

# Einführung
Ein Modell, das sagt, dass es sich zu 90 % sicher ist, sollte in 90 % der Fälle Recht haben. Wenn diese Beziehung zerbricht, bekommen Sie eine Fehlkalibrierung Drawback. Die Ergebnisse des Modells sagen nichts Nützliches über die Zuverlässigkeit aus.
Für große Sprachmodelle (LLMs) sind Fehlkalibrierungen weit verbreitet. A NAACL-Umfrage 2024 fanden heraus, dass die Konfidenzwerte bei sachlicher Qualitätssicherung, Codegenerierung und Argumentationsaufgaben von den tatsächlichen Korrektheitsraten abweichen.
Ein anderer Studie Bei biomedizinischen Modellen wurden bei allen getesteten Modellen mittlere Kalibrierungswerte zwischen nur 23,9 % und 46,6 % festgestellt. Der Abstand ist konstant.
Die Standardlösung in klassisches maschinelles Lernen ist eine Publish-hoc-Neukalibrierung: Passen Sie eine einfache Funktion an einen zurückgehaltenen Validierungssatz an, um rohe Konfidenzwerte besser kalibrierten Wahrscheinlichkeiten zuzuordnen.
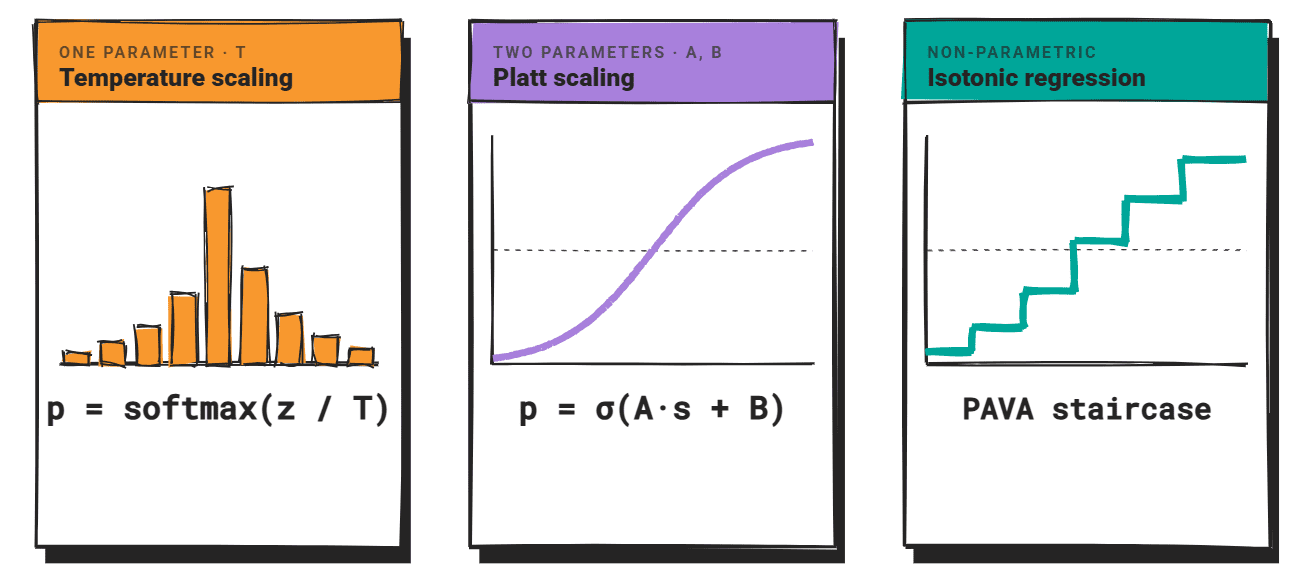
Drei Methoden dominieren: Temperaturskalierung, Platt-SkalierungUnd isotonische Regression. Alle drei wurden für entwickelt diskriminierende Klassifikatorenund ihre Anwendung auf LLMs erfordert Sorgfalt.
# Messkalibrierung
Die vorherrschende Metrik ist Erwarteter Kalibrierungsfehler (ECE). Es gruppiert Vorhersagen in Konfidenzklassen, berechnet die Lücke zwischen der mittleren Konfidenz und der beobachteten Genauigkeit in jeder Klasse und ermittelt den nach Größe gewichteten Durchschnitt über die Klassen. ECE = 0 ist eine perfekte Kalibrierung.
