Zeitfolgen Prognosen sind in verschiedenen Bereichen allgegenwärtig, beispielsweise im Einzelhandel, im Finanzwesen, in der Fertigung, im Gesundheitswesen und in den Naturwissenschaften. Im Einzelhandel wurde beispielsweise beobachtet, dass Verbesserung der Genauigkeit der Nachfrageprognose kann die Lagerkosten deutlich senken und den Umsatz steigern. Deep-Studying-Modelle (DL) haben sich zu einem beliebten Ansatz für die Vorhersage umfangreicher, multivariater Zeitreihendaten entwickelt, da sie sich in einer Vielzahl von Umgebungen als intestine erwiesen haben (z. B. haben DL-Modelle in den USA gute Ergebnisse erzielt). M5-Wettbewerb).
Gleichzeitig gab es schnelle Fortschritte bei großen Basissprachenmodellen, die für Aufgaben der Verarbeitung natürlicher Sprache (NLP) verwendet werden, wie z Übersetzung, durch Abruf erweiterte GenerierungUnd Code-Vervollständigung. Diese Modelle werden auf große Mengen trainiert textuell Daten aus verschiedenen Quellen wie z gemeinsames Kriechen und Open-Supply-Code, der es ihnen ermöglicht, Muster in Sprachen zu identifizieren. Das macht sie sehr mächtig Nullschuss Werkzeuge; zum Beispiel, wenn es mit dem Abrufen gepaart istSie können Fragen zu aktuellen Ereignissen beantworten und diese zusammenfassen.
Obwohl DL-basierte Prognostiker weitgehend übertreffend traditionelle Methoden und Fortschritte Reduzierung der Schulungs- und InferenzkostenSie stehen vor Herausforderungen: Die meisten DL-Architekturen erfordern lange und aufwändige Schulungs- und Validierungszyklen bevor ein Kunde das Modell anhand einer neuen Zeitreihe testen kann. Im Gegensatz dazu kann ein Basismodell für Zeitreihenprognosen ohne zusätzliche Schulung gute, sofort einsatzbereite Prognosen für noch nicht sichtbare Zeitreihendaten liefern, sodass sich Benutzer auf die Verfeinerung von Prognosen für die eigentliche nachgelagerte Aufgabe konzentrieren können Einzelhandelsnachfrageplanung.
Zu diesem Zweck in „Ein reines Decoder-Grundmodell für die Zeitreihenvorhersage”, akzeptiert bei ICML 2024, Wir stellen TimesFM vor, ein einzelnes Prognosemodell, das auf einem großen Zeitreihenkorpus von 100 Milliarden realen Zeitpunkten vorab trainiert wurde. Im Vergleich zu den neuesten großen Sprachmodellen (LLMs) ist TimesFM viel kleiner (200 Mio. Parameter), dennoch zeigen wir, dass seine Zero-Shot-Leistung selbst in solchen Maßstäben bei einer Vielzahl unbekannter Datensätze verschiedener Domänen und zeitlicher Granularitäten nahe an der liegt hochmoderne überwachte Ansätze, die explizit auf diesen Datensätzen trainiert werden. Um auf das Modell zuzugreifen, besuchen Sie bitte unsere Umarmendes Gesicht Und GitHub Repos.
Ein reines Decoder-Grundmodell für die Zeitreihenvorhersage
LLMs werden in der Regel in a ausgebildet Nur Decoder Mode, die drei Schritte umfasst. Zunächst wird der Textual content in Teilwörter, sogenannte Token, zerlegt. Anschließend werden die Token in den Stacked Causal eingespeist Transformator Schichten, die eine Ausgabe entsprechend jedem Eingabe-Token erzeugen (sie können sich nicht um zukünftige Token kümmern). Schließlich entspricht die Ausgabe dem ichDer -te Token fasst alle Informationen der vorherigen Token zusammen und sagt die (ich+1)-tes Token. Während der Inferenz generiert das LLM die Ausgabe Token für Token. Wenn beispielsweise die Frage „Was ist die Hauptstadt von Frankreich?“ gestellt wird, generiert es möglicherweise das Token „Die“, dann die Bedingung „Was ist die Hauptstadt von Frankreich? Die“, um das nächste Token „Hauptstadt“ zu generieren, und so weiter, bis die vollständige Antwort generiert wird: „Die Hauptstadt von Frankreich ist Paris“.
