
Die Einführung von GPT-3, insbesondere seiner Chatbot-Kind, additionally ChatGPT, hat sich als monumentaler Second in der KI-Landschaft erwiesen und den Beginn der Revolution der generativen KI (GenAI) markiert. Obwohl es im Bereich der Bilderzeugung bereits frühere Modelle gab, battle es die GenAI-Welle, die die Aufmerksamkeit aller auf sich zog.
Secure Diffusion ist ein Mitglied der GenAI-Familie zur Bilderzeugung. Es ist bekannt für seine Anpassungsmöglichkeiten, die freie Ausführung auf der eigenen {Hardware} und die aktive Weiterentwicklung. Es ist nicht das einzige. OpenAI hat beispielsweise DALLE-3 als Teil seines ChatGPTPlus-Abonnements veröffentlicht, um die Bildgenerierung zu ermöglichen. Secure Diffusion zeigte jedoch bemerkenswerte Erfolge bei der Generierung von Bildern sowohl aus Textual content als auch aus anderen vorhandenen Bildern. Die jüngste Integration von Videogenerierungsfunktionen in Diffusionsmodelle liefert ein überzeugendes Argument für die Untersuchung dieser Spitzentechnologie.
In diesem Beitrag erfahren Sie einige technische Particulars zu Secure Diffusion und wie Sie es auf Ihrer eigenen {Hardware} einrichten.
Lass uns anfangen.

Eine technische Einführung in die stabile Diffusion
Foto von Denis Oliveira. Einige Rechte vorbehalten.
Überblick
Dieser Beitrag besteht aus vier Teilen; sie sind:
- Wie funktionieren Diffusionsmodelle?
- Mathematik von Diffusionsmodellen
- Warum ist stabile Diffusion etwas Besonderes?
- So installieren Sie die Secure Diffusion WebUI
Wie funktionieren Diffusionsmodelle?
Um Diffusionsmodelle zu verstehen, betrachten wir zunächst noch einmal, wie die Bilderzeugung mithilfe von Maschinen vor der Einführung von Secure Diffusion oder ihren heutigen Gegenstücken durchgeführt wurde. Angefangen hat alles mit GANs (Generative Adversarial Networks), bei denen zwei neuronale Netze an einem kompetitiven und kooperativen Lernprozess teilnehmen.
Das erste ist das Generatornetzwerk, das synthetische Daten, in diesem Fall Bilder, erzeugt, die nicht von echten zu unterscheiden sind. Es erzeugt zufälliges Rauschen und verfeinert es schrittweise über mehrere Ebenen, um immer realistischere Bilder zu erzeugen.
Das zweite Netzwerk, additionally das Diskriminatornetzwerk, fungiert als Gegner und untersucht die erzeugten Bilder, um zwischen echten und synthetischen Bildern zu unterscheiden. Ziel ist es, Bilder genau als echt oder gefälscht zu klassifizieren.
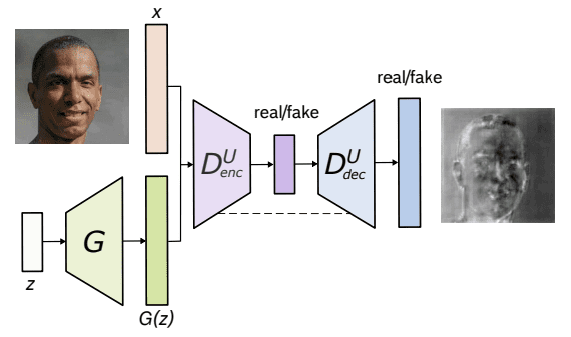
Architektur von U-Web GAN. Von Schönfeld et al. (2020)
Die Diffusionsmodelle gehen davon aus, dass ein verrauschtes Bild oder reines Rauschen das Ergebnis einer wiederholten Überlagerung des Originalbilds mit Rauschen (oder Gaußschem Rauschen) ist. Dieser Prozess der Rauschüberlagerung wird Vorwärtsdiffusion genannt. Genau das Gegenteil davon ist die umgekehrte Diffusion, bei der Schritt für Schritt von einem verrauschten Bild zu einem weniger verrauschten Bild übergegangen wird.
Unten sehen Sie eine Darstellung des Vorwärtsdiffusionsprozesses von rechts nach hyperlinks, dh vom klaren zum verrauschten Bild.