Ein Zuverlässigkeitsdiagramm stellt das Vertrauen gegenüber der Genauigkeit dar. Auf der Diagonale steht ein perfekt kalibriertes Modell. Darunter liegt ein zu selbstbewusstes Modell: Die Kurve zeigt ein hohes Vertrauen, aber die Genauigkeit hält nicht mit.
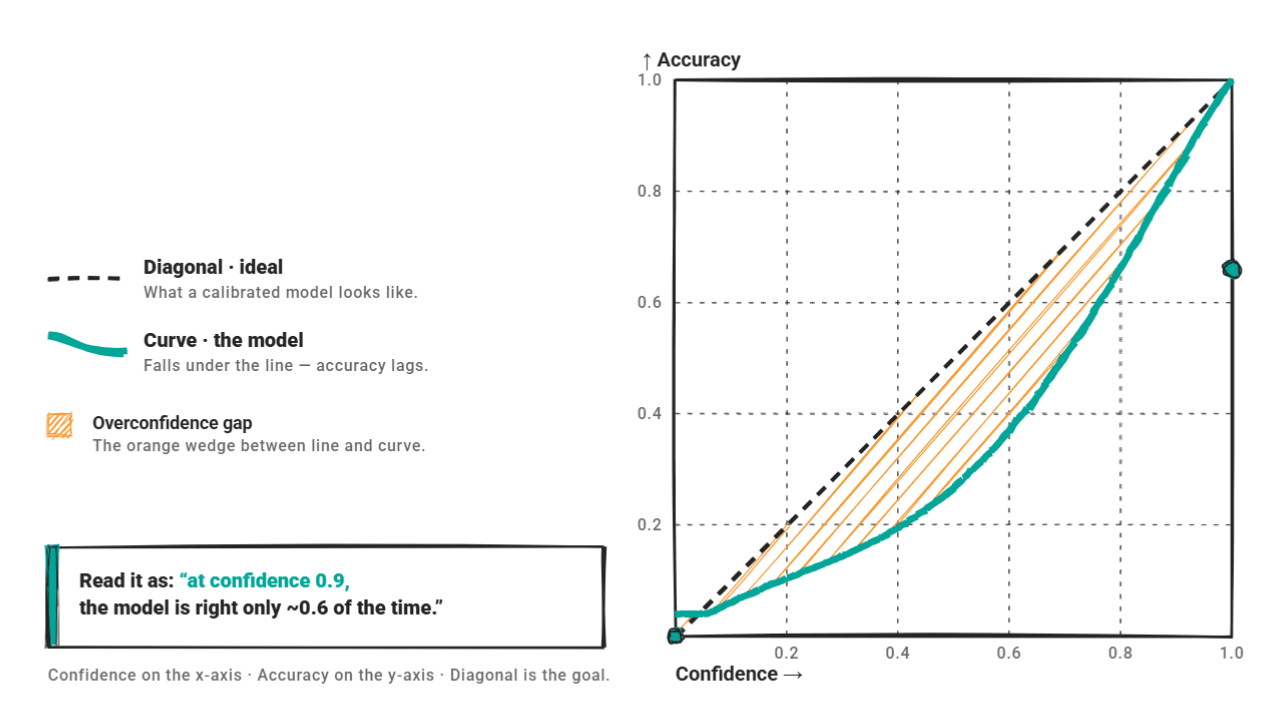
A Auswertung 2025 Die Verwendung von GPT-4o-mini als Textklassifizierer ergab, dass 66,7 % der Fehler bei einer Konfidenz von über 80 % auftraten – dem kanonischen Muster der Überkonfidenz.
ECE allein wird zunehmend als unzureichend angesehen. A Forschungsarbeit empfiehlt die Kombination von ECE mit dem Brier-RatingÜbervertrauensraten und Zuverlässigkeitsdiagramme zusammen. Eine einzelne Zahl verschleiert sinnvolle Unterschiede darin, wo und wie sich ein Modell schlecht verhält.
