Das ist Jessica. Ich habe zuvor einige geschrieben Beiträge, die darüber nachdenken Konforme Vorhersage Als Entscheidungshilfe. Ein Teil dessen, was mich als Methode zur Quantifizierung der Unsicherheit interessierte, ist die Spannung zwischen der Ansicht, wie Vorhersagesätze für Entscheidungsträger intuitiver oder konkreter erscheinen (im Vergleich zur Bereitstellung einer Pseudoverbotbarkeit, dass eine Vorhersage wie ein Softmax-Wert korrekt ist), aber andererseits unklar, was der typische, theoretische Nutzungsagent für den theoretischen Nutzmittel mit einem Konformitätsprofotionsprofotionsprofotionsprofotionsprofotionsprofotionsprofotierungspflicht ist. Jetzt habe ich ein Papier geschrieben, das darüber nachgedacht wird.
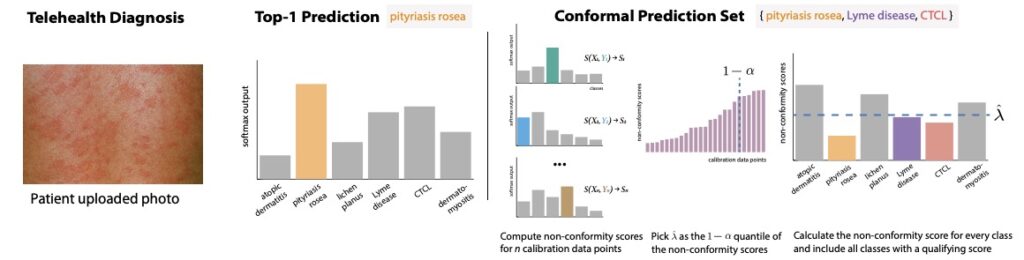
Als kurze Erinnerung daran, welche konforme Vorhersage in einer Klassifizierungsumgebung ist, dauert die spaltete konforme Vorhersage eine Instanz (z. B. einige Patientensymptome in einem Beispiel für medizinische Diagnose) und generiert einen Vorhersagesatz, der eine Reihe von Bezeichnungen enthält, die das wahre Etikett mit einer benutzerdefinierten Wahrscheinlichkeit 1-Alpha enthalten. In der Regel wird diese Abdeckung voraussichtlich nur geringfügig über die Zufälligkeit in den Daten hält.
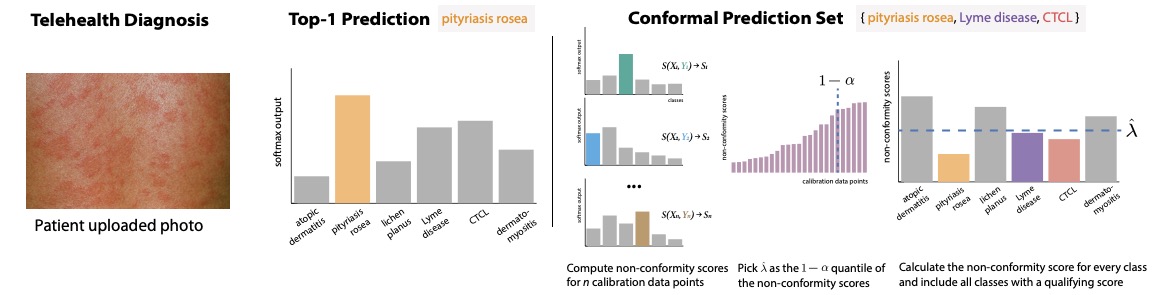
Um Vorhersagesätze zu generieren, nehmen wir einige gehaltene markierte Daten (die sich von den Modelltrainings- oder Testsätzen unterscheiden) und für jeden Fall in diesem Kalibrierungssatz nehmen wir den Wert eines heuristischen Maßes für die Vorhersageunsicherheit, die unser Modell für das wahre Etikett für das wahre Etikett liefert (dies könnte, eine Softmax-Punktzahl aus dem endgültigen Schicht eines neuralen Netzes, ein Restbetrag und eine Residual-Ein-Regression). Wir konvertieren dies in eine Nicht-Konformitätsbewertung, dh eine Punktzahl, die größere Werte aufnimmt, wobei das Etikett das von dem Modell gelernt ist. Zum Beispiel könnte die Punktzahl so einfach sein wie 1 – Softmax (y) für Etikett y. Anschließend berechnen wir das 1-Alpha-Quantil der Nicht-Konformitätswerte für die wahren Etiketten im Kalibrierungssatz. Bei einer neuen Instanz verwenden wir dieses 1-Alpha-Quantil als Schwellenwert, einschließlich des Vorhersage-Set alle Etiketten mit Nicht-Konformitätswerten weniger als der Schwellenwert.
