
Einführung
Das Hunyuan -Crew von Tencent hat veröffentlicht Hunyuan-mt-7b (ein Übersetzungsmodell) und Hunyuan-mt-chimera-7b (ein Ensemble -Modell). Beide Modelle wurden speziell für die mehrsprachige maschinelle Übersetzung entwickelt und wurden in Verbindung mit Tencents Teilnahme an der eingeführt WMT2025 Allgemeine maschinelle Übersetzung Shared Aufgabewo hunyuan-mt-7b an erster Stelle in den Rang stand 30 von 31 Sprachpaaren.
Modellübersicht
Hunyuan-mt-7b
- A 7B -Parameterübersetzungsmodell.
- Unterstützung gegenseitige Übersetzung über 33 Spracheneinschließlich Chinesische ethnische Minderheitensprachen wie tibetisch, mongolisch, uyghur und kasachisch.
- Für beide optimiert Übersetzungsaufgaben mit hoher Ressourcen und niedriger RessourcenErzielen der neuesten Ergebnisse unter Modellen mit vergleichbarer Größe.
Hunyuan-mt-chimera-7b
- Ein Integriertes Fusionsmodell mit schwachem bis steilem Fusion.
- Kombiniert mehrere Übersetzungsausgänge zum Inferenzzeit und erzeugt eine raffinierte Übersetzung mithilfe von Verstärkungslernen- und Aggregationstechniken.
- Repräsentiert die Erstes Open-Supply-Übersetzungsmodell dieses TypsVerbesserung der Übersetzungsqualität über das Einzelsystem hinaus.
Trainingsrahmen
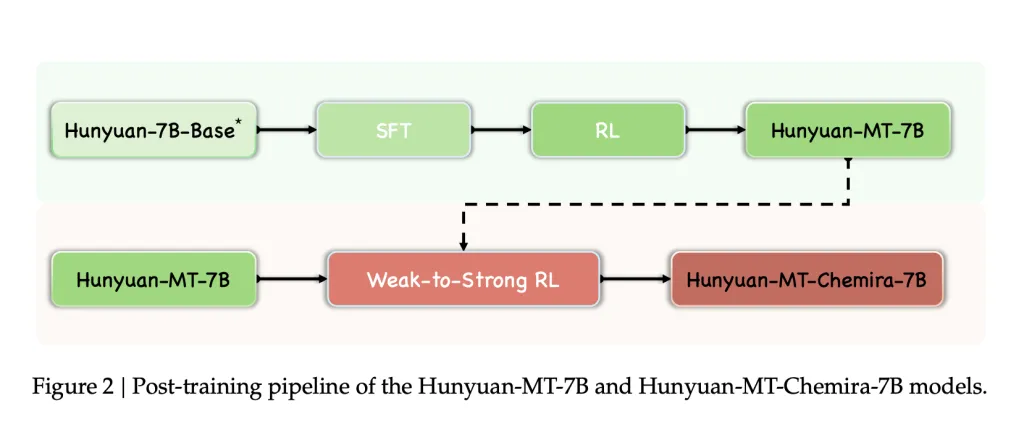
Die Modelle wurden mit a trainiert Fünf-Stufe Framework für Übersetzungsaufgaben entwickelt:
- Allgemeine Vorausbildung
- 1,3 Billionen Token, die 112 Sprachen und Dialekte abdecken.
- Mehrsprachige Korpora, die auf Wissenswert, Authentizität und Schreibstil bewertet wurden.
- Vielfalt, die durch Disziplinar-, Industrie- und thematische Tagging -Systeme aufrechterhalten werden.
- MT-orientiertes Vorverbrauch
- Monolingual Corpora von MC4 und Oscar, gefiltert mit FastText (Sprach -ID), Minlsh (Deduplizierung) und Kenlm (Verwirrungsfilterung).
- Parallele Korpora aus Opus und Parakrawl, gefiltert mit Cometkiwi.
- Wiederholung allgemeiner Voraussetzungsdaten (20%), um katastrophales Vergessen zu vermeiden.
- Übersichtliche Feinabstimmung (SFT)
- Stufe I: ~ 3M Parallelpaare (Flores-200, WMT-Testsätze, kuratierte Mandarin-Minoritätsdaten, synthetische Paare, Anweisungsabfassungsdaten).
- Stufe II: ~ 268K hochwertige Paare, die durch automatisierte Bewertung (Cometkiwi, Gemba) und manuelle Überprüfung ausgewählt wurden.
- Verstärkungslernen (RL)
- Algorithmus: Grpo.
- Belohnungsfunktionen:
- XCOMET-XXL und DEEPSEEK-V3-0324 Treffer für Qualität.
- Terminology-Awesare Rewards (TAT-R1).
- Wiederholungsstrafen, um entartete Ausgaben zu vermeiden.
- Schwaches Rl
- Mehrere Kandidatenausgänge erzeugt und aggregiert durch belohnungsbasierte Ausgabe
- Angewendet in Hunyuan-mt-chimera-7bVerbesserung der Robustheit der Übersetzung und Reduzierung von Wiederholungsfehlern.
