Die Kernidee von Chain of Thought (CoT) besteht darin, ein KI-Modell dazu zu ermutigen, Schritt für Schritt zu argumentieren, bevor es eine Antwort liefert. Obwohl das Konzept selbst nicht neu ist und im Wesentlichen eine strukturierte Methode darstellt, Modelle um die Erklärung ihrer Argumentation zu bitten, ist es auch heute noch äußerst related. Das Interesse an CoT nahm erneut zu, nachdem OpenAI eine Vorschau davon veröffentlichte o1-Modelldie den Fokus erneut auf Reasoning-First-Ansätze legt. In diesem Artikel werde ich erklären, was CoT ist, die verschiedenen öffentlich verfügbaren Techniken untersuchen und testen, ob diese Methoden tatsächlich die Leistung moderner KI-Modelle verbessern. Lass uns eintauchen.
Die Forschung hinter der Kette der Gedankenanregung
In den letzten zwei Jahren wurden zahlreiche Forschungsarbeiten zu diesem Thema veröffentlicht. Was mir kürzlich aufgefallen ist, ist Folgendes RePository das wichtige Forschungsergebnisse im Zusammenhang mit Chain of Thought (CoT) zusammenführt.
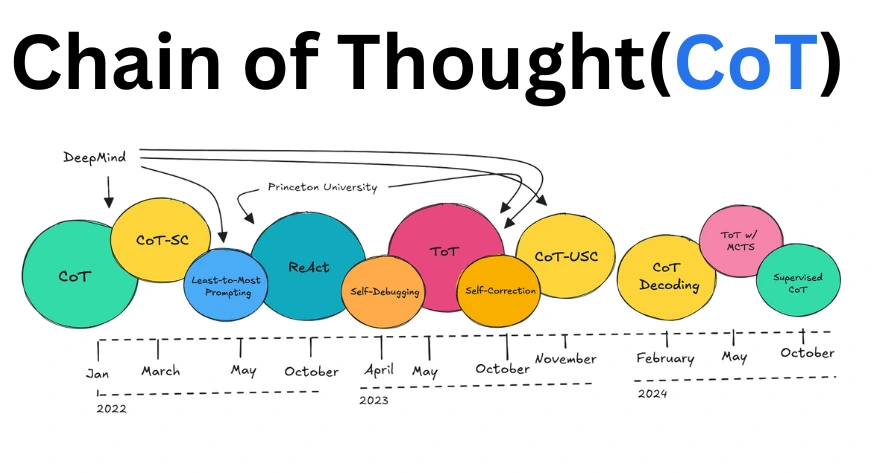
Die verschiedenen Schritt-für-Schritt-Argumentationstechniken, die in diesen Artikeln besprochen werden, sind in der Abbildung unten dargestellt. Ein großer Teil dieser einflussreichen Arbeit stammt direkt von Forschungsgruppen bei DeepMind und Princeton.
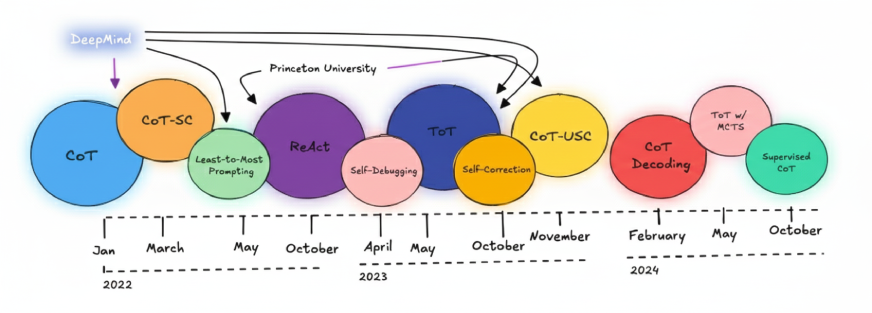
Die COT-Idee wurde erstmals 2022 von DeepMind eingeführt. Seitdem wurden in der neueren Forschung fortgeschrittenere Techniken wie das Kombinieren untersucht Baum der Gedanken (ToT) mit Monte-Carlo-Suchesowie die Verwendung von CoT ohne vorherige Aufforderung, allgemein als Zero-Shot-CoT bezeichnet.