Diffusionsprozess. Bild von Ho et al. (2020)
Mathematik von Diffusionsmodellen
Sowohl der Vorwärts- als auch der Rückwärtsdiffusionsprozess folgen einer Markov-Kette, was bedeutet, dass zu jedem Zeitpunkt Schritt t der Pixelwert oder das Rauschen in einem Bild nur vom vorherigen Bild abhängt.
Vorwärtsdiffusion
Mathematisch kann jeder Schritt im Vorwärtsdiffusionsprozess mithilfe der folgenden Gleichung dargestellt werden:
$$q(mathbf{x}_tmid mathbf{x}_{t-1}) = mathcal{N}(mathbf{x}_t;mu_t = sqrt{1-beta_t} mathbf{x}_{t-1}, Sigma_t = beta_t mathbb{I})$$
wobei $q(x_tmid x_{t-1})$ eine Normalverteilung mit Mittelwert $mu_t = sqrt{1-beta_t}x_{t-1}$ und Varianz $Sigma_t = beta_t mathbb ist {I}$ und $mathbf{I}$ ist die Identitätsmatrix, Bilder (als latente Variable) in jedem Schritt $mathbf{x}_t$ ist ein Vektor und der Mittelwert und die Varianz werden durch den Skalar parametrisiert Wert $beta_t$.
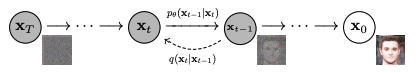
Vorwärtsdiffusion $q(mathbf{x}_tmidmathbf{x}_{t-1})$ und Rückwärtsdiffusion $p_theta(mathbf{x}_{t-1}midmathbf{ x}_t)$. Abbildung von Ho et al. (2020)
Die A-Posteriori-Wahrscheinlichkeit aller Schritte im Vorwärtsdiffusionsprozess ist somit wie folgt definiert:
$$q(mathbf{x}_{1:T}mid mathbf{x}_0) = prod_{t=1}^T q(mathbf{x}_tmidmathbf{x}_ {t-1})$$
Hier wenden wir vom Zeitschritt 1 bis $T$ an.
Umgekehrte Diffusion
Ähnlich funktioniert die umgekehrte Diffusion, die das Gegenteil der Vorwärtsdiffusion darstellt. Während der Vorwärtsprozess die A-Posteriori-Wahrscheinlichkeit anhand der A-Posteriori-Wahrscheinlichkeit abbildet, macht der Umkehrprozess das Gegenteil, dh er bildet die A-Posteriori-Wahrscheinlichkeit bei gegebener A-Posteriori-Wahrscheinlichkeit ab.
$$p_theta(mathbf{x}_{t-1}midmathbf{x}_t) = mathcal{N}(mathbf{x}_{t-1};mu_theta( mathbf{x}_t,t),Sigma_theta(mathbf{x}_t,t))$$
wobei $p_theta$ eine umgekehrte Diffusion anwendet, auch Trajektorie genannt.
Wenn sich der Zeitschritt $t$ der Unendlichkeit nähert, tendiert die latente Variable $mathbf{x}_T$ zu einer nahezu isotropen Gaußschen Verteilung (d. h. reines Rauschen ohne Bildinhalt). Ziel ist es, $q(mathbf{x}_{t-1}mid mathbf{x}_t)$ zu lernen, wobei der Prozess bei der Stichprobe von $mathcal{N}(0,mathbf{ I})$ heißt $mathbf{x}_T$. Wir führen Schritt für Schritt den komplett umgekehrten Prozess durch, um eine Stichprobe aus $q(mathbf{x}_0)$ zu erhalten, additionally den generierten Daten aus der tatsächlichen Datenverteilung. Laienhaft ausgedrückt besteht die umgekehrte Diffusion darin, in vielen kleinen Schritten ein Bild aus zufälligem Rauschen zu erzeugen.
Warum ist stabile Diffusion etwas Besonderes?
Anstatt den Diffusionsprozess direkt auf eine hochdimensionale Eingabe anzuwenden, projiziert die stabile Diffusion die Eingabe mithilfe eines Encodernetzwerks in einen reduzierten latenten Raum (dort findet der Diffusionsprozess statt). Der Grundgedanke dieses Ansatzes besteht darin, den Rechenaufwand beim Coaching von Diffusionsmodellen zu reduzieren, indem die Eingabe in einem niedrigerdimensionalen Raum verarbeitet wird. Anschließend wird ein herkömmliches Diffusionsmodell (z. B. ein U-Web) verwendet, um neue Daten zu generieren, die dann mithilfe eines Decodernetzwerks hochgetastet werden.
