OpenAI hat kürzlich eine Reihe von Audiomodellen der nächsten Technology vorgestellt und die Funktionen von Sprachanwendungen verbessert. Diese Fortschritte beinhalten neue Sprache zu Textual content (Stt) und Textual content-to-Speech (TTS) Modelle und bieten Entwicklern mehr Instruments, um anspruchsvolle Sprachmittel zu erstellen. Diese auf API veröffentlichten fortschrittlichen Sprachmodelle ermöglichen es den Entwicklern weltweit, versatile und zuverlässige Sprachmittel viel einfacher aufzubauen. In diesem Artikel werden wir die Funktionen und Anwendungen des neuesten GPT-4O-transkriben-, GPT-4O-Mini-Trancribe- und GPT-4O-Mini-TTS-Modellen untersuchen. Wir werden auch lernen, wie man auf OpenAIs Audiomodelle zugreift und sie selbst ausprobieren. Additionally lass uns anfangen!
OpenAIs neue Audiomodelle
OpenAI hat eine neue Technology von Audiomodellen eingeführt, die die Funktionen der Spracherkennung und Sprachsynthese verbessern sollen. Diese Modelle bieten Verbesserungen in Bezug auf Genauigkeit, Geschwindigkeit und Flexibilität und ermöglichen es den Entwicklern, leistungsstärkere KI-gesteuerte Sprachanwendungen aufzubauen. Die Suite enthält 2 Sprach-Textual content-Modelle und 1 Textual content-to-Speech-Modell, nämlich:
- GPT-4O-Transkribe: Das fortschrittlichste Sprachmodell von OpenAI und bietet branchenführende Transkriptionsgenauigkeit. Es ist für Anwendungen ausgelegt, die präzise und zuverlässige Transkriptionen erfordern, z. B. Besprechungs- und Vorlesungstranskriptionen, Kundendienst -Anrufprotokolle und Inhaltsuntertitelung.
- GPT-4O-Mini-Trankribe: Eine kleinere, leichte und effizientere Model des obigen Transkriptionsmodells. Es ist für Anwendungen mit niedrigerer Latenz wie Reside-Bildunterschriften, Sprachbefehle und interaktive AI-Agenten optimiert. Es bietet schnellere Transkriptionsgeschwindigkeiten, niedrigere Rechenkosten und ein Gleichgewicht zwischen Genauigkeit und Effizienz.
- GPT-4O-Mini-TTs: Dieses Modell führt die Fähigkeit ein, die KI zu unterweisen, in bestimmten Stilen oder Tönen zu sprechen, wodurch die Stimmen von AI-generierten Menschen menschlicher klingen. Entwickler können jetzt den Sprachton des Agenten so anpassen, dass sie verschiedene Kontexte wie freundlich, professionell oder dramatisch entsprechen. Es funktioniert intestine mit OpenAs Speech-to-Textual content-Modellen und ermöglicht die Interaktionen mit reibungslosen Sprache.
Die Sprach-zu-Textual content-Modelle sind mit fortschrittlichen Technologien wie Rauschunterdrückung ausgestattet. Sie sind auch mit einem semantischen Sprachaktivitätsdetektor ausgestattet, der genau erkennen kann, wann der Benutzer das Sprechen beendet hat. Diese Innovationen helfen Entwicklern dabei, eine Reihe gemeinsamer Probleme zu bewältigen, während sie Sprachagenten aufbauen. Zusammen mit diesen neuen Modellen gab OpenAI außerdem bekannt, dass seine kürzlich gestarteten Agenten SDK jetzt Audio unterstützt, was es den Entwicklern noch einfacher macht, Sprachagenten zu erstellen.
Erfahren Sie mehr: Wie benutze ich OpenAI -Antworten API & Agent SDK?