Basiswert von LLMs: Wie die Modellleistung gemessen wird
Bevor wir über Verbesserungen sprechen Große Sprachmodelle (LLMs)müssen wir zunächst eine Möglichkeit finden, zu messen, wie intestine sie heute abschneiden. Diese anfängliche Messung wird als bezeichnet Grundpunktzahl. Eine Baseline hilft uns, die aktuellen Fähigkeiten eines Modells zu verstehen und bietet einen Referenzpunkt dafür bewertend alle Verbesserungstechniken, wie z. B. Chain-of-Thought-Prompting.
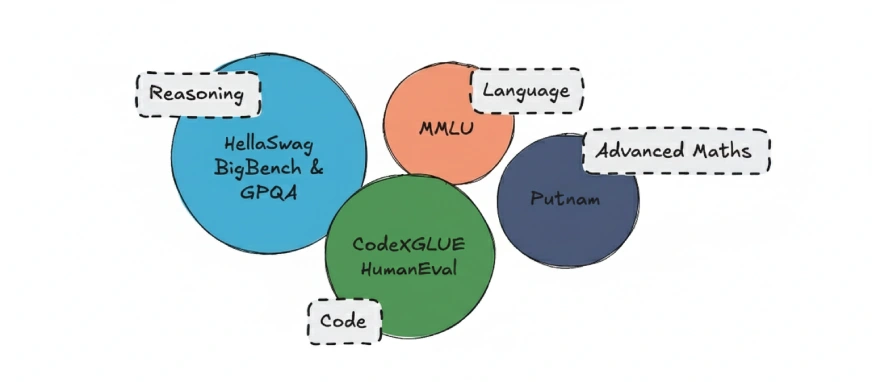
LLMs werden in der Regel anhand standardisierter Benchmarks bewertet. Zu den am häufigsten verwendeten gehören:
- MMLU: Testet das Sprachverständnis
- BigBench: Bewertet die Denkfähigkeit
- HellaSwag: Misst vernünftiges Denken
Allerdings sollten nicht alle Benchmark-Ergebnisse für naked Münze genommen werden. Viele gängige Evaluierungsdatensätze sind mehrere Jahre alt und können unter Datenverunreinigungen leiden, was bedeutet, dass Modelle Teile der Testdaten während des Trainings möglicherweise indirekt gesehen haben. Dies kann die gemeldeten Ergebnisse erhöhen und ein irreführendes Bild der tatsächlichen Modellleistung vermitteln.
Um dieses Drawback anzugehen, sind neuere Evaluierungsbemühungen entstanden. Beispielsweise hat Hugging Face ein Replace veröffentlicht LLM-Bestenliste das setzt auf frischere, weniger kontaminierte Testsätze. Bei diesen neueren Benchmarks schneiden die meisten Modelle deutlich schlechter ab als bei älteren Datensätzen, was verdeutlicht, wie empfindlich Bewertungen auf die Benchmark-Qualität reagieren.
Aus diesem Grund ist es genauso wichtig zu verstehen, wie LLMs bewertet werden, wie sich die Ergebnisse selbst anzusehen. In vielen realen Umgebungen entscheiden sich Organisationen dafür, personal, interne Bewertungssätze zu erstellen, die auf ihre Anwendungsfälle zugeschnitten sind und oft eine zuverlässigere und aussagekräftigere Foundation liefern als öffentliche Benchmarks allein.
Lesen Sie auch: 14 beliebte LLM-Benchmarks, die Sie im Jahr 2026 kennen sollten
Excessive-Degree-Ansicht der Chain of Thought (CoT)
Chain of Thought wurde vom Mind Crew von DeepMind in seiner Arbeit aus dem Jahr 2022 vorgestellt Die Aufforderung zur Gedankenkette löst Argumentation in großen Sprachmodellen aus.
Während die Idee des schrittweisen Denkens nicht neu ist, erlangte CoT nach der Veröffentlichung des o1-Modells von OpenAI erneut Aufmerksamkeit, wodurch die Schlussfolgerung zuerst wieder in den Fokus gerückt wurde. In dem DeepMind-Artikel wurde untersucht, wie sorgfältig gestaltete Eingabeaufforderungen große Sprachmodelle dazu anregen können, expliziter zu argumentieren, bevor sie eine Antwort liefern.
Chain of Thought ist eine Aufforderungstechnik, die die inhärente Denkfähigkeit eines Modells aktiviert, indem sie es dazu ermutigt, ein Drawback in kleinere, logische Schritte zu unterteilen, anstatt direkt zu antworten. Dies macht es besonders nützlich für Aufgaben, die mehrstufiges Denken erfordern, wie etwa Mathematik, Logik und das Verständnis des gesunden Menschenverstandes.