Benchmark -Ergebnisse
Automatische Bewertung
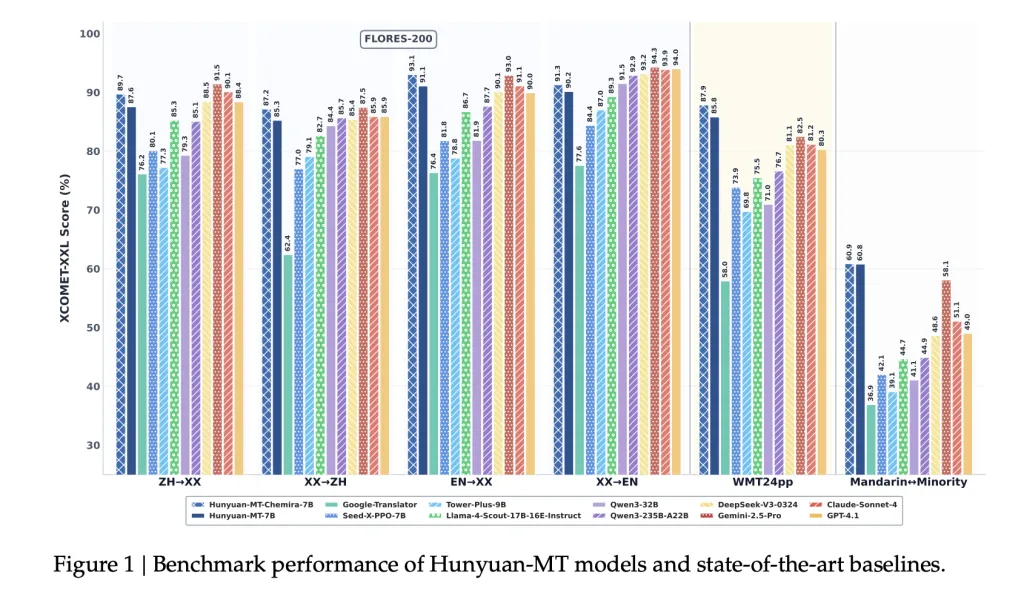
- WMT24PP (englisch⇔xx): Hunyuan-mt-7b erreicht 0,8585 (xcomet-xxl)Übertreffen größerer Modelle wie Gemini-2,5-PRO (0,8250) und Claude-SONNET-4 (0,8120).
- Flores-200 (33 Sprachen, 1056 Paare): Hunyuan-mt-7b erzielte 0,8758 (xcomet-xxl)Outperformance Open-Supply-Baselines einschließlich QWEN3-32B (0,7933).
- Mandarin⇔minoritätssprachen: Erzielte 0,6082 (xcomet-xxl)höher als Gemini-2,5-pro (0,5811), was signifikante Verbesserungen der Einstellungen mit niedrigem Ressourcen zeigt.
Vergleichende Ergebnisse
- Übertreffen Google Übersetzer um 15–65% in den Bewertungskategorien.
- Übertrifft spezielle Übersetzungsmodelle wie z. Turm-Plus-9b Und Seed-X-PPO-7b Trotz weniger Parameter.
- Chimera-7b Fügt ~ 2,3% Verbesserung der Flores-200 hinzu, insbesondere bei chinesischen und nicht englischen Übersetzungen.
Menschliche Bewertung
Ein benutzerdefinierter Bewertungssatz (Abdeckung sozialer, medizinischer, legaler und Web-Domänen) verglichen Hunyuan-MT-7b mit hochmodernen Modellen:
- Hunyuan-mt-7b: Avg. 3.189
- Gemini-2,5-pro: Avg. 3.223
- Deepseek-V3: Avg. 3.219
- Google Translate: Avg. 2.344
Dies zeigt, dass Hunyuan-MT-7B, obwohl er bei 7B-Parametern kleiner ist, der Qualität viel größerer proprietärer Modelle nähert.
Fallstudien
Der Bericht beleuchtet mehrere Fälle in der realen Welt:
- Kulturelle Referenzen: Richtig übersetzt „小红薯“ als Plattform „Rednote“, im Gegensatz zu Google Translate’s „Süßkartoffeln“.
- Redewendungen: Interpretiert „du tötest mich“ als „你真要把我笑死了“ (ausdrückliche Belustigung), wodurch eine buchstäbliche Fehlinterpretation vermieden wird.
- Medizinische Begriffe: Übersetzt präzise „Harnsäure -Nierensteine“, während Baselines missgebildete Ausgaben erzeugen.
- Minderheitensprachen: Für Kasach und Tibetaner produziert Hunyuan-MT-7b zusammenhängende Übersetzungen, bei denen Basislinien nicht an einfachen Textual content ausfallen oder ausgeben.
- Chimera -Verbesserungen: Fügt Verbesserungen in Gaming -Jargon, Verstärker und Sportterminologie hinzu.
Abschluss
Tencents Veröffentlichung von Hunyuan-mt-7b Und Hunyuan-mt-chimera-7b Erstellt einen neuen Normal für Open-Supply-Übersetzungen. Durch die Kombination eines sorgfältig gestalteten Trainingsrahmens mit spezialisiertem Fokus auf Übersetzung mit niedriger Ressourcen und MinderheitenspracheDie Modelle erzielen Qualitätsqualität mit oder übertreffen größere Systeme mit geschlossenen Quellen. Die Einführung dieser beiden Modelle bietet der KI-Forschungsgemeinschaft zugängliche Hochleistungs-Instruments für mehrsprachige Übersetzungsforschung und -einstellung.
Schauen Sie sich das an PapierAnwesend Github -SeiteUnd Modell auf dem Umarmungsgesicht. Alle Krediten für diese Forschung gilt an die Forscher dieses Projekts. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser E-newsletter.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.