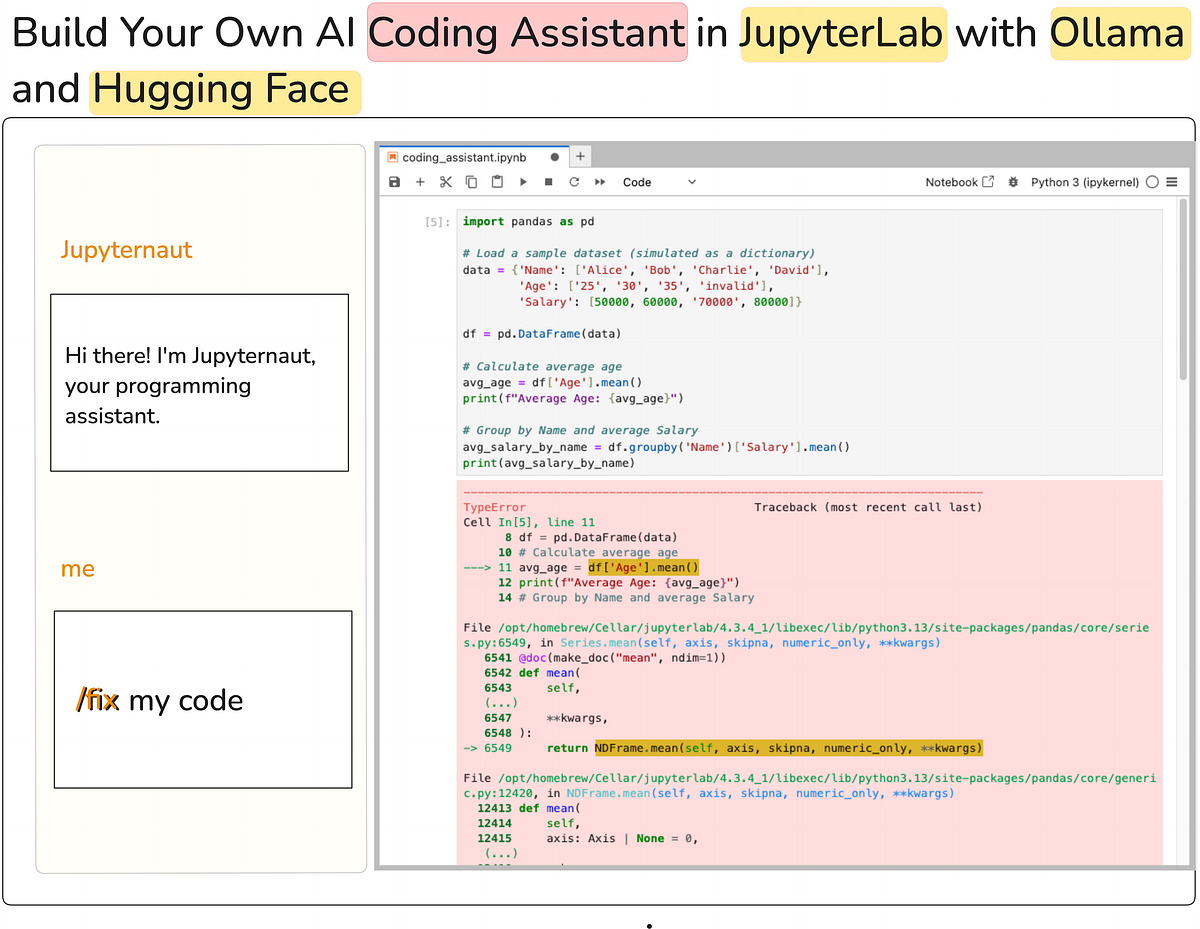
Jupyter ai bringt generativ KI -Fähigkeiten direkt in die Schnittstelle. Ein lokaler KI -Assistent gewährleistet die Privatsphäre, verringert die Latenz und bietet Offline -Funktionen, was es zu einem leistungsstarken Werkzeug für Entwickler macht. In diesem Artikel lernen wir, wie Sie einen lokalen KI -Codierungsassistenten einrichten Jupyterlab Verwendung Jupyter aiAnwesend Ollama Und Umarmtes Gesicht. Am Ende dieses Artikels haben Sie einen voll funktionsfähigen Codierungsassistenten in JupyterLab, der in der Lage ist, Code zu vervollständigen, Fehler zu beheben, neue Notizbücher von Grund auf neu zu erstellen, und vieles mehr, wie im folgenden Screenshot gezeigt.

