Große KI-Modelle skalieren schnell, wobei größere Architekturen und längere Trainingsläufe zur Norm werden. Da die Modelle jedoch wachsen, bleibt ein grundlegendes Drawback der Trainingsstabilität ungelöst. DeepSeek mHC geht dieses Drawback direkt an, indem es neu überdenkt, wie sich verbleibende Verbindungen im großen Maßstab verhalten. Dieser Artikel erklärt DeepSeek mHC (Manifold-Constrained Hyper-Connections) und zeigt, wie es verbessert wird großes Sprachmodell Stabilität und Leistung trainieren, ohne unnötige architektonische Komplexität hinzuzufügen.
Das versteckte Drawback mit Relaxation- und Hyperverbindungen
Restverbindungen sind seit der Veröffentlichung von ein zentraler Baustein des Deep Studying ResNet im Jahr 2016. Sie ermöglichen es Netzwerken, Abkürzungspfade zu schaffen, sodass Informationen direkt durch Schichten fließen können, anstatt bei jedem Schritt neu gelernt zu werden. Vereinfacht ausgedrückt verhalten sie sich wie Schnellstraßen auf einer Autobahn und erleichtern so das Trainieren tiefer Netzwerke.
Dieser Ansatz hat jahrelang intestine funktioniert. Doch als die Modelle von Millionen auf Milliarden und mittlerweile Hunderte von Milliarden Parametern skaliert wurden, wurden ihre Grenzen deutlich. Um die Leistung weiter zu steigern, führten die Forscher Hyper-Connections (HC) ein und erweiterten diese Informationsautobahnen effektiv durch das Hinzufügen weiterer Pfade. Die Leistung verbesserte sich spürbar, die Stabilität jedoch nicht.
Das Coaching wurde äußerst instabil. Die Modelle würden regular trainieren und dann bei einem bestimmten Schritt plötzlich zusammenbrechen, mit starken Verlustspitzen und explodierenden Gradienten. Für Groups, die große Sprachmodelle trainieren, kann ein solcher Fehler bedeuten, dass enorme Mengen an Rechenleistung, Zeit und Ressourcen verschwendet werden.
Was sind mannigfaltig eingeschränkte Hyperverbindungen (mHC)?
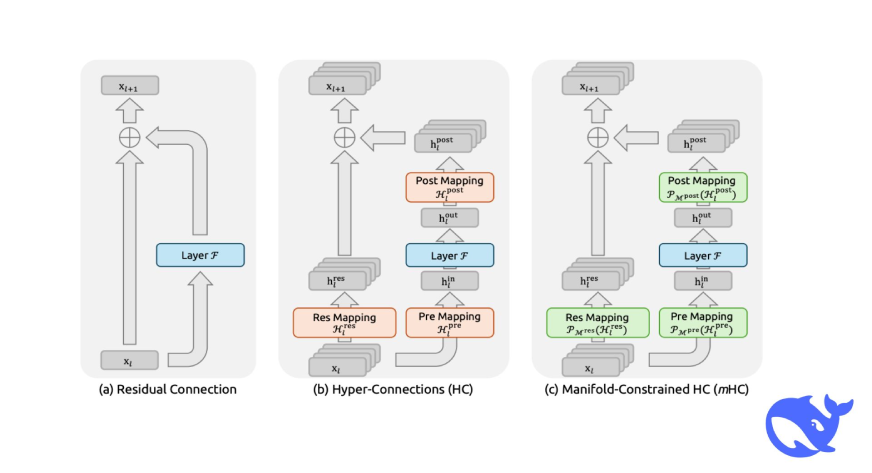
Es handelt sich um ein allgemeines Framework, das den verbleibenden Verbindungsraum von HC einer bestimmten Mannigfaltigkeit zuordnet, um die Eigenschaft der Identitätszuordnung zu stärken, und gleichzeitig eine strikte Optimierung der Infrastruktur erfordert, um effizient zu sein.