# Warum LLMs das Customary-Setup erschweren
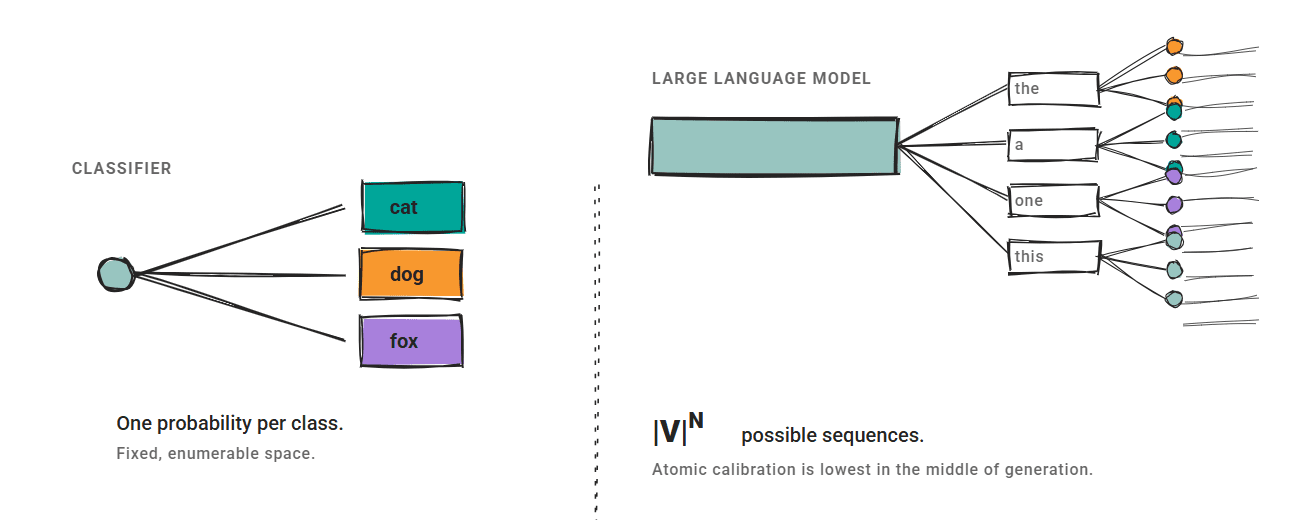
Die drei von uns behandelten Methoden gehen von einem festen Ausgaberaum aus. Ein Klassifikator erzeugt einen Wahrscheinlichkeit professional Klasse, und die Kalibrierung ordnet sie besseren Schätzungen zu.
LLMs funktioniert nicht so.
Hier spielen vier Komplikationen eine Rolle.
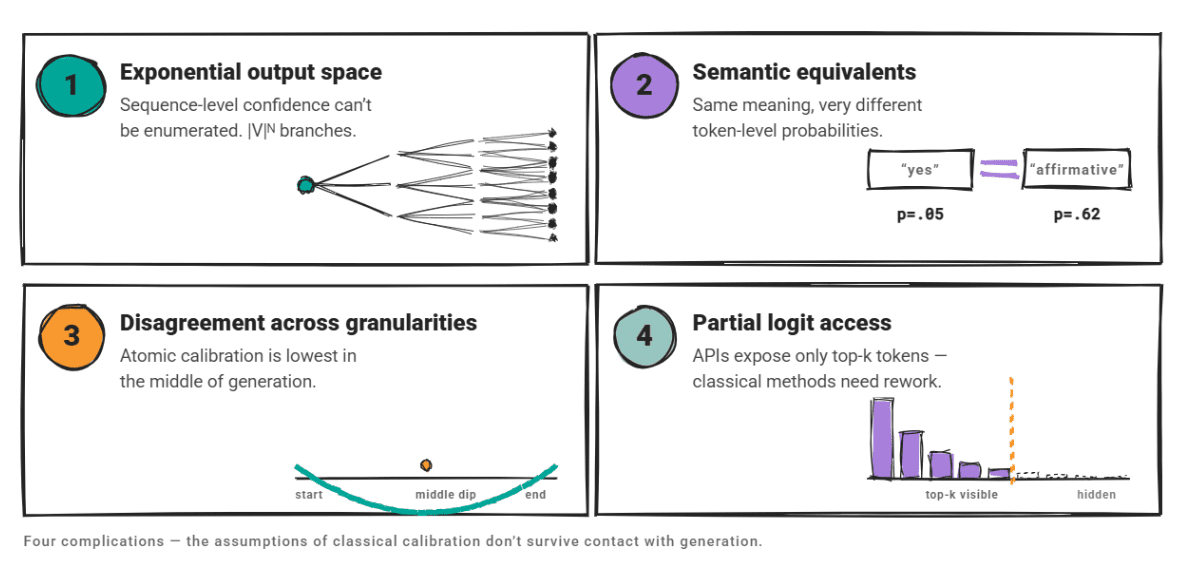
Der Ausgaberaum ist exponentiell groß: Die Konfidenz auf Sequenzebene kann nicht aufgezählt werden. Semantisch äquivalente Ausgaben können sehr unterschiedliche Wahrscheinlichkeiten auf Token-Ebene haben. Das Vertrauen ist in allen Granularitäten unterschiedlich; A Forschungsarbeit Untersuchungen zur atomaren Kalibrierung zeigten, dass generative Modelle ihr niedrigstes durchschnittliches Vertrauen in der Mitte der Era aufweisen, nicht zu Beginn oder am Ende.