⚠️ Jupyter AI steht noch in einer starken Entwicklung, sodass einige Merkmale brechen können. Zum Schreiben dieses Artikels habe ich das Setup getestet, um zu bestätigen, dass es funktioniert, aber erwarte mögliche Änderungen Während sich das Projekt entwickelt. Auch die Leistung des Assistenten hängt von dem Modell ab, das Sie auswählen. Stellen Sie daher die für Ihren Anwendungsfall geeignete Auswahl aus.
Das Wichtigste zuerst – Was ist Jupyter AI? Wie der Title schon sagt, ist Jupyter AI eine JupyterLab -Erweiterung für generative KI. Dieses leistungsstarke Instrument verwandelt Ihre Commonplace -Jupyter -Notebooks oder Ihre JupyterLab -Umgebung in einen generativen KI -Spielplatz. Das Beste daran? Es funktioniert auch nahtlos in Umgebungen wie Google Colaboratory Und Visible Studio Code. Diese Erweiterung ermöglicht das gesamte schwere Heben und bietet Zugang zu einer Vielzahl von Modellanbietern (sowohl offen als auch geschlossene Quelle) in Ihrer Jupyter -Umgebung.

Die Einrichtung der Umgebung umfasst drei Hauptkomponenten:
- Jupyterlab
- Die Jupyter AI -Erweiterung
- Ollama (für lokale Modelldienste)
- (Elective) umarmendes Gesicht (für Gguf Modelle)
Ehrlich gesagt ist es der einfache Teil, den Assistenten dazu zu bringen, Codierungsfehler zu beheben. Schwierig ist es, sicherzustellen, dass alle Installationen korrekt durchgeführt wurden. Es ist daher wichtig, dass Sie die Schritte korrekt ausführen.
1. Installieren der Jupyter AI -Erweiterung
Es wird empfohlen, eine zu erstellen Neue Umgebung Insbesondere für Jupyter KI, um Ihre vorhandene Umgebung sauber und organisiert zu halten. Sobald erledigt ist, folgen Sie den nächsten Schritten. Jupyter AI erfordert JupyterLab 4.x oder Jupyter Pocket book 7+Stellen Sie additionally sicher, dass Sie die neueste Model von Jupyter Lab installiert haben. Sie können JupyterLab mit PIP oder Conda installieren/aktualisieren:
# Set up JupyterLab 4 utilizing pip
pip set up jupyterlab~=4.0Installieren Sie die Jupyter AI -Erweiterung wie folgt wie folgt.
pip set up "jupyter-ai(all)"Dies ist die einfachste Methode für die Set up, da sie alle Anbieterabhängigkeiten enthält (so dass es umarmt, Gesicht, Ollama usw., außerhalb der Schachtel). Bis heute unterstützt Jupyter AI die folgenden Modellanbieter :

Wenn Sie während der Jupyter -AI -Set up auf Fehler stoßen, installieren Sie die Jupyter AI manuell mithilfe pip ohne die (alle) optionale Abhängigkeitsgruppe. Auf diese Weise können Sie steuern, welche Modelle in Ihrer Jupyter AI -Umgebung verfügbar sind. Verwenden Sie beispielsweise Jupyter AI mit nur zusätzlichen Unterstützung für Ollama -Modelle, um Folgendes zu verwenden:
pip set up jupyter-ai langchain-ollamaDie Abhängigkeiten hängen von den Modellanbietern ab (siehe Tabelle oben). Starten Sie als nächstes Ihre JupyterLab -Instanz neu. Wenn Sie ein Chat -Image in der linken Seitenleiste sehen, bedeutet dies, dass alles perfekt installiert wurde. Mit Jupyter AI können Sie mit Modellen chatten oder Inline Magic -Befehle direkt in Ihren Notebooks verwenden.

