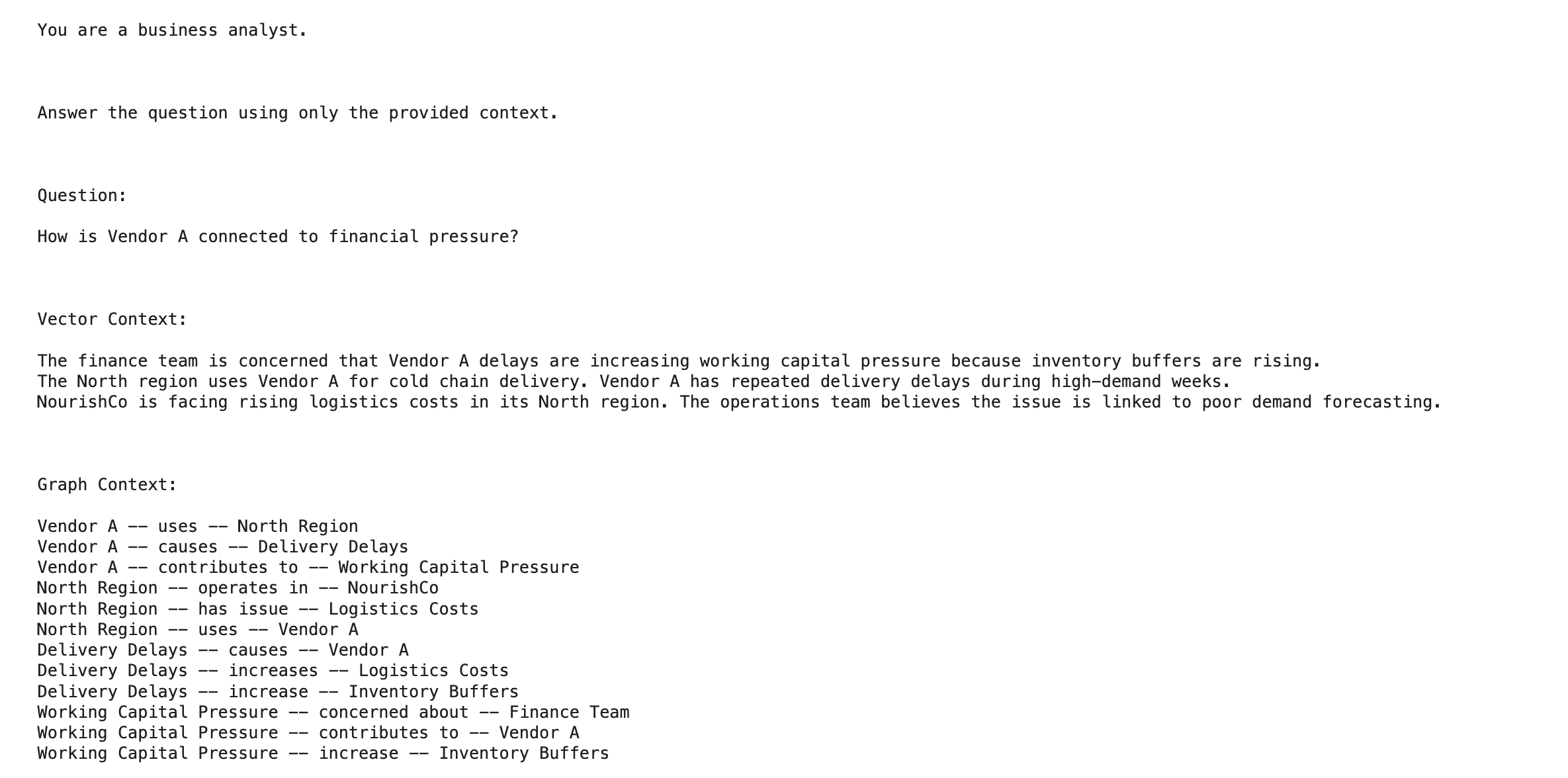
Wann man Vector RAG, GraphRAG oder Hybrid RAG verwenden sollte
Verwenden Vektor-RAG wenn die Antwort wahrscheinlich in einem oder mehreren Textabschnitten vorhanden ist. Es ist einfach, schnell und eignet sich intestine für direkte Suchfragen.