Technische Innovationen hinter den Audiomodellen von OpenAI
Die Fortschritte in diesen Audiomodellen werden auf mehrere wichtige technische Innovationen zurückgeführt:
- Vorbereitung mit authentischen Audio -Datensätzen: Durch die Nutzung umfangreicher und vielfältiger Audiodaten wurde die Fähigkeit der Modelle bereichert, menschliche Sprachmuster zu verstehen und zu generieren.
- Erweiterte Destillationsmethoden: Diese Techniken wurden eingesetzt, um die Modellleistung zu optimieren und die Effizienz ohne Kompromisse zu gewährleisten.
- Verstärkungslernparadigma: Die Implementierung des Verstärkungslernens hat zu den verbesserten Genauigkeit und Anpassungsfähigkeit der Modelle in verschiedenen Sprachszenarien beigetragen.
So greifen Sie auf die Audiomodelle von OpenAI zu
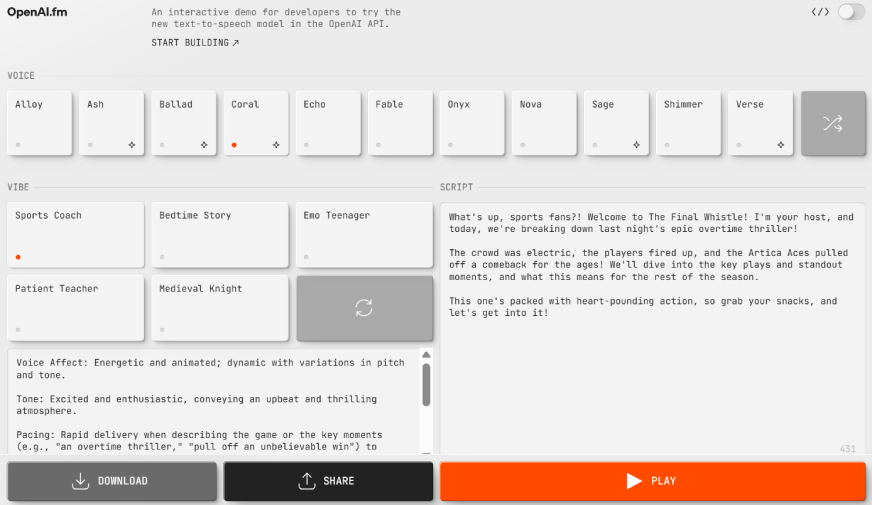
Das neueste Modell, GPT-4O-Mini TTS, ist auf einer neuen Plattform erhältlich, die von Open AI namens Openai.fm veröffentlicht wurde. So können Sie auf dieses Modell zugreifen:
- Öffnen Sie die Web site
Zuerst gehen Sie zu www.openai.fm.
- Wählen Sie die Stimme und Stimmung
Wählen Sie auf der Schnittstelle, die sich öffnet, Ihre Stimme und setzen Sie die Stimmung. Wenn Sie das richtige Zeichen mit der richtigen Stimmung nicht finden können, klicken Sie auf die Schaltfläche Aktualisieren, um verschiedene Optionen zu erhalten.
- Feinstimmen Sie die Stimme
Sie können die ausgewählte Stimme weiter mit einer detaillierten Eingabeaufforderung anpassen. Unter den Vibe -Optionen können Sie Particulars wie Akzent, Ton, Tempo usw. eingeben, um die genaue Stimme zu erhalten, die Sie möchten.
- Fügen Sie das Skript hinzu und spielen Sie ab
Geben Sie nach dem Einstellen Ihr Skript einfach rechts in das Texteingangsfeld ein und klicken Sie auf die Schaltfläche „Spielen“. Wenn Ihnen das gefällt, was Sie hören, können Sie das Audio entweder herunterladen oder extern teilen. Wenn nicht, können Sie weiterhin mehr Iterationen ausprobieren, bis Sie es richtig machen.