2. Einrichten von Ollama für lokale Modelle
Jetzt, da Jupyter AI installiert ist, müssen wir es mit einem Modell konfigurieren. Während sich Jupyter AI direkt in die Umarmung von Gesichtsmodellen integriert, einige Modelle kann nicht richtig funktionieren. Stattdessen bietet Ollama eine zuverlässigere Möglichkeit, Modelle lokal zu laden.
Ollama ist ein praktisches Werkzeug zum Laufen Großsprachige Modelle lokal. Sie können vorkonfigurierte KI-Modelle von seinen herunterladen Bibliothek. Ollama unterstützt alle wichtigen Plattformen (MacOS, Home windows, Linux). Wählen Sie additionally die Methode für Ihr Betriebssystem und laden Sie sie herunter und installieren Sie sie vom Beamten Webseite. Stellen Sie nach der Set up sicher, dass es durch Ausführen korrekt eingerichtet ist:
Ollama --version
------------------------------
ollama model is 0.6.2Stellen Sie außerdem sicher, dass Ihr Ollama -Server muss Laufen Sie, was Sie überprüfen können, indem Sie anrufen ollama serve am Terminal:
$ ollama serve
Error: hear tcp 127.0.0.1:11434: bind: deal with already in useWenn der Server bereits aktiv ist, sehen Sie einen Fehler, der wie oben bestätigt, dass Ollama ausgeführt und verwendet wird.
Choice 1: Verwenden vorbereiteter Modelle
Ollama bietet a Bibliothek von vorgebildeten Modellen, die Sie können Laden Sie lokal herunter und laufen Sie lokal aus. Laden Sie es mit dem herunter, um die Verwendung eines Modells zu verwenden ziehen Befehl. Zum Beispiel zu verwenden qwen2.5-coder:1.5blaufen:
ollama pull qwen2.5-coder:1.5bDadurch wird das Modell in Ihrer lokalen Umgebung heruntergeladen. Um zu bestätigen, ob das Modell heruntergeladen wurde, rennen Sie:
ollama recordDadurch werden alle Modelle aufgeführt, die Sie mit Ollama heruntergeladen und lokal in Ihrem System gespeichert haben.
Choice 2: Laden eines benutzerdefinierten Modells
Wenn das von Ihnen benötigte Modell in Ollamas Bibliothek nicht verfügbar ist, können Sie ein benutzerdefiniertes Modell laden, indem Sie a erstellen Modelldatei Dies gibt die Quelle des Modells an. Für detaillierte Anweisungen zu diesem Prozess finden Sie die Ollama Importdokumentation.
Choice 3: GGUF -Modelle direkt aus dem Umarmungsgesicht ausführen
Ollama unterstützt jetzt GGUF -Modelle direkt aus dem umarmenden Gesichtszentrumeinschließlich sowohl öffentlicher als auch privater Modelle. Wenn Sie das GGUF -Modell direkt vom Umarmungs -Face -Hub verwenden möchten, können Sie dies tun, ohne eine benutzerdefinierte Modelldatei zu benötigen, wie in Choice 2 oben erwähnt.
Zum Beispiel a laden a 4-bit quantized Qwen2.5-Coder-1.5B-Instruct mannequin vom umarmen Gesicht:
1. Aktivieren Sie zuerst Ollama unter Ihrem Lokale Apps Einstellungen.