Zum Zeitpunkt der Einführung dieser Forschung stützten sich die meisten Eingabeaufforderungsansätze hauptsächlich auf einmalige oder wenige Eingabeaufforderungen, ohne den Argumentationsprozess des Modells explizit zu steuern.
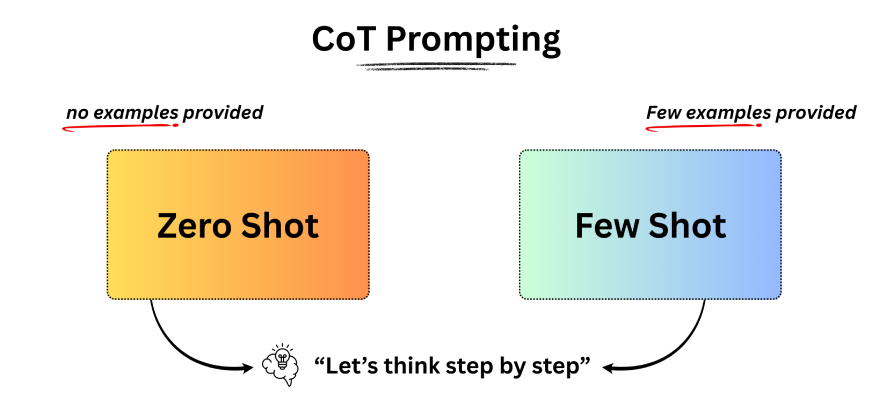
Zero-Shot-Eingabeaufforderung verstehen
Zero-Shot-Eingabeaufforderung bedeutet, ein Modell zu bitten, eine Aufgabe auszuführen, ohne Beispiele oder vorherigen Kontext anzugeben. Zum Beispiel öffnen Sie ChatGPT oder ein anderes Argumentationsmodell und stellen Sie direkt eine Frage. Das Modell verlässt sich vollständig auf sein vorhandenes Wissen, um eine Antwort zu generieren.
In diesem Setup enthält die Eingabeaufforderung keine Beispiele, dennoch kann der LLM die Aufgabe verstehen und eine sinnvolle Antwort geben. Diese Fähigkeit spiegelt die Nullschussfähigkeit des Modells wider. Dann stellt sich natürlich die Frage: Können wir die Nullschussleistung verbessern? Die Antwort lautet: Ja, durch eine Technik namens Instruction Tuning. Erfahren Sie mehr darüber Hier.
Bei der Anweisungsoptimierung geht es darum, ein Modell nicht nur anhand von Rohtext zu trainieren, sondern auch anhand von Datensätzen, die als Anweisungen und entsprechende Antworten formatiert sind. Dadurch lernt das Modell, Anweisungen effektiver zu befolgen, selbst bei Aufgaben, die es zuvor noch nie explizit gesehen hat. Infolgedessen schneiden auf Anweisungen abgestimmte Modelle in Zero-Shot-Einstellungen deutlich besser ab.
Verstärkungslernen aus menschlichem Suggestions (RLHF) verbessert diesen Prozess weiter, indem die Modellergebnisse an menschlichen Vorlieben ausgerichtet werden. Vereinfacht ausgedrückt bringt die Anweisungsoptimierung dem Modell bei, auf Anweisungen zu reagieren, während RLHF ihm beibringt, auf eine Weise zu reagieren, die Menschen als nützlich und angemessen erachten.
Beliebte Modelle wie ChatGPT, Claude, Mistral und Phi-3 Verwenden Sie eine Kombination aus Befehlsoptimierung und RLHF. Es gibt jedoch immer noch Fälle, in denen die Zero-Shot-Eingabeaufforderung unzureichend sein kann. In solchen Situationen kann die Bereitstellung einiger Beispiele in der Eingabeaufforderung, die sogenannte Wenig-Schuss-Eingabeaufforderung, zu besseren Ergebnissen führen.
Lesen Sie auch: Foundation LLM vs. anweisungsgesteuertes LLM
Grundlegendes zur Few-Shot-Eingabeaufforderung
Die Wenig-Schuss-Eingabeaufforderung ist nützlich, wenn die Null-Schuss-Eingabeaufforderung zu inkonsistenten Ergebnissen führt. Bei diesem Ansatz erhält das Modell innerhalb der Eingabeaufforderung eine kleine Anzahl von Beispielen, um sein Verhalten zu steuern. Dies ermöglicht kontextbezogenes Lernen, bei dem das Modell Muster aus Beispielen ableitet und diese auf neue Eingaben anwendet. Forschung von Kaplan et al. (2020) Und Touvron et al. (2023) zeigt, dass diese Fähigkeit mit zunehmender Skalierung der Modelle zum Vorschein kommt.