Yifan Wu, Dawei Xie, Ziyang Guo, Andrew und ich schreiben:
Methoden zur Quantifizierung der Unsicherheit bei Vorhersagen aus willkürlichen Modellen sind in hohen Einsätzen wie Medizin und Finanzen nachgefragt. Die konforme Vorhersage hat sich zu einer beliebten Methode zur Herstellung einer Reihe von Vorhersagen mit einer bestimmten Abdeckung anstelle einer einzelnen Prime -Vorhersage und eines Konfidenzwerts entwickelt. Der Wert der konformen Vorhersagesätze zur Unterstützung menschlicher Entscheidungen bleibt jedoch aufgrund der trüben Beziehung zwischen Deckungsgarantien und Zielen und Strategien der Entscheidungsträger schwer fassbar. Wie sollten wir über konforme Vorhersagessätze als eine Kind der Entscheidungsunterstützung nachdenken? Wir skizzieren einen theoretischen Entscheidungsrahmen für die Bewertung der prädiktiven Unsicherheit als informative Signale und kontrastieren dann, was in diesem Rahmen über die idealisierte Verwendung kalibrierter Wahrscheinlichkeiten im Vergleich zu konformen Vorhersagesätzen gesagt werden kann. Nach früheren empirischen Ergebnissen und Theorien der menschlichen Entscheidungsfindung im Rahmen von Unsicherheit werden wir eine Reihe möglicher Strategien formalisiert, mit denen ein Entscheidungsträger einen Vorhersagesatz verwenden könnte. Wir ermitteln, wie konforme Vorhersagesätze und die Quantifizierung der post-hoc-Vorhersageunsicherheit im weiteren Sinne die Spannung mit den gemeinsamen Zielen und Bedürfnissen bei der Entscheidungsfindung von Human-AI entsprechen. Wir geben Empfehlungen für zukünftige Forschungsergebnisse zur Quantifizierung der Vorhersageunsicherheit zur Unterstützung menschlicher Entscheidungsträger.
Was könnten Entscheidungsträger mit Vorhersagesätzen tun?
In der Arbeit kontrastieren wir die Vorhersageunsicherheit, die eine genau definierte Verwendung durch einen verlustminimierenden rationalen Entscheidungsträger hat (wie z. Unser Ziel ist es, verschiedene Strategien zu charakterisieren, die Entscheidungsträger anwenden könnten. Einige davon sind in der Literatur anekdotisch aufgetaucht oder wurden von Teilnehmern in Studien erwähnt, die wir durchgeführt, aber nicht formalisiert sind.
Zum Beispiel haben Entscheidungsträger berichtet, dass sie eine Vorhersage zur Überprüfung ihrer eigenen Urteile verwendet haben. Wenn wir davon ausgehen, dass der Entscheidungsträger eine vorherige Wahrscheinlichkeitsverteilung über Etiketten (P (y)) hat, kann der Entscheidungsträger für jedes möglicherweise label y eine Vorhersage C_HAT (x) sehen, und kann für jedes möglicherweise label y ihre glaubwürdige aktualisieren, indem er feststellt, ob das label im set ist, falls seine vorherigkeit zu normalisieren, dann multiplizieren sie mit einem 1-alpha (wenn in set) oder alpa (falls) (wenn nicht). Dh die hintere Wahrscheinlichkeit für alle Etiketten im Satz c_hat (x) wird (1-alpha) * p (y)/(sum von p (y ‚) für alle y‘ in c_hat (x)). Für Beschriftungen, die nicht im Set sind, ersetzen wir (1-Alpha) durch Alpha und normalisieren die vorherige Wahrscheinlichkeit jedes Etiketts durch die Summe der Wahrscheinlichkeiten aller Labels, die nicht im Satz sind.