Die Seite erfordert keine Anmeldung und Sie können mit dem Modell spielen, wie Sie möchten. Darüber hinaus gibt es in der oberen rechten Ecke sogar einen Umschalter, der Ihnen den Code für das Modell bietet, das von Ihren Auswahlmöglichkeiten entspricht.
Praktische Exams von OpenAIs Audiomodellen
Nachdem wir wissen, wie man das Modell benutzt, probieren wir es aus! Probieren wir zunächst die OpenAI.FM -Web site aus.
1. Verwenden Sie GPT-4O-Mini-Transcribe auf OpenAi.fm
Nehmen wir an, ich möchte einen Sprachvertreter von „Emergency Companies“ aufbauen.
Für diesen Agenten wähle ich das aus:
- Stimme – Nova
- Stimmung – sympathisch
Verwenden Sie die folgenden Anweisungen:
Ton: Ruhig, selbstbewusst und maßgeblich. Beruhigend, um den Anrufer beruhigt zu halten, während er mit der State of affairs umgeht. Professionell und dennoch einfühlsam, reflektiert echte Sorge um das Wohlbefinden des Anrufers.
Tempo: Stabil, klar und absichtlich. Nicht zu schnell, um Panik zu vermeiden, aber nicht zu langsam, um die Reaktion zu verzögern. Leichte Pausen, um dem Anrufer Zeit zu geben, um Informationen zu reagieren und zu verarbeiten.
Klarheit: Klarer, neutraler Akzent mit einer intestine ausgewiesenen Stimme. Vermeiden Sie Jargon oder komplizierte Begriffe mit einer einfachen, leicht verständlichen Sprache.
Empathie: Bestätigen Sie den emotionalen Zustand des Anrufers (Angst, Panik usw.), ohne ihn hinzuzufügen.
Bieten Sie während des Gesprächs ruhige Beruhigung und Unterstützung.
Verwenden Sie das folgende Skript:
„Hallo, das ist Rettungsdienste. Ich bin hier, um Ihnen zu helfen. Bitte bleiben Sie ruhig und hören Sie genau zu, während ich Sie durch diese State of affairs führe.“
„Hilfe ist unterwegs, aber ich brauche ein bisschen Informationen, um sicherzustellen, dass wir schnell und angemessen reagieren.“
„Bitte geben Sie mir Ihren Standort an. Die genaue Adresse oder die nahe gelegenen Wahrzeichen hilft uns, schneller zu Ihnen zu gelangen.“
„Danke; Wenn jemand verletzt ist, muss Sie bei ihnen bleiben und es vermeiden, sie zu bewegen, es sei denn, es ist erforderlich.“
„Wenn es blutet, üben Sie Druck auf die Wunde aus, um sie zu kontrollieren. Wenn die Particular person nicht atmet, werde ich Sie durch CPR führen. Bitte bleiben Sie bei ihnen und bleiben Sie ruhig.“
„Wenn es keine Verletzungen gibt, finden Sie bitte einen sicheren Ort und bleiben Sie dort. Vermeiden Sie Gefahr und warten Sie auf Eintreffen von Rettungskräften.“
„Es geht dir intestine. Bleib mit mir auf der Strecke, und ich werde sicherstellen, dass Hilfe auf dem Weg ist und Sie auf dem Laufenden halten, bis die Responder eintreffen.“

Ausgabe:
Conflict das nicht toll? Die neuesten Audio -Modelle von OpenAI sind jetzt auch über die API von OpenAI zugänglich, sodass Entwickler sie in verschiedene Anwendungen integrieren können.
Testen wir das jetzt.
2. Verwenden Sie GPT-4O-Audio-Präview über API
Wir werden über OpenAs API auf das Modell GPT-4O-Audio-Präview-Modells zugreifen und 2 Aufgaben ausprobieren: eine für Textual content-zu-Sprache und die andere für Speech-to-Textual content.
Aufgabe 1: Textual content-to-Speech
Für diese Aufgabe werde ich das Modell bitten, mir einen Witz zu erzählen.