Wie installiere ich Secure Diffusion WebUI?
Sie können Secure Diffusion als Dienst im Abonnement nutzen oder herunterladen und auf Ihrem Laptop ausführen. Es gibt zwei Hauptmöglichkeiten, es auf Ihrem Laptop zu verwenden: die WebUI und die CompfyUI. Hier wird Ihnen die Set up von WebUI angezeigt.
Notiz: Stabile Diffusion ist rechenintensiv. Möglicherweise benötigen Sie eine anständige {Hardware} mit unterstützter GPU, um eine angemessene Leistung zu erzielen.
Das Secure Diffusion WebUI-Paket für die Programmiersprache Python kann kostenlos von GitHub heruntergeladen und verwendet werden Seite. Im Folgenden finden Sie die Schritte zum Installieren der Bibliothek auf einem Apple Silicon-Chip, wobei auch andere Plattformen größtenteils gleich sind:
-
- Voraussetzungen. Eine der Voraussetzungen für den Prozess ist die Einrichtung zur Ausführung der WebUI. Es handelt sich um einen Python-basierten Webserver, dessen Benutzeroberfläche mit Gradio erstellt wurde. Die Einrichtung erfolgt größtenteils automatisch, Sie sollten jedoch sicherstellen, dass einige grundlegende Komponenten verfügbar sind, wie z
gitUndwget. Wenn Sie die WebUI ausführen, wird eine virtuelle Python-Umgebung erstellt.
Unter macOS möchten Sie möglicherweise ein Python-System mit Homebrew installieren, da einige Abhängigkeiten möglicherweise eine neuere Model von Python benötigen als die, die macOS standardmäßig ausliefert. Siehe die Homebrews Setup-Anleitung. Dann können Sie Python mit Homebrew installieren, indem Sie Folgendes verwenden:brew set up cmake protobuf rust python@3.10 git wget
- Herunterladen. Die WebUI ist ein Repository auf GitHub. Um eine Kopie der WebUI auf Ihren Laptop zu laden, können Sie den folgenden Befehl ausführen:
Git-Klon https://github.com/AUTOMATIC1111/stable-diffusion-webui
Dadurch wird ein Ordner mit dem Namen erstellt
stable-diffusion-webuiund Sie sollten für die folgenden Schritte in diesem Ordner arbeiten. - Kontrollpunkte. Die WebUI soll die Pipeline ausführen, das Secure Diffusion-Modell ist jedoch nicht enthalten. Sie müssen das Modell (auch Checkpoints genannt) herunterladen. Es stehen mehrere Versionen zur Auswahl. Diese können von verschiedenen Quellen heruntergeladen werden, am häufigsten von Umarmendes Gesicht. Im folgenden Abschnitt wird dieser Schritt ausführlicher behandelt. Alle stabilen Diffusionsmodelle/Kontrollpunkte sollten im Verzeichnis abgelegt werden
stable-diffusion-webui/fashions/Secure-diffusion. - Erster Lauf. Navigieren Sie in die
stable-diffusion-webuiVerzeichnis über die Befehlszeile öffnen und ausführen./webui.shum die Internet-Benutzeroberfläche zu starten. Mit dieser Aktion wird eine virtuelle Python-Umgebung erstellt und aktiviertvenvwobei alle verbleibenden erforderlichen Abhängigkeiten automatisch abgerufen und installiert werden.
Python-Module, die während der ersten Ausführung von WebUI installiert wurden
- Anschließender Lauf. Führen Sie den Vorgang erneut aus, um in Zukunft auf die Internet-Benutzeroberfläche zugreifen zu können
./webui.shim WebUI-Verzeichnis. Beachten Sie, dass sich die WebUI nicht automatisch aktualisiert. Um es zu aktualisieren, müssen Sie es ausführengit pullBevor Sie den Befehl ausführen, stellen Sie sicher, dass Sie die neueste Model verwenden. Was ist daswebui.shDas Skript startet einen Webserver, den Sie in Ihrem Browser öffnen können, um auf die Secure Diffusion zuzugreifen. Die gesamte Interaktion sollte über den Browser erfolgen, und Sie können die WebUI herunterfahren, indem Sie den Webserver herunterfahren (z. B. durch Drücken von Strg-C auf dem laufenden Terminal).webui.sh).