Wichtige Beobachtungen zum Wenig-Schuss-Prompting:
- LLMs lassen sich intestine verallgemeinern, selbst wenn Beispielbezeichnungen randomisiert sind.
- Modelle bleiben sturdy gegenüber Änderungen oder Verzerrungen im Eingabeformat.
- Die Eingabeaufforderung mit wenigen Schüssen verbessert häufig die Genauigkeit im Vergleich zur Eingabeaufforderung mit null Schüssen.
- Es hat Schwierigkeiten mit Aufgaben, die mehrstufiges Denken erfordern, wie zum Beispiel komplexe Arithmetik.
Wenn Zero-Shot- und Fence-Shot-Prompting nicht ausreichen, sind fortgeschrittenere Techniken wie Chain of Thought-Prompting erforderlich, um tiefergehende Argumentationsaufgaben zu bewältigen.
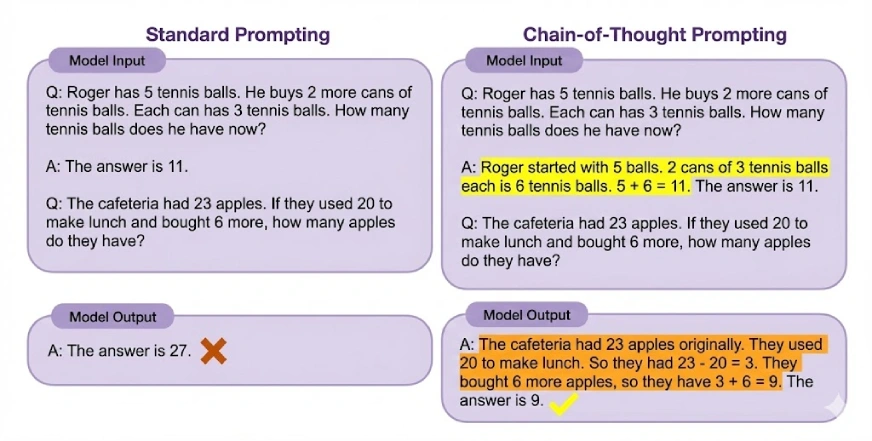
Gedankenkette (CoT) verstehen
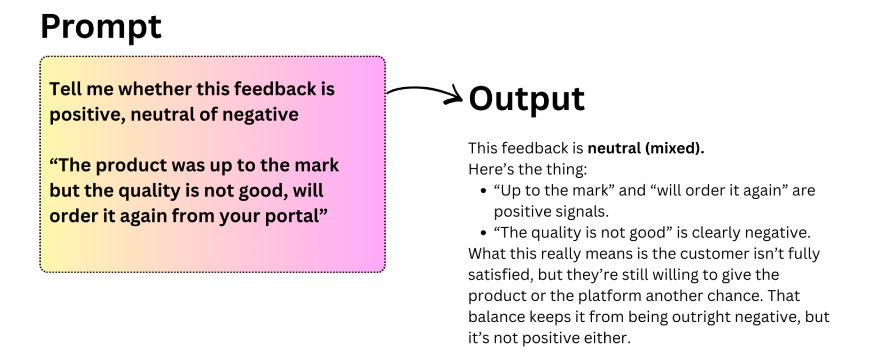
Chain of Thought (CoT)-Prompting ermöglicht komplexes Denken, indem es ein Modell dazu anregt, Zwischenschritte zu generieren, bevor es zu einer endgültigen Antwort gelangt. Durch die Unterteilung von Problemen in kleinere, logische Schritte unterstützt CoT LLMs bei der Bewältigung von Aufgaben, die mehrstufiges Denken erfordern. Für eine noch bessere Leistung kann es auch mit der Eingabeaufforderung für wenige Schüsse kombiniert werden.