Codeeingabe:
import base64
from openai import OpenAI
consumer = OpenAI(api_key = "OPENAI_API_KEY")
completion = consumer.chat.completions.create(
mannequin="gpt-4o-audio-preview",
modalities=("textual content", "audio"),
audio={"voice": "alloy", "format": "wav"},
messages=(
{
"function": "consumer",
"content material": "Are you able to inform me a joke about an AI making an attempt to inform a joke?"
}
)
)
print(completion.selections(0))
wav_bytes = base64.b64decode(completion.selections(0).message.audio.knowledge)
with open("output.wav", "wb") as f:
f.write(wav_bytes)Antwort:
Aufgabe 2: Sprache zu Textual content
Für unsere zweite Aufgabe geben wir das Modell an Diese Audiodatei und sehen Sie, ob es uns über die Aufnahme erzählen kann.
Codeeingabe:
import base64
import requests
from openai import OpenAI
consumer = OpenAI(api_key = "OPENAI_API_KEY")
# Fetch the audio file and convert it to a base64 encoded string
url = "https://cdn.openai.com/API/docs/audio/alloy.wav"
response = requests.get(url)
response.raise_for_status()
wav_data = response.content material
encoded_string = base64.b64encode(wav_data).decode('utf-8')
completion = consumer.chat.completions.create(
mannequin="gpt-4o-audio-preview",
modalities=("textual content", "audio"),
audio={"voice": "alloy", "format": "wav"},
messages=(
{
"function": "consumer",
"content material": (
{
"sort": "textual content",
"textual content": "What's on this recording?"
},
{
"sort": "input_audio",
"input_audio": {
"knowledge": encoded_string,
"format": "wav"
}
}
)
},
)
)
print(completion.selections(0).message)Antwort:

Benchmarkergebnisse der Audiomodelle von OpenAI
Um die Leistung seiner neuesten Sprach-Textual content-Modelle zu bewerten, führte OpenAI Benchmark-Exams unter Verwendung der Wortfehlerrate (WER) durch, einer Standardmetrik in der Spracherkennung. Wer misst die Transkriptionsgenauigkeit durch Berechnung des Prozentsatzes der falschen Wörter im Vergleich zu einem Referenztranskript. Eine niedrigere Had been zeigt eine bessere Leistung mit weniger Fehlern an.

Wie die Ergebnisse zeigen, bieten die neuen Sprach-zu-Textual content-Modelle-GPT-4O-Transcribe und GPT-4O-Mini-Transcribe-im Vergleich zu früheren Modellen wie Whisper verbesserte Wortfehlerraten und verbesserte Spracherkennung.
Leistung bei Fleurs Benchmark
Eines der wichtigsten Benchmarks ist Fleurs (wenige Schuss-Lernbewertung von universellen Repräsentationen von Sprach), ein mehrsprachiger Sprachdatensatz, der über 100 Sprachen mit manuell transkribierten Audio-Samples abdeckt.

Die Ergebnisse zeigen, dass die neuen Modelle von Openai:
- Erreichen Sie niedrigere Had been in mehreren Sprachen und zeigen Sie eine verbesserte Transkriptionsgenauigkeit.
- Zeigen Sie eine stärkere mehrsprachige Abdeckung, wodurch sie für verschiedene sprachliche Anwendungen zuverlässiger werden.
- Übertreffen Sie Whisper V2 und Whisper V3, OpenAs Modelle der vorherigen Technology, in allen bewerteten Sprachen.
Kosten für Openai -Audiomodelle

Abschluss
Die neuesten Audio-Modelle von OpenAI sind eine signifikante Verschiebung von rein textbasierten Agenten zu hoch entwickelten Sprachmitteln, wodurch die Lücke zwischen KI und menschlicher Wechselwirkung überbrückt. Diese Modelle verstehen nicht nur, was sie sagen sollen – sie verstehen, wie man es sagt, und erfassen Ton, Tempo und Emotionen mit bemerkenswerter Präzision. OpenAI bietet Entwicklern sowohl Sprach- und Textual content- als auch Textual content-zu-Sprach-Funktionen, die sich natürlicher und ansprechender anfühlen.