Empirische Checks zeigen, dass sich mHC intestine für groß angelegte Schulungen eignet und nicht nur deutliche Leistungssteigerungen, sondern auch eine hervorragende Skalierbarkeit bietet. Wir erwarten, dass mHC als vielseitige und zugängliche Ergänzung zu HC zum Verständnis des topologischen Architekturdesigns beiträgt und neue Wege für die Entwicklung grundlegender Modelle vorschlägt.
Was macht mHC anders?
Die Strategie von DeepSeek ist nicht nur klug, sie ist auch brillant, weil sie Sie zum Nachdenken bringt: „Oh, warum hat noch nie jemand daran gedacht?“ Sie behielten weiterhin die Hyperverbindungen bei, beschränkten sie jedoch durch eine präzise mathematische Methode.
Dies ist der technische Teil (geben Sie mich nicht auf, es wird sich lohnen, ihn zu verstehen): Normal-Restverbindungen ermöglichen die Durchführung einer sogenannten „Identitätszuordnung“. Stellen Sie es sich wie das Energieerhaltungsgesetz vor, bei dem Signale mit dem gleichen Leistungsniveau durch das Netzwerk übertragen werden. Als HC die Breite des Reststroms vergrößerte und ihn mit lernbaren Verbindungsmustern kombinierte, verletzten sie diese Eigenschaft unbeabsichtigt.
Die Forscher von DeepSeek haben herausgefunden, dass die zusammengesetzten Zuordnungen von HC im Wesentlichen, wenn man diese Verbindungen Schicht für Schicht stapelt, die Signale um Multiplikatoren um das 3000-fache oder sogar mehr verstärken. Stellen Sie sich vor, Sie inszenieren einen Dialog und jedes Mal, wenn jemand Ihre Botschaft übermittelt, schreit der ganze Raum diese 3000-mal lauter. Das ist nichts als Chaos.
mHC löst das Drawback, indem es diese Verbindungsmatrizen auf das Birkhoff-Polytop projiziert, ein abstraktes geometrisches Objekt, in dem jede Zeile und Spalte eine Summe von 1 hat. Es magazine theoretisch erscheinen, aber in Wirklichkeit führt es dazu, dass das Netzwerk die Signalausbreitung als eine konvexe Kombination von Merkmalen behandelt. Keine Explosionen mehr, keine Signale, die vollständig verschwinden.
Die Architektur: Wie mHC tatsächlich funktioniert
Lassen Sie uns die Particulars untersuchen, wie DeepSeek die Verbindungen innerhalb des Modells verändert hat. Das Design hängt von drei Hauptzuordnungen ab, die die Richtung der Informationen bestimmen:
Das Drei-Mapping-System
In Hyper-Connections erfüllen drei lernbare Matrizen unterschiedliche Aufgaben:
- H_pre: Übernimmt die Informationen aus dem erweiterten Reststrom in die Ebene
- H_post: Sendet die Ausgabe der Ebene zurück an den Stream
- H_res: Kombiniert und aktualisiert die Informationen im Stream selbst
Stellen Sie es sich als Autobahnsystem vor, bei dem H_pre die Auffahrt, H_post die Ausfahrt und H_res der Verkehrsflussmanager zwischen den Fahrspuren ist.
Eines der Ergebnisse der Ablationsstudien von DeepSeek ist sehr interessant: H_res (die auf die Residuen angewendete Zuordnung) trägt hauptsächlich zur Leistungssteigerung bei. Sie haben es ausgeschaltet und nur Pre- und Put up-Mappings zugelassen, was zu einem drastischen Leistungsabfall geführt hat. Das ist logisch: Der Höhepunkt des Prozesses besteht darin, dass Options aus unterschiedlichen Tiefen interagieren und Informationen austauschen können.
Die Mannigfaltigkeitsbeschränkung
Dies ist der Punkt, an dem mHC beginnt, vom regulären HC abzuweichen. Anstatt zuzulassen, dass H_res willkürlich ausgewählt wird, erzwingen sie, dass es doppelt stochastisch ist, was ein Merkmal ist, bei dem sich jede Zeile und jede Spalte zu 1 summiert.