Und viele LLMs legen durch ihre nur High-Okay-Token-Wahrscheinlichkeiten offen APIDaher müssen klassische Kalibrierungsansätze, die auf vollständigem Logit-Zugriff basieren, geändert werden.
# Anwenden der Temperaturskalierung
Bei der Temperaturskalierung wird der Logit-Vektor durch einen Skalar T dividiert, bevor Softmax angewendet wird. Wenn T > 1, flacht die Verteilung ab und das Vertrauen sinkt. Wenn T < 1, wird die Verteilung schärfer und das Vertrauen steigt.
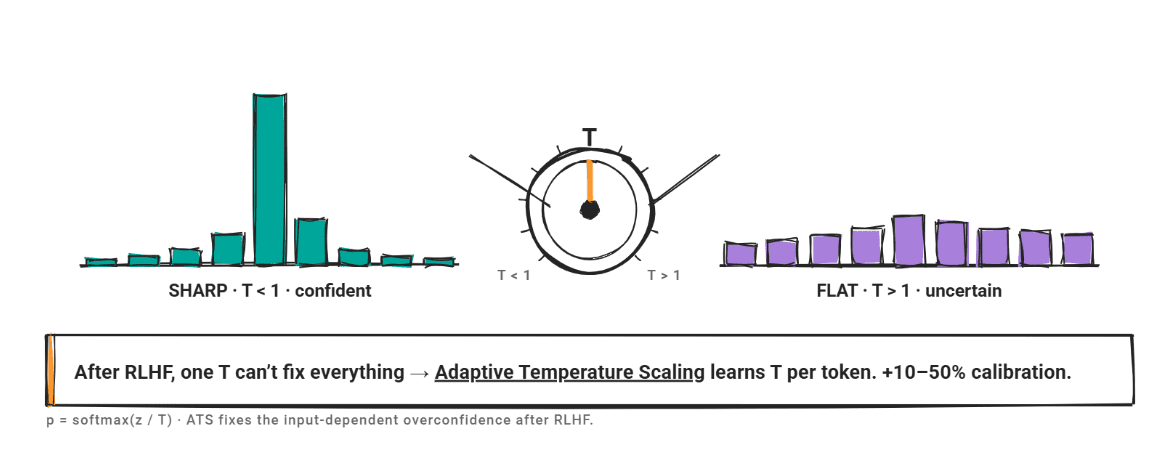
T wird an einen ausgehaltenen Validierungssatz angepasst, indem die adverse Log-Probability minimiert wird. Die Methode fügt einen Parameter hinzu, behält die Vorhersagerankings bei und ist kostengünstig zu berechnen.
Der Originalformulierung gezielte DenseNet-Bildklassifikatoren. Bei LLMs steuert die Temperatur die Wahrscheinlichkeitsverteilung über das Vokabular bei jedem Decodierungsschritt, sodass dieselbe Logik gilt.
Das Drawback ist Verstärkung des Lernens aus menschlichem Suggestions (RLHF). Publish-RLHF-Modelle entwickeln ein eingabeabhängiges Übervertrauen: Der Grad der Fehlkalibrierung variiert je nach Eingabe, und ein einzelnes T kann diese Variation nicht erklären.
Durchschnittliche ECE-Werte über 0,377 wurden für Modelle wie GPT-3 in verbalen Konfidenzaufgaben dokumentiert, und a Umfrage 2025 bestätigt, dass RLHF-abgestimmte Modelle das Vertrauen auf ganzer Linie durchweg überschätzen.
Adaptive Temperaturskalierung (ATS) befasst sich direkt damit. ATS prognostiziert eine Temperatur professional Token anhand versteckter Funktionen auf Token-Ebene und passt sie an einen überwachten Feinabstimmungsdatensatz an, anstatt ein einzelnes festes T zu verwenden. Forscher bestätigten, dass ATS die Kalibrierung um 10–50 % verbesserte, ohne die Aufgabenleistung zu beeinträchtigen. Für jedes RLHF-abgestimmte Modell ist ATS eine stärkere Basislinie als die Standardtemperaturskalierung.