- Voraussetzungen. Eine der Voraussetzungen für den Prozess ist die Einrichtung zur Ausführung der WebUI. Es handelt sich um einen Python-basierten Webserver, dessen Benutzeroberfläche mit Gradio erstellt wurde. Die Einrichtung erfolgt größtenteils automatisch, Sie sollten jedoch sicherstellen, dass einige grundlegende Komponenten verfügbar sind, wie z
Für andere Betriebssysteme ist die offizielle Readme-Datei bietet die beste Beratung.
Wie lade ich die Modelle herunter?
Sie können Secure Diffusion-Modelle über herunterladen Umarmendes Gesicht indem Sie ein Modell auswählen, das Sie interessiert, und mit dem Abschnitt „Dateien und Versionen“ fortfahren. Suchen Sie nach Dateien mit der Bezeichnung „.ckpt“ oder „.safetensors”-Erweiterungen und klicken Sie auf den nach rechts zeigenden Pfeil neben der Dateigröße, um den Obtain zu starten. SafeTensor ist ein alternate options Format zur Pickle-Serialisierungsbibliothek von Python. Ihre Unterschiede werden von der WebUI automatisch verarbeitet, sodass Sie sie als gleichwertig betrachten können.
Es gibt mehrere Modelle von Hugging Face, wenn Sie nach dem Modellnamen „stable-diffusion“ suchen.
Zu den offiziellen Secure-Diffusion-Modellen, die wir in den kommenden Kapiteln verwenden werden, gehören:
- Stabile Diffusion 1,4 (
sd-v1-4.ckpt) - Stabile Diffusion 1,5 (
v1-5-pruned-emaonly.ckpt) - Stabile Diffusion 1,5 Inpainting (
sd-v1-5-inpainting.ckpt)
Für die Secure Diffusion-Versionen 2.0 und 2.1 sind eine Modell- und Konfigurationsdatei unerlässlich. Stellen Sie außerdem beim Generieren von Bildern sicher, dass die Bildbreite und -höhe auf 768 oder höher eingestellt sind:
- Stabile Diffusion 2.0 (
768-v-ema.ckpt) - Stabile Diffusion 2,1 (
v2-1_768-ema-pruned.ckpt)
Die Konfigurationsdatei finden Sie auf GitHub an folgendem Speicherort:
Nachdem Sie heruntergeladen haben v2-inference-v.yaml Von oben sollten Sie es im selben Ordner ablegen wie das Modell, das mit dem Dateinamen des Modells übereinstimmt (z. B. wenn Sie die Datei heruntergeladen haben). 768-v-ema.ckpt Modell, sollten Sie diese Konfigurationsdatei in umbenennen 768-v-ema.yaml und bewahren Sie es auf stable-diffusion-webui/fashions/Secure-diffusion zusammen mit dem Modell).
Ein Secure Diffusion 2.0-Tiefenmodell (512-depth-ema.ckpt) gibt es auch. In diesem Fall sollten Sie das herunterladen v2-midas-inference.yaml Konfigurationsdatei von:
und speichern Sie es im Ordner des Modells unter stable-diffusion-webui/fashions/Secure-diffusion/512-depth-ema.yaml. Dieses Modell funktioniert optimum bei Bildabmessungen von 512 Breite/Höhe oder mehr.
Ein weiterer Ort, an dem Sie Modellkontrollpunkte für die stabile Diffusion finden können, ist https://civitai.com/die Sie auch in den Beispielen sehen können.
Weitere Lektüre
Nachfolgend finden Sie mehrere oben referenzierte Artikel:
Zusammenfassung
In diesem Beitrag haben wir die Grundlagen von Diffusionsmodellen und ihre breite Anwendung in verschiedenen Bereichen kennengelernt. Zusätzlich zur Erweiterung der jüngsten Erfolge bei der Bild- und Videogenerierung diskutierten wir die Prozesse der Vorwärts- und Rückwärtsdiffusion sowie die Modellierung der Posterior-Wahrscheinlichkeit.
Der einzigartige Ansatz von Secure Diffusion besteht darin, hochdimensionale Eingaben in einen reduzierten latenten Raum zu projizieren und so den Rechenaufwand über Encoder- und Decodernetzwerke zu reduzieren.
Im weiteren Verlauf lernen wir die praktischen Aspekte der Generierung von Bildern mithilfe der Secure Diffusion WebUI kennen. Unsere Untersuchung umfasst das Herunterladen von Modellen und die Nutzung der Webschnittstelle zur Bildgenerierung.