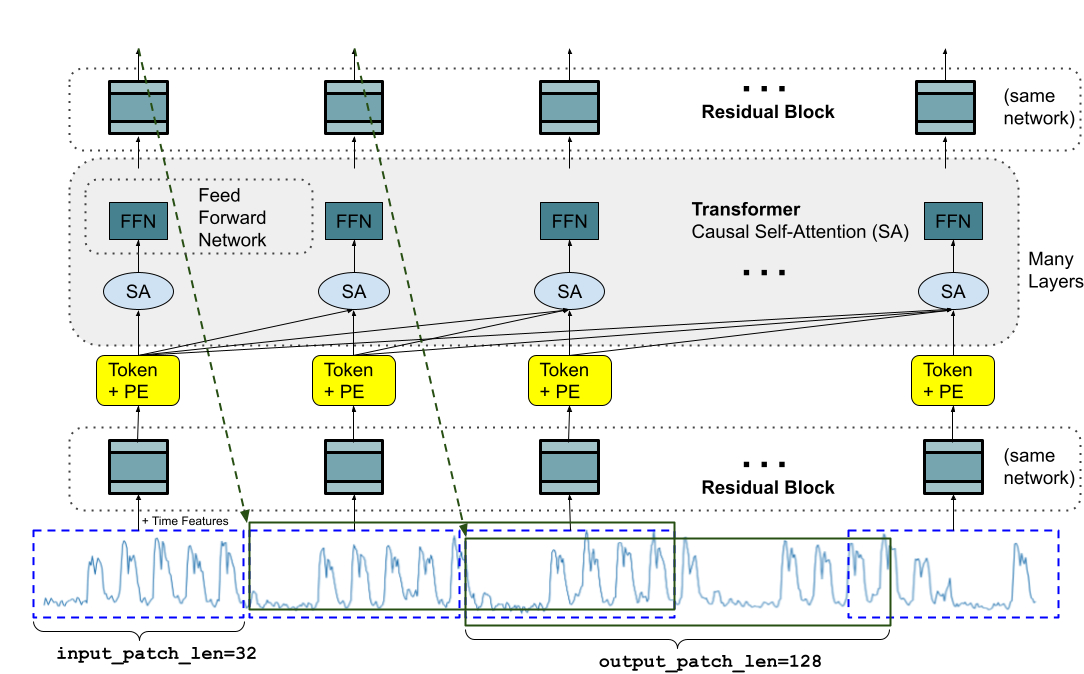
Ein Basismodell für die Zeitreihenvorhersage sollte sich an variable Kontextlängen (was wir beobachten) und Horizontlängen (was wir das Modell abfragen, um es vorherzusagen) anpassen und gleichzeitig über genügend Kapazität verfügen, um alle Muster aus einem großen Datensatz vor dem Coaching zu kodieren. Ähnlich wie bei LLMs verwenden wir gestapelte Transformatorschichten (Selbstaufmerksamkeit und Feedforward Schichten) als Hauptbausteine für das TimesFM-Modell. Im Kontext der Zeitreihenvorhersage behandeln wir einen Patch (eine Gruppe aneinandergrenzender Zeitpunkte) als ein Token, das durch eine aktuelle Zeit populär gemacht wurde Langfristige PrognosearbeitDie Aufgabe besteht dann darin, die (ich+1)-ter Patch der gegebenen Zeitpunkte ich-ter Ausgang am Ende der gestapelten Transformatorschichten.