Die Standardtemperaturskalierung funktioniert für Basismodelle vor RLHF immer noch intestine. Wenn die Fehlkalibrierung über alle Eingaben hinweg ungefähr einheitlich ist, reicht oft ein einziges T aus, um systematisches Über- oder Untervertrauen zu korrigieren.
Das Drawback ist spezifisch für Publish-RLHF-Modelle, bei denen eine eingabeabhängige Überkonfidenz dazu führt, dass ein einzelnes T nicht alle Eingaben korrigieren kann.
# Anwenden der Platt-Skalierung
Die Platt-Skalierung passt eine logistische Funktion an die nicht kalibrierten Bewertungen an: p = σ(A·s + B), wobei A und B aus einem zurückgehaltenen Validierungssatz mit binären Korrektheitsbezeichnungen gelernt werden.
Die Sigmoidform ergibt eine parametrische Abbildung mit zwei freien Parametern.
Die Platt-Skalierung wurde ursprünglich für SVMs entwickelt, lässt sich jedoch auf jedes System verallgemeinern, das einen skalaren Konfidenzwert erzeugt.
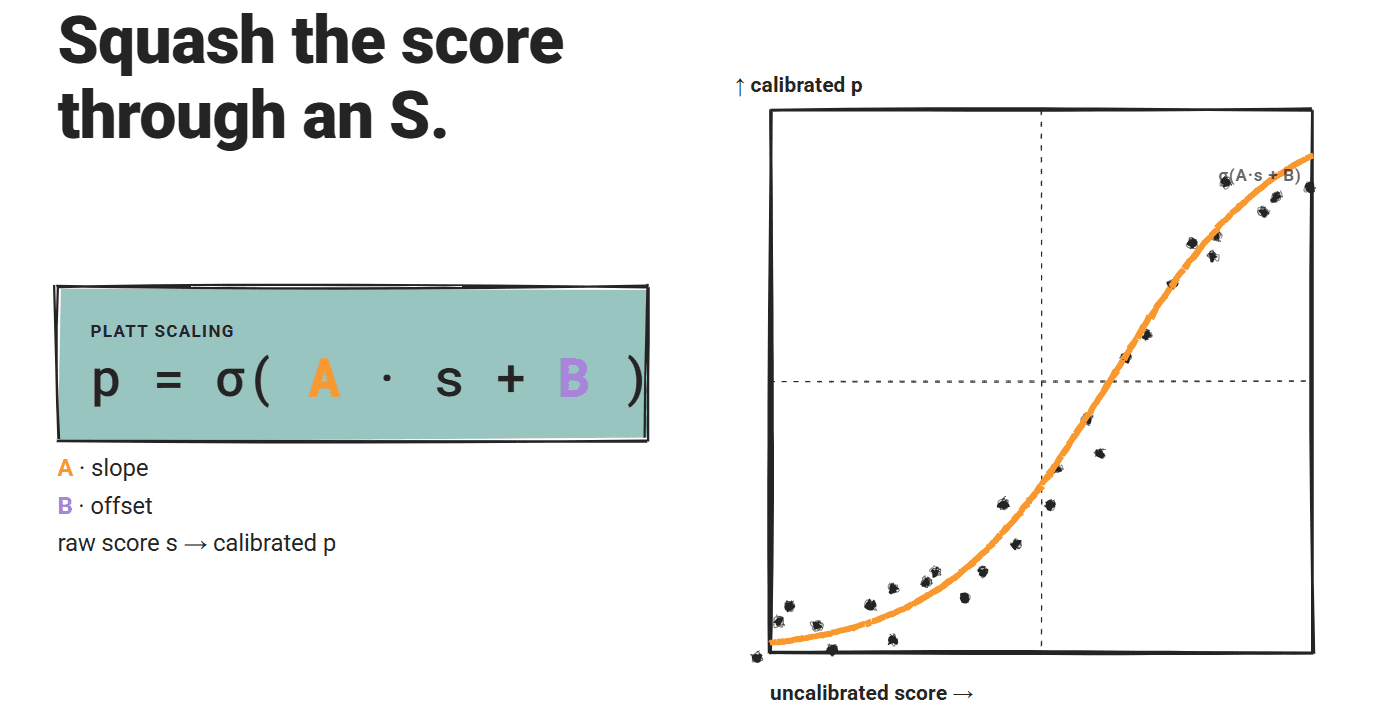
Die Zwei-Parameter-Anpassung ist im Vergleich zur isotonischen Regression auch dateneffizient: Sie kann brauchbare Schätzungen aus einem kleineren Kalibrierungssatz erstellen, was in Bereitstellungskontexten wichtig ist, in denen die gekennzeichneten Korrektheitsdaten begrenzt sind.