Einige Entscheidungsträger verwenden jedoch stattdessen Sätze, um ihre Entscheidungen einzuschränken, z. Die einfachste Strategie für diese Artwork von Entscheidungsträger wäre es, die Wahrscheinlichkeit zu gleichermaßen auf alle Etiketten im Set zu teilen und allen Labels, die nicht im Set nicht sind, keine Wahrscheinlichkeit zuzuweisen. Wir können uns jedoch auch ausgefeiltere Strategien vorstellen, beispielsweise die Erfassung der Instinct, dass Vorhersagesätze die „kognitiven Kosten“ für eine Entscheidung verringern. Hier können wir uns auf ein rationales Unaufmerksamkeitsmodell für die Wirtschaftswissenschaften befassen, bei dem das Ziel des Entscheidungsträgers darin besteht, die Maßnahmen zu finden, die den Verlust minimiert, der eine Strafzeit für die Kosten des Informationserwerbs darstellt (was in diesem Fall die mit der Berücksichtigung eines Etiketts verbundenen Aufmerksamkeitskosten sind).
Wir können uns auch Variationen der Verifizierung und Einschränkung von Strategien vorstellen, bei denen Entscheidungsträger Labels als eine ähnliche Ähnlichkeitsverhältnis über sie wahrnehmen. Dies wurde von Studienteilnehmern in berichtet unsere empirische Arbeit und so intestine wie in Jüngste Arbeiten zu entscheidungsorientierten Vorhersagesätzen. Erkrankungen können auf der Grundlage der ähnlichen Behandlungen oder Risikoniveaus in Verbindung gebracht werden. Etiketten für Objekte, die in Bildern erscheinen, können mit semantischen Ontologien wie der WordNet -Hierarchie verwandt werden. Wahrgenommene Ähnlichkeiten zwischen den Etiketten können die Artwork und Weise berücksichtigen, wie der Entscheidungsträger Sätze verwendet oder ihnen Wert zuweist. Angesichts einer gewissen Ähnlichkeitsfunktion über Bezeichnungen kann der Entscheidungsträger beispielsweise die Wahrscheinlichkeit von Etiketten „übertragen“, die im SET zu ähnlichen Beschriftungen erscheinen, die dies nicht tun.
Kurz bevor ich dieses Papier veröffentlichen wollte Papier, in dem die Artwork von Entscheidungsprozess die Vorhersage befragt, ist der richtige Weg, um Unsicherheit zu kommunizieren. Sie zeigen, dass, wenn Sie ein Risikoaver (im Gegensatz zu einem Risikoneutral) für den Entscheidungsträger haben, der versucht, ihren Mindestnutzen trotz der Unklarheit über die Datenschonerierungsverteilung zu maximieren, eine Maxim-Minen-Regel ist eine optimale Strategie für die Verwendung von Vorhersagesätzen mit marginaler Abdeckung, wobei der Entscheidungshersteller die Aktion, die ihren Nutzen in der Kennzeichnung über das Kennzeichen maximiert. Sie zeigen auch etwas überraschend, dass Vorhersagesätze alle Informationen enthalten, die für diese Artwork von risikoaversen Entscheidungsfindung erforderlich sind.