Welche Bedeutung hat das? Es gibt drei Hauptgründe:
- Normen bleiben erhalten: Die spektrale Norm wird innerhalb der Grenzen von 1 gehalten, sodass Gradienten nicht explodieren können.
- Schließung unter Zusammensetzung: Die Verdoppelung doppelt stochastischer Matrizen führt zu einer weiteren doppelt stochastischen Matrix; Daher ist die gesamte Netzwerktiefe weiterhin stabil.
- Eine Veranschaulichung in Bezug auf die Geometrie: Die Matrizen liegen im Birkhoff-Polytop, der konvexen Hülle aller Permutationsmatrizen. Anders ausgedrückt: Das Netzwerk lernt gewichtete Kombinationen von Routing-Mustern, bei denen der Informationsfluss unterschiedlich ist.
Zur Durchsetzung dieser Einschränkung wird der Sinkhorn-Knopp-Algorithmus verwendet. Hierbei handelt es sich um eine iterative Methode, die abwechselnd Zeilen und Spalten normalisiert, bis die gewünschte Genauigkeit erreicht ist. In den Experimenten wurde festgestellt, dass 20 Iterationen eine geeignete Näherung ohne übermäßigen Rechenaufwand ergeben.
Parametrierungsdetails
Die Ausführung ist good. Anstatt an einzelnen Merkmalsvektoren zu arbeiten, komprimiert mHC die gesamte verborgene n×C-Matrix in einen Vektor. Dadurch können die vollständigen Kontextinformationen bei der Berechnung des dynamischen Mappings verwendet werden.
Es gelten die letzten eingeschränkten Zuordnungen:
- Sigmoid-Aktivierung für H_pre und H_post (wodurch Nichtnegativität garantiert wird)
- Sinkhorn-Knopp-Projektion für H_res (wodurch doppelte Stochastik erzwungen wird)
- Kleine Initialisierungswerte (α = 0,01) für Gating-Faktoren, zunächst konservativ
Diese Konfiguration stoppt die durch Wechselwirkungen zwischen positiv-negativen Koeffizienten verursachte Signalauslöschung und behält gleichzeitig die sehr wichtige Identitätsabbildungseigenschaft bei.
Skalierungsverhalten: Hält es stand?
Eines der erstaunlichsten Dinge ist, wie sich die Vorteile von mHC skalieren. DeepSeek führte seine Experimente in drei verschiedenen Dimensionen durch:
- Computing-Skalierung: Sie trainierten die Parameter 3B, 9B und 27B mit proportionalen Daten. Der Leistungsvorteil blieb gleich und nahm bei höheren Rechenbudgets sogar leicht zu. Das ist unglaublich, denn normalerweise funktionieren viele architektonische Tips, die im Kleinen funktionieren, bei der Vergrößerung nicht.
- Token-Skalierung: Sie überwachten die Leistung während des Trainings ihres 3B-Modells, das auf 1 Billion Token trainiert wurde. Die Verlustverbesserung conflict vom sehr frühen Coaching bis zur Konvergenzphase stabil, was darauf hindeutet, dass die Vorteile von mHC nicht auf die frühe Trainingsphase beschränkt sind.
- Ausbreitungsanalyse: Erinnern Sie sich an die 3000-fachen Signalverstärkungsfaktoren in Vanilla HC? Mit mHC wurde die maximale Verstärkungsgröße auf etwa 1,6 reduziert, was drei Größenordnungen stabiler ist. Selbst nach der Zusammenstellung von mehr als 60 Schichten blieben die Vorwärts- und Rückwärtssignalverstärkungen intestine kontrolliert.