In LLM-Kontexten erfolgt die Platt-Skalierung über Konfidenzwerte auf Sequenzebene oder Tokenebene.
A Papier Untersuchungen zur Zuverlässigkeit von LLM-generiertem Code ergaben, dass die Platt-Skalierung besser kalibrierte Ergebnisse lieferte als unkalibrierte Ergebnisse. Eine weitere Studie zu LLMs für Textual content-to-SQL wurde vorgestellt Multivariate Platt-Skalierung (MPS) und erweitert die Platt-Skalierung mit einer Variablen, um Unterabschnittshäufigkeitsscores über mehrere generierte Stichproben hinweg zu kombinieren – und übertrifft so durchweg die Single-Rating-Basislinien.
Zwei Einschränkungen werden dokumentiert. Erstens ist die globale Platt-Skalierung auf Sequenzebene zu grob für Aufgaben, bei denen die Korrektheit von lokalen Bearbeitungsentscheidungen abhängt: Eine einzelne Sigmoid-Zuordnung kann keine probenabhängigen Fehlkalibrierungsmuster erfassen.
Außerdem kann die Platt-Skalierung die korrekte Bewertungsleistung für starke Modelle beeinträchtigen.
# Anwendung der isotonischen Regression
Die isotonische Regression nimmt den nichtparametrischen Weg.
Es lernt eine stückweise konstante, monoton nicht abnehmende Zuordnung von unkalibrierten Bewertungen zu kalibrierten Wahrscheinlichkeiten unter Verwendung von Pool Adjoining Violators-Algorithmus (PAVA). Es gibt keine angenommene Type für die Kalibrierungsfunktion, wodurch sie flexibler ist als die Platt-Skalierung, wenn die Konfidenz-Genauigkeits-Beziehung nicht sigmoidförmig ist.
Die stückweise konstante Ausgabe passt sich jeder monotonen Type an: linear, gestuft oder konkav. Diese Anpassungsfähigkeit ist der Hauptgrund dafür, dass die isotonische Regression in empirischen Vergleichen tendenziell die Platt-Skalierung übertrifft.
Bei kleinen Kalibrierungssätzen besteht das Risiko einer Überanpassung. Die Zuordnung lässt sich nur dann intestine verallgemeinern, wenn genügend Daten vorhanden sind, um sie einzuschränken.