Es gibt jedoch einige wesentliche Unterschiede zu Sprachmodellen. Erstens brauchen wir eine mehrschichtiges Perzeptron Block mit Restverbindungen, um einen Patch von Zeitreihen in ein Token umzuwandeln, das zusammen mit in die Transformatorschichten eingegeben werden kann Positionskodierungen (SPORT). Dazu verwenden wir einen Restblock ähnlich unserer vorherigen Arbeit in Langfristige Prognosen. Zweitens kann am anderen Ende ein Ausgabetoken des gestapelten Transformators verwendet werden, um eine längere Länge aufeinanderfolgender Zeitpunkte als die Eingabe-Patch-Länge vorherzusagen, dh die Ausgabe-Patch-Länge kann größer als die Eingabe-Patch-Länge sein.
Stellen Sie sich eine Zeitreihe mit einer Länge von 512 Zeitpunkten vor, die zum Trainieren eines TimesFM-Modells mit einer Eingabe-Patch-Länge von 32 und einer Ausgabe-Patch-Länge von 128 verwendet wird. Während des Trainings wird das Modell gleichzeitig darauf trainiert, die ersten 32 Zeitpunkte zur Vorhersage der nächsten 128 zu verwenden Zeitpunkte, die ersten 64 Zeitpunkte zur Vorhersage der Zeitpunkte 65 bis 192, die ersten 96 Zeitpunkte zur Vorhersage der Zeitpunkte 97 bis 224 und so weiter. Angenommen, das Modell erhält während der Inferenz eine neue Zeitreihe der Länge 256 und wird damit beauftragt, die nächsten 256 Zeitpunkte in der Zukunft vorherzusagen. Das Modell generiert zunächst die zukünftigen Vorhersagen für die Zeitpunkte 257 bis 384 und bedingt dann die anfängliche Eingabe der Länge von 256 plus die generierte Ausgabe, um die Zeitpunkte 385 bis 512 zu generieren. Andererseits, wenn in unserem Modell die Länge des Ausgabe-Patches entsprach der Eingabe-Patch-Länge von 32, dann müssten wir für die gleiche Aufgabe acht Generierungsschritte statt nur der beiden oben genannten durchlaufen. Dies erhöht die Wahrscheinlichkeit, dass sich mehr Fehler ansammeln, und daher sehen wir in der Praxis, dass eine längere Ausgabe-Patch-Länge zu einer besseren Leistung für Prognosen über einen längeren Zeitraum führt
 |
| TimesFM-Architektur. |
Daten vor dem Coaching
So wie LLMs mit mehr Token besser werden, benötigt TimesFM eine große Menge legitimer Zeitreihendaten, um zu lernen und sich zu verbessern. Wir haben viel Zeit damit verbracht, unsere Trainingsdatensätze zu erstellen und zu bewerten, und Folgendes hat unserer Meinung nach am besten funktioniert:
Synthetische Daten helfen bei den Grundlagen. Mithilfe statistischer Modelle oder physikalischer Simulationen können aussagekräftige synthetische Zeitreihendaten generiert werden. Diese grundlegenden zeitlichen Muster können dem Modell die Grammatik der Zeitreihenvorhersage beibringen.
Daten aus der realen Welt verleihen dem Ganzen eine Atmosphäre der realen Welt. Wir durchforsten verfügbare öffentliche Zeitreihendatensätze und stellen selektiv einen großen Korpus von 100 Milliarden Zeitpunkten zusammen. Unter diesen Datensätzen befinden sich Google Developments Und Wikipedia-Seitenaufrufe, die verfolgen, woran die Leute interessiert sind, und die Developments und Muster in vielen anderen realen Zeitreihen intestine widerspiegeln. Dies hilft TimesFM, das Gesamtbild zu verstehen und besser zu verallgemeinern, wenn domänenspezifische Kontexte bereitgestellt werden, die während des Trainings nicht sichtbar sind.