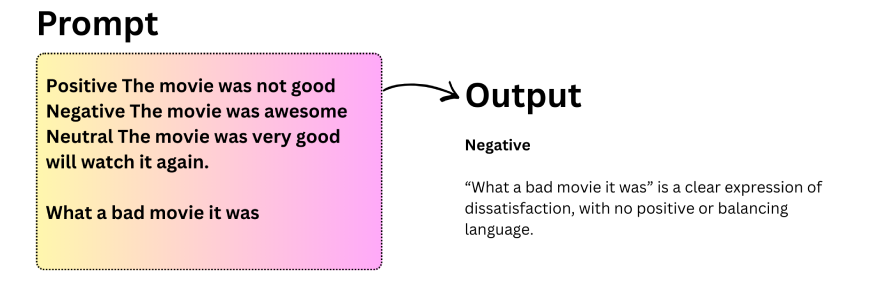
Lassen Sie uns mit der Aufforderung „Chain of Thought“ experimentieren:
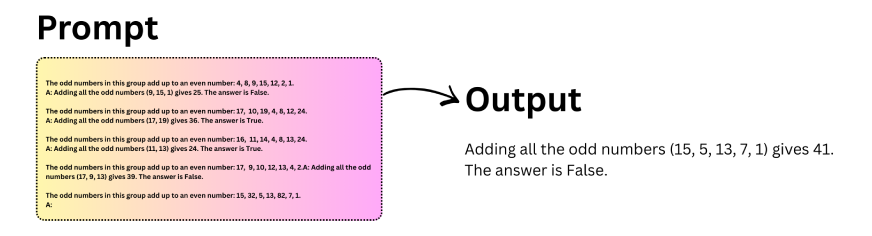
Eine weit verbreitete Variante dieses Ansatzes ist die Zero-Shot Chain of Thought. Anstatt Beispiele anzugeben, fügen Sie der Aufforderung einfach eine kurze Anweisung wie „Lass uns Schritt für Schritt denken“ hinzu. Diese kleine Änderung reicht oft aus, um eine strukturierte Argumentation im Modell auszulösen.
Lassen Sie uns dies anhand eines Beispiels verstehen:
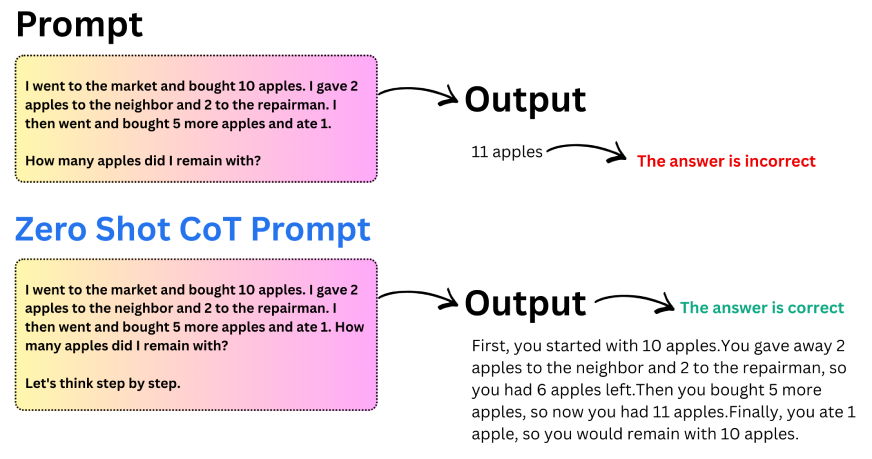
Wichtige Erkenntnisse aus Zero-Shot CoT:
- Durch das Hinzufügen einer einzelnen Argumentationsanweisung kann die Genauigkeit erheblich verbessert werden.
- Modelle liefern strukturiertere und logischere Antworten.
- Zero-Shot-CoT ist nützlich, wenn keine Beispiele verfügbar sind.
- Es eignet sich besonders intestine für Aufgaben im Bereich Arithmetik und logisches Denken.
Diese einfache, aber leistungsstarke Technik zeigt, wie geringfügige Änderungen in der Eingabeaufforderung zu bedeutenden Verbesserungen der Modellbegründung führen können.
Automatische Gedankenkette (Auto-CoT)
Bei der Normal-Gedankenkettenaufforderung müssen Menschen manuell Argumentationsbeispiele erstellen, was zeitaufwändig und fehleranfällig ist. Frühere Versuche, diesen Prozess zu automatisieren, hatten oft mit verrauschten oder falschen Überlegungen zu kämpfen. Auto-CoT geht dieses Drawback an, indem es die Vielfalt der von ihm generierten Argumentationsbeispiele betont und so die Auswirkungen einzelner Fehler verringert.