Die Verfügbarkeit dieser Modelle über API bedeutet, dass Entwickler jetzt eine höhere Kontrolle über den Inhalt und die Bereitstellung von AI-generierten Sprache haben. Darüber hinaus erleichtert die Agenten von OpenAI, SDK, die traditionellen textbasierten Agenten in voll funktionsfähige Sprachagenten einfacher und eröffnen neue Möglichkeiten für Kundendienst, Zugänglichkeitstools und Echtzeit-Kommunikationsanwendungen. Während OpenAI seine Sprachtechnologie weiter verfeinert, setzen diese Fortschritte einen neuen Normal für KI-betriebene Interaktionen.
Häufig gestellte Fragen
A. OpenAI hat drei neue Audiomodelle eingeführt-GPT-4O-Transcribe, GPT-4O-Mini-Trancribe und GPT-4O-Mini-TTs. Diese Modelle sind so konzipiert, dass sie Sprach-Textual content- und Textual content-to-Speech-Funktionen verbessern und genauere Transkriptionen und natürliche Sprache ermöglichen.
A. Im Vergleich zu den Flüstern von Openai bieten die neuen GPT-4O-Audiomodelle eine verbesserte Transkriptionsgenauigkeit und niedrigere Wortfehlerraten. Es bietet auch eine verbesserte mehrsprachige Unterstützung und eine bessere Reaktionsfähigkeit in Echtzeit. Darüber hinaus bietet das Textual content-to-Speech-Modell eine natürlichere Sprachmodulation, mit der Benutzer Ton, Stil und Tempo für lebensechendere Sprache für lebensechtere AI-generierte AI-generierte Anpassung anpassen können.
A. Mit dem neuen TTS -Modell können Benutzer Sprache mit anpassbaren Stilen, Tönen und Tempo generieren. Es verbessert die menschliche Sprachmodulation und unterstützt vielfältige Anwendungsfälle, von AI-Sprachassistenten bis hin zu Hörbucherzählung. Das Modell bietet auch einen besseren emotionalen Ausdruck und Klarheit als frühere Iterationen.
A. GPT-4O-transkribe bietet branchenführende Transkriptionsgenauigkeit und sorgt für professionelle Anwendungsfälle wie Erfüllung von Transkriptionen und Kundendienstprotokollen excellent. GPT-4O-Mini-Trancribe ist für Effizienz und Geschwindigkeit optimiert und bietet Echtzeitanwendungen wie Reside-Bildunterschriften und interaktive AI-Agenten.
A. openai.fm ist eine Webplattform, auf der Benutzer das Textual content-to-Speech-Modell von OpenAI ohne Anmeldung testen können. Benutzer können eine Stimme auswählen, den Ton anpassen, ein Skript eingeben und Audio sofort generieren. Die Plattform bietet auch den zugrunde liegenden API -Code für die weitere Anpassung.
A. Ja, OpenAIs Agenten SDK unterstützt jetzt Audio und ermöglicht es Entwicklern, textbasierte Agenten in interaktive Sprachagenten umzuwandeln. Dies erleichtert die Erstellung von Bots, Barrierefreiheit und personalisierten KI-Assistenten mit KI-betriebenen Kundenunterstützung mit fortschrittlichen Sprachfunktionen.
Sabreena ist Genai -Enthusiastin und Tech -Redakteurin, die sich leidenschaftlich darum kümmern, die neuesten Fortschritte zu dokumentieren, die die Welt prägen. Derzeit erkundet sie die Welt der KI und Information Science als Managerin für Inhalt und Wachstum bei Analytics Vidhya.
Melden Sie sich an, um weiter zu lesen und Experten-Kuratinhalte zu genießen.