Zu den häufigsten Anwendungsfällen gehören:
- FAQs
- Richtliniendokumente
- Produkthandbücher
- Help-Artikel
- Dokumentensuche
- Basiswissensassistenten
Eine typische Vector RAG-Frage sieht so aus:
„Was steht in der Rückerstattungsrichtlinie?“
Verwenden GraphRAG wenn die Antwort von Beziehungen im gesamten Korpus abhängt. Es ist besser in der Lage, Einheiten, Ereignisse, Risiken, Groups, Anbieter und Geschäftsprozesse zu verbinden.
Zu den häufigsten Anwendungsfällen gehören:
- Ursachenanalyse
- Compliance-Überprüfung
- Untersuchungen
- Risikoanalyse
- Lieferantenanalyse
- Strategische Synthese
- Wissensentdeckung
Eine typische GraphRAG-Frage sieht so aus:
„Wie hängt Anbieter A mit dem finanziellen Druck in der Nordregion zusammen?“
Verwenden Hybrid-RAG wenn das System sowohl einen schnellen Abruf als auch tiefere Überlegungen benötigt. Durch die Vektorsuche kann schnell relevanter Textual content gefunden werden, während durch das Abrufen von Diagrammen verbundener Kontext hinzugefügt wird.
Dies ist oft die beste Produktionskonfiguration, da echte Benutzer gemischte Fragen stellen. Bei einigen Fragen handelt es sich um einfache Nachschlagefragen. Andere benötigen Multi-Hop-Argumentation. Manche brauchen beides.
Eine einfache Routing-Regel:
Direct factual query → Vector RAG
Relationship-heavy query → GraphRAG
Combined or strategic query → Hybrid RAGDie praktische Regel ist einfach: Beginnen Sie mit Vector RAG. Fügen Sie GraphRAG hinzu, wenn bei der Ähnlichkeitssuche wichtige Zusammenhänge übersehen werden. Verwenden Sie Hybrid RAG, wenn die Anwendung sowohl Geschwindigkeit als auch Struktur benötigt.
Kompromisse zwischen Leistung, Kosten und Wartung
| Dimension | Vektor-RAG | GraphRAG |
| Indexierungsprozess | Dokumente werden in Blöcke aufgeteilt, eingebettet und in einem Vektorindex gespeichert. | Dokumente werden verarbeitet, um Entitäten, Beziehungen, Ansprüche, Gemeinschaften und Zusammenfassungen zu extrahieren. |
| Indexierungskosten | Geringere Kosten, da die Pipeline einfach ist. | Höhere Kosten, da bei der Diagrammerstellung und -zusammenfassung zusätzliche Schritte erforderlich sind. |
| Aktualisierungsaufwand | Einfacher zu aktualisieren. Neue Dokumente können in Blöcke aufgeteilt und inkrementell eingebettet werden. | Schwieriger zu aktualisieren. Für neue Inhalte sind möglicherweise Entitätsextraktion, Beziehungsaktualisierungen und Diagrammaktualisierungen erforderlich. |
| Abrufgeschwindigkeit | Normalerweise schneller, da eine Ähnlichkeitssuche verwendet wird. | Kann langsamer sein, da es das Durchlaufen von Graphen, die Entitätserweiterung und das Abrufen von Zusammenfassungen umfassen kann. |
| Bester Anwendungsfall | Direkte Sachfragen und semantische Suche. | Beziehungsintensive Fragen, Multi-Hop-Argumentation und korpusweite Synthese. |
| Erklärbarkeit | Erklärt Antworten hauptsächlich durch abgerufene Blöcke. | Erklärt Antworten anhand von Abschnitten, Entitäten, Beziehungen, Pfaden und Zusammenfassungen. |
| Wartungskomplexität | Einfachere Pflege in sich schnell ändernden Wissensdatenbanken. | Es sind weitere Qualitätsprüfungen erforderlich, da sich falsche Entitäten oder Beziehungen auf die Antworten auswirken können. |
| Praktischer Kompromiss | Am besten, wenn Geschwindigkeit, Einfachheit und Kosten im Vordergrund stehen. | Am besten, wenn Struktur, Erklärbarkeit und tiefere Argumentation wichtiger sind. |
Einschränkungen und Fehlermodi
Es ist alles intestine, bis es zum Stillstand kommt. So kann es passieren:
- Wo Vector RAG scheitern kann
- Vector RAG kann Schwierigkeiten haben, wenn die richtige Antwort nicht in einem klaren Block enthalten ist.
- Möglicherweise wird Textual content abgerufen, der semantisch ähnlich klingt, die Frage jedoch nicht vollständig beantwortet.