Anstatt sich auf sorgfältig geschriebene Eingabeaufforderungen zu verlassen, wählt Auto-CoT automatisch repräsentative Fragen aus einem Datensatz aus und generiert dafür Argumentationsketten. Dies macht den Ansatz skalierbarer und weniger abhängig von menschlichem Aufwand.
Auto-CoT funktioniert in zwei Stufen:
- Stufe 1 – Clustering: Fragen aus dem Datensatz werden basierend auf ihrer Ähnlichkeit in Cluster gruppiert. Dies gewährleistet die Abdeckung verschiedener Problemtypen.
- Stufe 2 – Probenahme: Aus jedem Cluster wird eine repräsentative Frage ausgewählt und eine Argumentationskette dafür generiert. Um die Argumentationsqualität aufrechtzuerhalten, werden einfache Heuristiken wie die Bevorzugung kürzerer Fragen verwendet.
Durch den Fokus auf Diversität und Automatisierung ermöglicht Auto-CoT eine skalierbare Chain-of-Thought-Einleitung, ohne dass manuell erstellte Beispiele erforderlich sind.
Lesen Sie auch: 17 Aufforderungstechniken, um Ihre LLMs zu verbessern
Abschluss
Chain-of-Thought-Prompting verändert die Artwork und Weise, wie wir mit großen Sprachmodellen arbeiten, indem es schrittweises Denken anstelle von einmaligen Antworten fördert. Dies ist wichtig, da selbst starke LLMs oft mit Aufgaben zu kämpfen haben, die mehrstufiges Denken erfordern, obwohl sie über das nötige Wissen verfügen.
Durch die explizite Gestaltung des Argumentationsprozesses verbessert Chain-of-Thought kontinuierlich die Leistung bei Aufgaben wie Mathematik, Logik und logischem Denken. Die automatische Gedankenkette baut darauf auf, indem sie den manuellen Aufwand reduziert und strukturiertes Denken einfacher skalierbar macht.
Die wichtigste Erkenntnis ist einfach: Besseres Denken erfordert nicht immer größere Modelle oder Umschulung. Oft kommt es auf eine bessere Aufforderung an. Chain-of-Thought bleibt eine praktische und effektive Möglichkeit, die Zuverlässigkeit in modernen LLMs zu verbessern.
Häufig gestellte Fragen
A. Bei der Eingabeaufforderung zur Gedankenkette handelt es sich um eine Technik, bei der Sie ein KI-Modell bitten, seine Argumentation Schritt für Schritt zu erklären, bevor Sie die endgültige Antwort geben. Dies hilft dem Modell, komplexe Probleme in kleinere, logische Schritte zu unterteilen.
A. Bei Antworten im TCS-Stil bedeutet die Aufforderung zur Gedankenkette, klare Zwischenschritte zu schreiben, um zu zeigen, wie eine Lösung erreicht wird. Der Schwerpunkt liegt auf logischem Denken, strukturierter Erklärung und Klarheit, anstatt direkt zur endgültigen Antwort zu springen.
A. Die Aufforderung zur Gedankenkette ist effektiv, weil sie das Modell Schritt für Schritt zur Schlussfolgerung führt. Dies reduziert Fehler, verbessert die Genauigkeit bei komplexen Aufgaben und hilft dem Modell, mathematische, logische und mehrstufige Argumentationsprobleme besser zu bewältigen.
A. Die Gedankenkette zeigt Argumentationsschritte innerhalb einer einzelnen Antwort, während die Verkettung von Eingabeaufforderungen eine Aufgabe in mehrere Eingabeaufforderungen aufteilt. CoT konzentriert sich auf internes Denken, während Immediate Chaining Arbeitsabläufe über mehrere Modellaufrufe hinweg verwaltet.
A. Zu den wichtigsten Schritten in Chain of Thought gehört es, das Drawback zu verstehen, es in kleinere Teile zu zerlegen, jeden Schritt logisch zu durchdenken und diese Schritte dann zu kombinieren, um zu einer endgültigen, intestine begründeten Antwort zu gelangen.
A. Der Einsatz von CoT verbessert die Argumentationsgenauigkeit, reduziert logische Fehler und macht KI-Antworten transparenter. Es eignet sich besonders intestine für komplexe Aufgaben wie Arithmetik, logische Rätsel und Entscheidungsprobleme, die mehrere Denkschritte erfordern.
Wachstumshacker | Generative KI | LLMs | RAGs | Feinabstimmung | Über 62.000 Follower https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/ https://www.linkedin.com/in/harshit-ahluwalia/
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.