2. Wählen Sie auf der Modellseite Ollama aus der Dropdown -Verwendung dieses Modells, wie unten gezeigt.

Wir sind quick da. Öffnen Sie in Jupyterlab die Jupyter AI Chat -Schnittstelle in der Seitenleiste. Oben im Chat -Bereich oder in den Einstellungen (Ausrüstungssymbol) befindet sich ein Dropdown oder ein Feld, um die auszuwählen Modellanbieter und Modell -ID. Wählen Ollama als Anbieter und geben Sie den Modellnamen genau wie die Liste der Ollama -Liste im Terminal (z. qwen2.5-coder:1.5b). Jupyter AI stellt eine Verbindung zum lokalen Ollama -Server her und lädt dieses Modell für Abfragen. Es werden keine API -Schlüssel benötigt, da dies lokal ist.
- Legen Sie die Modelle für Sprachmodell, Einbettungsmodell und Inline -Vervollständigungen an, basierend auf den Modellen Ihrer Wahl.
- Speichern Sie die Einstellungen und kehren Sie zur Chat -Oberfläche zurück.

Diese Konfiguration verbindet Jupyter AI über Ollama mit dem lokal ausgeführten Modell. Während Inline -Abschlüsse durch diesen Vorgang aktiviert werden sollten, können Sie dies manuell tun, indem Sie auf die Klicken auf die Jupyernaut Ikone, das sich in der unteren Balken der JupyterLab -Schnittstelle hyperlinks von der befindet Modusanzeige (zB Modus: Befehl). Dadurch wird ein Dropdown -Menü geöffnet, in dem Sie auswählen können Allow completions by Jupyternaut Um die Funktion zu aktivieren.

Nach der Einrichtung können Sie den AI -Codierungsassistenten für verschiedene Aufgaben wie Code Autocompletion, Debugging -Hilfe und das Generieren neuer Code von Grund auf verwenden. Es ist wichtig zu beachten, dass Sie entweder über die mit dem Assistenten interagieren können Chat -Seitenleiste oder direkt in Pocket book -Zellen verwendet %%ai magic instructions. Schauen wir uns beide Wege an.
Codierungsassistent über Chat -Schnittstelle
Das ist ziemlich einfach. Sie können einfach mit dem Modell chatten, um eine Aktion auszuführen. Hier finden Sie hier, wie wir das Modell bitten können, den Fehler im Code zu erklären und den Fehler anschließend durch Auswahl des Codes im Pocket book zu beheben.

Sie können die KI auch bitten, Code für eine Aufgabe von Grund auf neu zu generieren, indem Sie nur beschreiben, was Sie in der natürlichen Sprache benötigen. Hier ist eine Python -Funktion, die alle Primzahlen bis zu einer gegebenen positiven Ganzzahl N zurückgibt, die von Jupyternautht erzeugt wird.

Codierungsassistent über Pocket book -Zellen oder Ipython -Shell:
Sie können auch mit Modellen direkt innerhalb eines Jupyter -Notizbuchs interagieren. Laden Sie zunächst die Ipython -Erweiterung:
%load_ext jupyter_ai_magicsJetzt können Sie die verwenden %%ai Zellmagie zur Interaktion mit dem ausgewählten Sprachmodell mit einer bestimmten Eingabeaufforderung. Lassen Sie uns das obige Beispiel replizieren, diesmal jedoch innerhalb der Pocket book -Zellen.

Für weitere Particulars und Optionen können Sie sich auf den Beamten beziehen Dokumentation.
Wie Sie aus diesem Artikel messen können, erleichtert Jupyter AI die Einrichtung eines Codierungsassistenten, vorausgesetzt, Sie haben die richtigen Installationen und Einrichtungen. Ich habe ein relativ kleines Modell verwendet, aber Sie können aus einer Vielzahl von Modellen auswählen, die von Ollama oder umarmendem Gesicht unterstützt werden. Der Hauptvorteil hierbei besteht darin, dass die Verwendung eines lokalen Modells erhebliche Vorteile bietet: Es verbessert die Privatsphäre, verringert die Latenz und verringert die Abhängigkeit von proprietären Modellanbietern. Allerdings laufen lArge-Modelle lokal mit Ollama können ressourcenintensiv sein. Stellen Sie additionally sicher, dass Sie über ausreichende RAM verfügen. Mit dem schnellen Tempo, in dem sich Open-Supply-Modelle verbessern, können Sie auch mit diesen Alternativen eine vergleichbare Leistung erzielen.