Leistungsbenchmarks
DeepSeek evaluierte mHC anhand verschiedener Modelle mit Parametergrößen zwischen 3 und 27 Milliarden und die Stabilitätsgewinne waren besonders sichtbar:
- Der Trainingsverlust verlief während des gesamten Prozesses reibungslos und es gab keine plötzlichen Spitzen
- Die Gradientennormen blieben im gleichen Bereich, im Gegensatz zu HC, das wildes Verhalten zeigte
- Das Wichtigste conflict, dass sich die Leistung nicht nur verbesserte, sondern sich auch in mehreren Benchmarks zeigte
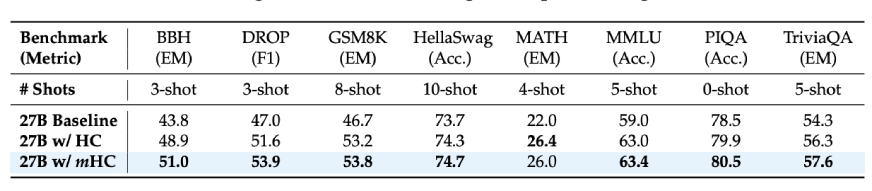
Wenn wir die Ergebnisse der nachgelagerten Aufgaben für das 27B-Modell betrachten:
- BBH-Argumentationsaufgaben: 51,0 % (vs. 43,8 % im Ausgangswert)
- DROP-Leseverständnis: 53,9 % (vs. 47,0 % Ausgangswert)
- GSM8K-Matheaufgaben: 53,8 % (im Vergleich zu 46,7 % im Ausgangswert)
- MMLU-Kenntnisse: 63,4 % (vs. 59,0 % im Ausgangswert)
Dabei handelt es sich nicht um geringfügige Verbesserungen, sondern tatsächlich handelt es sich um 7-10-Punkte-Steigerungen bei Benchmarks für schwieriges Denken. Darüber hinaus zeigten sich diese Verbesserungen nicht nur bei den größeren Modellen, sondern auch bei längeren Trainingszeiten, was bei der Skalierung der Deep-Studying-Modelle der Fall conflict.
Lesen Sie auch: DeepSeek-V3.2-Exp: 50 % günstiger, 3x schneller, maximaler Wert
Abschluss
Wenn Sie an großen Sprachmodellen arbeiten oder diese trainieren, ist mHC ein Aspekt, den Sie unbedingt berücksichtigen sollten. Es ist eines dieser seltenen Papiere, das ein echtes Drawback identifiziert, eine mathematisch gültige Lösung präsentiert und sogar beweist, dass es im großen Maßstab funktioniert.
Die wichtigsten Enthüllungen sind:
- Eine Erhöhung der Reststrombreite führt zu einer besseren Leistung; Allerdings verursachen naive Methoden Instabilität
- Durch die Beschränkung der Interaktionen auf doppelt stochastische Matrizen bleiben die Identitätsabbildungseigenschaften erhalten
- Wenn es richtig gemacht wird, kann der Overhead kaum spürbar sein
- Die Vorteile können auf Modelle mit einer Größe von mehreren zehn Milliarden Parametern übertragen werden
Darüber hinaus erinnert mHC daran, dass die architektonische Gestaltung immer noch ein entscheidender Faktor ist. Die Frage, wie mehr Rechenleistung und Daten genutzt werden können, kann nicht ewig bestehen bleiben. Es wird Zeiten geben, in denen es notwendig ist, einen Schritt zurückzutreten, die Ursache des Fehlers im großen Maßstab zu verstehen und ihn ordnungsgemäß zu beheben.
Und um ehrlich zu sein: Solche Recherchen gefallen mir am besten. Es müssen keine kleinen Änderungen vorgenommen werden, sondern tiefgreifende Änderungen, die das gesamte Feld etwas robuster machen.
Gen AI-Praktikant bei Analytics Vidhya
Abteilung für Informatik, Vellore Institute of Know-how, Vellore, Indien
Derzeit arbeite ich als Gen AI-Praktikant bei Analytics Vidhya, wo ich zu innovativen KI-gesteuerten Lösungen beitrage, die Unternehmen in die Lage versetzen, Daten effektiv zu nutzen. Als Informatikstudent im Abschlussjahr am Vellore Institute of Know-how bringe ich solide Grundlagen in Softwareentwicklung, Datenanalyse und maschinellem Lernen in meine Rolle ein.
Kontaktieren Sie mich gerne unter (e-mail protected)
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.