In Frage stellen die üblichen Beschränkungen des Kenntnisses des Entscheidungsträgers
Eine andere Sache, die wir diskutieren, ist, wie häufige Gründe für die Einbeziehung menschlicher Entscheidungsträger in erster Linie das Ziel erschweren, gültige Unsicherheitsschätzungen zu erstellen. Wir zögern oft, menschliche Entscheidungsträger vollständig durch statistische Modelle zu ersetzen, da wir glauben, dass sie über ein wertvolles Wissen verfügen, um die für das Modell zur Verfügung stehenden Informationen beizutragen. Das Drawback ist, dass, wenn wir dem Entscheidungsträger zulassen, möglicherweise Zugriff auf einige non-public Informationen zu haben, die dem Modell nicht zur Verfügung stehen, und nach allem, was wir wissen, kann die kalibrierte Unsicherheitsquantifizierung, die wir so sorgfältig versuchen, die falschen Informationen zu ermöglichen. Siehe zum Beispiel Diese Demonstration von Corvelo Benz und Rodriguez Wie eine kalibrierte Modellwahrscheinlichkeit dem Entscheidungsträger möglicherweise nicht dabei hilft, Zugang zu privaten Informationen zu erhalten, optimieren Sie ihre Auswahl der Handlungen. Diese Spannung wird in theoretischen und algorithmischen Informatikforschung zur Quantifizierung der Unsicherheit selten anerkannt. Daher widmen wir einen Teil unseres Papiers der Ausrichtung des Issues.
Möglichkeiten, die konforme Vorhersage besser mit dem auszurichten, was wir über menschliche Entscheidungen wissen
Wir geben einige Empfehlungen, wie wir die Erforschung der konformen Vorhersage mit dem, was wir über die Entscheidungsfindung menschlicher Entscheidungen unter Unsicherheit wissen, besser ausrichten können. Dies beinhaltet die Ratschläge, um empirisch zu untersuchen, wie Entscheidungsträger Vorhersagesätze verwenden, z. Wir müssen nach Möglichkeiten suchen, die Unsicherheitsquantifizierung trotz des potenziellen Missverhältnisses des Informationszugriffs zwischen Experten und Modell zu entwerfen (z. Hier). Es gibt auch eine Menge, die wir immer noch nicht wissen, wenn es darum geht, wie Menschen auf verschiedene Eigenschaften von Vorhersagesätzen reagieren. Wir können eine bessere Aufgabe machen, Aspekte des Vorhersage -Set -Designs mit den Vorlieben zu informieren, die wir aus fachkundigen Entscheidungen hervorrufen oder lernen, beispielsweise für die Vielfalt der Elemente in einem Satz (dh sollte ein Satz, der jemals den Entscheidungsträger dazu veranlasst, den Entscheidungsträger zu denken, um unterschiedlicher zu denken als sonst?) Oder die Kind der Vorhersagessätze in höheren Dimensionen. Im Allgemeinen ist es möglich, dass die Artwork und Weise, wie menschliche Entscheidungsträger durch Vorhersagesätze informiert werden, weniger empfindlich gegenüber der Abdeckung ist als die konforme Literatur impliziert. In diesem Fall sollten wir in Betracht ziehen, stattdessen die Deckung zu maximieren, die unter anderen Einschränkungen unterliegt. Wenn Sie jemals untersucht haben, wie Menschen Konfidenzintervalle verwenden, wissen Sie, welche Arten von Unempfindlichkeit ich spreche.
Warum es schwierig ist, die konforme Vorhersage zu „preisen“
Wir schließen mit Einige Gedanken darüber, warum es schwierig ist, den Wert verschiedener Ansätze zur Quantifizierung der Unsicherheit zu bewerten, einschließlich der kalibrierenden Methoden der Submit -hoc -Vorhersage wie der konformen Vorhersage. Ein Thema ist, dass die Faktoren, die die Popularität bestimmter Methoden zur Quantifizierung der Unsicherheit vorantreiben, häufig außerhalb der Grenzen der Theorie liegen. Der Customary -Bootstrap ist zum Beispiel häufig verwendet, da es sich um ein einfaches Konzept handelt, das die Quantifizierung der Unsicherheit ohne viel Denken verspricht, nicht unbedingt, weil Theoretiker nachweisen können, wie die Konvergenz mit zunehmender Stichprobengröße verbessert werden kann. Dann besteht die Herausforderung, bestimmten Formen der Unsicherheit einen Wert zuzuweisen, den einige Entscheidungsträger sich wünschen (z. B. Bayesianische Wahrscheinlichkeit), weil sie nicht in den Rahmen passen, in dem wir arbeiten Hier). Es gibt einige Dinge, die die Theorie in den aktuellen Formen schwer zu kommentieren ist, aber das bedeutet nicht, dass wir so tun sollten, als ob sie nicht existieren.