Empirisch gesehen übertrifft die isotonische Regression die Platt-Skalierung.
Eine strenge Vergleich Über mehrere Datensätze und Architekturen hinweg wurde festgestellt, dass die isotonische Regression die Platt-Skalierung beim ECE- und Brier-Rating mit statistischer Signifikanz übertrifft, wobei gepaarte t-Assessments mit Bonferroni-Korrektur bei α = 0,003 verwendet wurden.
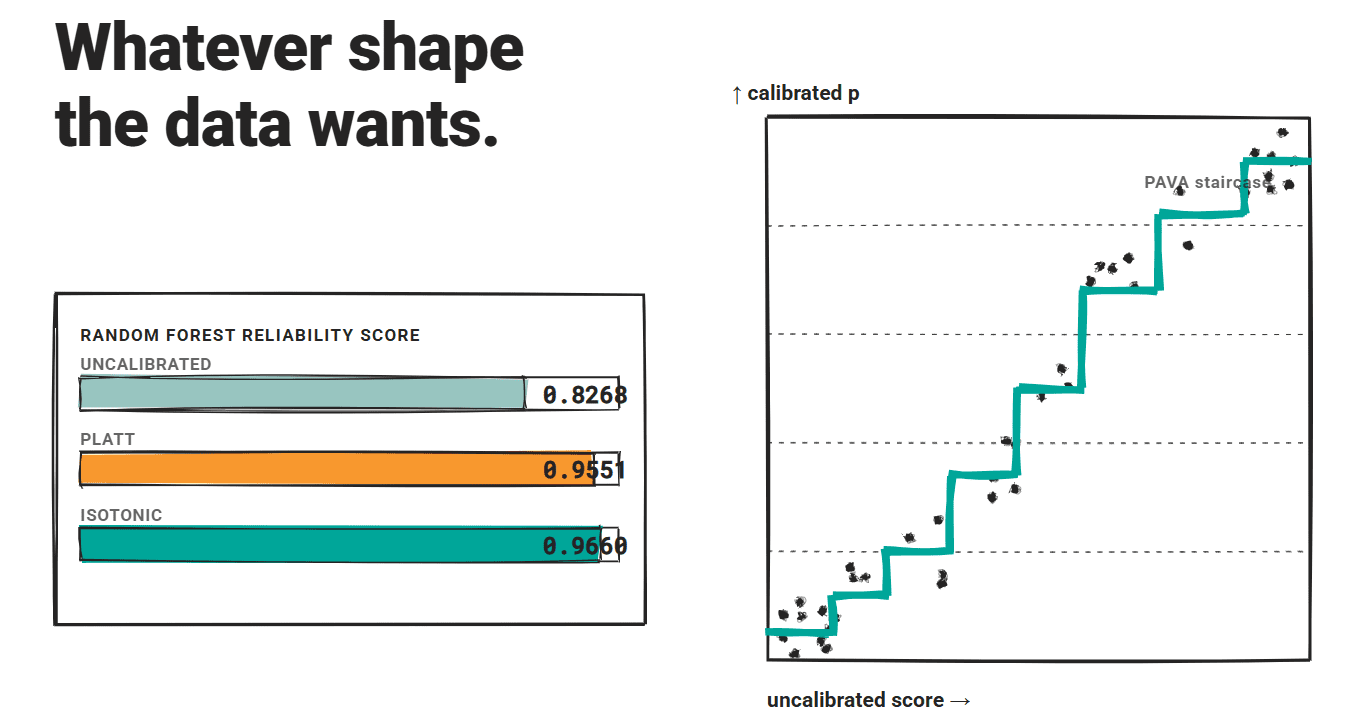
In dieser Studie verbesserte sich eine Random Forest-Basislinie von einem Zuverlässigkeitswert von 0,8268 unkalibriert auf 0,9551 mit Platt-Skalierung und auf 0,9660 mit isotonischer Regression. Beide Methoden könnten die korrekte Bewertungsleistung für starke Modelle beeinträchtigen, aber der isotonische Vorteil blieb konstant bestehen.
Für LLM-Mehrklasseneinstellungen hat sich gezeigt, dass die standardmäßige isotonische Regression mit normalisierungsbewussten Erweiterungen weiter verbessert werden kann und sowohl die isotonische OvR-Regression als auch die standardmäßigen parametrischen Methoden für NLL und ECE durchweg übertrifft.
Die Datenanforderung ist die Bindungsbeschränkung. Der Vorteil der isotonischen Regression ist actual, lässt sich jedoch nicht auf Bereitstellungsszenarien mit wenig Daten übertragen.
# Was die Literatur offen lässt
Drei Lücken Es lohnt sich, sie zu kennzeichnen, bevor Sie eine dieser Methoden einsetzen.
Der RLHF Die Wechselwirkung wurde nur für die Temperaturskalierung untersucht. Wie Platt-Skalierung und die Leistung der isotonischen Regression bei Publish-RLHF-Modellen wurde nicht systematisch getestet. ATS existiert, weil die Customary-Temperaturskalierung für diesen Fall eine explizite Korrektur erforderte. Ob die beiden anderen Methoden ähnliche Erweiterungen benötigen, ist eine offene Frage.