- Dies ist häufig der Fall, wenn die Abfrage eine Begründung über mehrere Dokumente hinweg erfordert.
- Da Vector RAG Entitäten, Pfade oder Abhängigkeiten nicht explizit versteht, kann es verborgene Beziehungen zwischen Konzepten übersehen.
- Wo GraphRAG scheitern kann
- GraphRAG kann fehlschlagen, wenn das zugrunde liegende Diagramm schwach oder unvollständig ist.
- Wenn die Entitätsextraktion ungenau ist, werden diese Fehler in das Diagramm übernommen.
- Fehlen wichtige Zusammenhänge, kann es sein, dass das System eine unvollständige oder irreführende Antwort liefert.
- GraphRAG erfordert außerdem mehr Vorverarbeitung als Vector RAG.
- Bei einfachen Suchaufgaben lohnen sich die zusätzlichen Kosten und die Komplexität möglicherweise nicht immer.
- Die Frische-Herausforderung
- Vector RAG lässt sich normalerweise einfacher aktualisieren, wenn sich Quelldokumente ändern.
- GraphRAG erfordert möglicherweise Diagrammaktualisierungen, aktualisierte Zusammenfassungen und eine Beziehungsvalidierung.
- Dadurch wird die Wartung mit der Zeit komplexer.
- Den richtigen Ansatz wählen
- Bewerten Sie beide Systeme anhand realer Benutzerfragen.
- Beginnen Sie mit Vector RAG als Basislinie.
- Fügen Sie GraphRAG nur hinzu, wenn die Basislinie bei beziehungsintensiven oder korpusweiten Fragen fehlschlägt.
- Verwenden Sie Hybrid RAG, wenn dieselbe Anwendung sowohl eine direkte Suche als auch tiefere Überlegungen erfordert.
Abschluss
Vector RAG und GraphRAG sind beide nützlich, lösen jedoch unterschiedliche Probleme. Vector RAG ist der beste erste Schritt. Es ist schnell, einfach und stark für direkte Fragen. GraphRAG ist nützlich, wenn Antworten von Entitäten, Beziehungen, Pfaden und Themen in vielen Dokumenten abhängen. Es sorgt für mehr Struktur, erhöht aber auch die Kosten und den Wartungsaufwand. In realen Projekten ist der beste Ansatz oft hybrid. Nutzen Sie Vector RAG für schnelle Beweise. Verwenden Sie GraphRAG für zusammenhängendes Denken. Das Ziel besteht nicht darin, das komplexeste System aufzubauen. Ziel ist es, den richtigen Kontext abzurufen und verlässliche Antworten zu generieren.
Häufig gestellte Fragen
A. Vektor-RAG beruht auf semantischer Ähnlichkeit; Es zerlegt Textual content in Stücke, wandelt ihn in Einbettungen um und ruft daraus Absätze ab Klang entspricht am ehesten der Anfrage des Benutzers. GraphRAG setzt auf Struktur; Es extrahiert Entitäten (wie Personen, Orte oder Unternehmen) und die Beziehungen zwischen ihnen, um einen Wissensgraphen zu erstellen und Informationen basierend auf der expliziten Verknüpfung von Konzepten abzurufen.
A. Vector RAG ist die beste Wahl für direkte, sachliche Fragen, bei denen die Antwort wahrscheinlich in einem einzigen Absatz oder Dokument enthalten ist (z. B. „Wie lautet die Distant-Arbeitsrichtlinie des Unternehmens?“). Es ist schneller zu erstellen, kostengünstiger in der Ausführung und viel einfacher zu aktualisieren als GraphRAG.
A. GraphRAG zeichnet sich durch „Multi-Hop-Argumentation“ und globale Fragen aus, die eine Verknüpfung von Informationen über viele verschiedene Dokumente hinweg erfordern. Antworten Sie beispielsweise: „Wie hat sich die Verzögerung der Lieferkette in Asien auf den Umsatz im dritten Quartal in Europa ausgewirkt?“ erfordert das Verständnis der Beziehung zwischen der Verzögerung, der Area und dem finanziellen Ergebnis, was ein Wissensgraph viel besser bewältigen kann als eine einfache Vektorsuche.
Hallo, ich bin Janvi, ein leidenschaftlicher Knowledge-Science-Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Welt der Daten begann mit einer tiefen Neugier, wie wir aus komplexen Datensätzen aussagekräftige Erkenntnisse gewinnen können.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.