Ergebnisse der Zero-Shot-Bewertung
Wir evaluieren TimesFM Zero-Shot anhand von Daten, die während des Trainings nicht gesehen wurden, unter Verwendung beliebter Zeitreihen-Benchmarks. Wir beobachten, dass TimesFM besser abschneidet als die meisten statistischen Methoden wie ARIMA, ETS und kann mit leistungsstarken DL-Modellen wie vergleichbar sein oder diese sogar übertreffen DeepAR, PatchTST das battle explizit ausgebildet auf der Zielzeitreihe.
Wir haben das genutzt Monash-Prognosearchiv um die Out-of-the-Field-Leistung von TimesFM zu bewerten. Dieses Archiv enthält Zehntausende Zeitreihen aus verschiedenen Bereichen wie Verkehr, Wetter und Nachfrageprognosen, die Frequenzen von wenigen Minuten bis hin zu jährlichen Daten abdecken. In Anlehnung an die vorhandene Literatur untersuchen wir die mittlerer absoluter Fehler (MAE) entsprechend skaliert damit es über die Datensätze gemittelt werden kann. Wir sehen, dass Zero-Shot (ZS) TimesFM besser ist als die meisten überwachten Ansätze, einschließlich neuerer Deep-Studying-Modelle. Wir vergleichen auch TimesFM mit GPT-3.5 für die Prognose mithilfe einer speziellen Eingabetechnik, die von lmtime(ZS). Wir zeigen, dass TimesFM eine bessere Leistung als llmtime(ZS) erbringt, obwohl es um Größenordnungen kleiner ist.
 |
| Geometrisches Mittel (GM, und Warum wir das tun) der skalierten MAE (je niedriger, desto besser) von TimesFM(ZS) im Vergleich zu anderen überwachten und Zero-Shot-Ansätzen für Monash-Datensätze. |
Die meisten Monash-Datensätze haben einen kurzen oder mittleren Horizont, d. h. die Vorhersagedauer ist nicht zu lang. Wir testen TimesFM auch anhand beliebter Benchmarks für langfristige Prognosen im Vergleich zu einer aktuellen, hochmodernen Basislinie. PatchTST (und andere Basislinien für langfristige Prognosen). In der nächsten Abbildung zeichnen wir die MAE auf ETT Datensätze für die Aufgabe, 96 und 192 Zeitpunkte in der Zukunft vorherzusagen. Die Metrik wurde im letzten Testfenster jedes Datensatzes berechnet (wie von der Noch Zeit Papier). Wir sehen, dass TimesFM nicht nur die Leistung von llmtime(ZS) übertrifft, sondern auch mit der des überwachten PatchTST-Modells übereinstimmt, das explizit auf die jeweiligen Datensätze trainiert wurde.
 |
| Letztes Fenster MAE (je niedriger, desto besser) von TimesFM(ZS) im Vergleich zu lmtime(ZS) und Langhorizont-Prognosebasislinien auf ETT-Datensätzen. |
Abschluss
Wir trainieren ein Decoder-only-Basismodell für die Zeitreihenprognose mithilfe eines großen Vortrainingskorpus von 100 Milliarden realen Zeitpunkten, von denen der Großteil aus Suchinteresse-Zeitreihendaten aus Google Developments und Seitenaufrufen von Wikipedia besteht. Wir zeigen, dass selbst ein relativ kleines vortrainiertes Modell mit 200 Millionen Parametern, das unsere TimesFM-Architektur verwendet, bei einer Vielzahl öffentlicher Benchmarks aus verschiedenen Bereichen und mit unterschiedlicher Granularität eine beeindruckende Zero-Shot-Leistung zeigt.
Danksagung
Diese Arbeit ist das Ergebnis einer Zusammenarbeit mehrerer Personen aus Google Analysis und Google Cloud, darunter (in alphabetischer Reihenfolge): Abhimanyu Das, Weihao Kong, Andrew Leach, Mike Lawrence, Alex Martin, Rajat Sen, Yang Yang, Skander Hannachi, Ivan Kusnezow und Yichen Zhou.