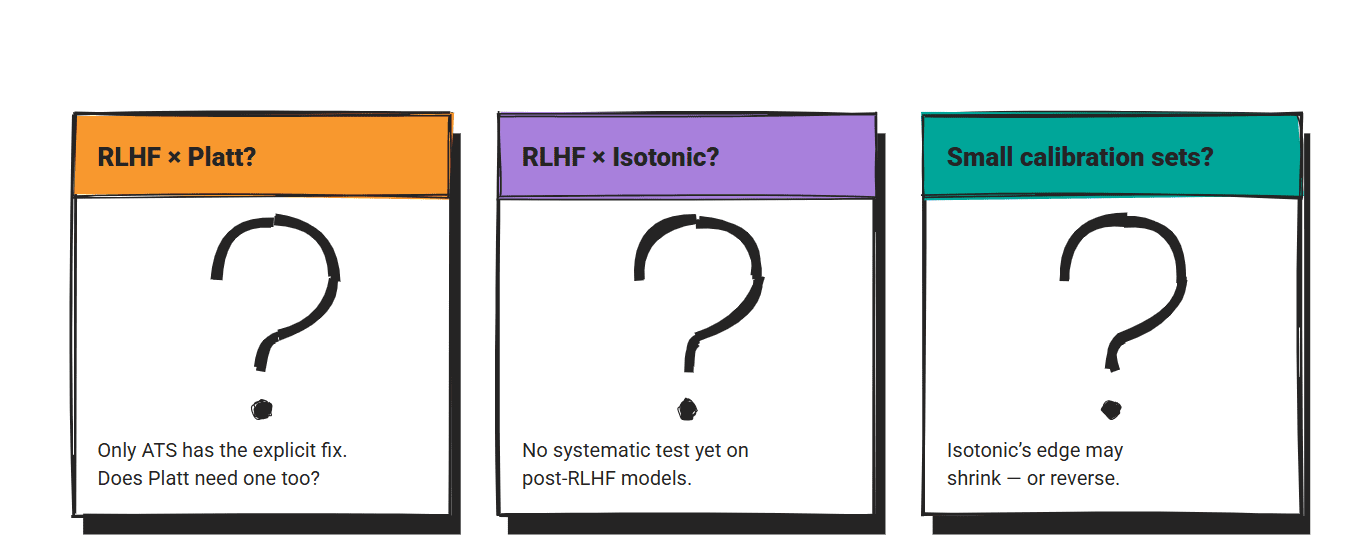
Am direktsten Vergleiche Alle drei Methoden stammen aus der allgemeinen Literatur zur Kalibrierung maschinellen Lernens. LLM-spezifische Benchmarks, die alle drei im direkten Vergleich testen, sind selten. Die ICSE 2025-Codekalibrierung Papier ist einer der wenigen und sein Anwendungsbereich beschränkt sich auf die Codegenerierung.
Die Größe des Kalibrierungssatzes ist eine echte Einschränkung bei der Bereitstellung. Ergebnisse der isotonischen Regression aus Veröffentlichungen gehen davon aus, dass Datensätze groß genug sind, um die Kartierung einzuschränken. Bei der Produktion mit begrenzten beschrifteten Beispielen kann sich die Lücke zwischen isotonischer Regression und Platt-Skalierung schließen oder umkehren.
# Abschluss
Temperaturskalierung ist für die meisten Groups der richtige Ausgangspunkt. Bei Basismodellen ohne RLHF reicht oft ein einzelnes T.
Für RLHF-Abgestimmte Modelle, wechseln Sie zu ATS: Die Temperatur professional Token verarbeitet die eingabeabhängige Übersicherheit, die ein globaler Skalar übersieht.
Platt-Skalierung ist die praktische Wahl, wenn das Kalibrierset klein ist oder die Kalibrierung in eine größere Rohrleitung integriert werden muss. Es ist dateneffizient und einfach zu implementieren. Die Einschränkung liegt im Umfang: Fehlkalibrierungen, die von Probe zu Probe unterschiedlich sind, können nicht erfasst werden, und bei starken Modellen verschlechtert sich tendenziell die Leistung.
Isotonische Regression hat die stärkste empirische Erfolgsbilanz der drei. Verwenden Sie es, wenn der Kalibrierungssatz groß genug ist, um die Zuordnung ohne Überanpassung einzuschränken, und kombinieren Sie es mit normalisierungsfähigen Erweiterungen in Mehrklasseneinstellungen.
Die Entscheidung, die vor all diesen Punkten steht, ist die „Vertrauen“ bedeutet für die Aufgabe. Token-Wahrscheinlichkeit, Sequenzwahrscheinlichkeit, verbale Konfidenz und Konsistenz über Proben hinweg können unterschiedliche Werte für die gleiche Ausgabe ergeben. Eine auf das falsche Sign angewendete Kalibrierungsmethode verbessert die Zuverlässigkeit nicht. Die richtige Definition ist die Voraussetzung dafür, dass eine der oben genannten Methoden funktioniert.
Nate Rosidi ist Datenwissenschaftler und in der Produktstrategie tätig. Er ist außerdem außerordentlicher Professor für Analytik und Gründer von StrataScratch, einer Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von High-Unternehmen auf ihre Interviews vorzubereiten. Nate schreibt über die neuesten Developments auf dem Karrieremarkt, gibt Ratschläge zu Vorstellungsgesprächen, stellt Knowledge-Science-Projekte vor und behandelt alles rund um SQL.