Wie weit kann ein mittelgroßes Sprachmodell gehen, wenn die eigentliche Innovation vom Spine in das Agentengerüst und den Instrument-Stack verlagert wird? Meta- und Harvard-Forscher haben den Confucius Code Agent veröffentlicht, einen Open-Supply-KI-Softwareentwickler, der auf dem Confucius SDK basiert und für Software program-Repositories im industriellen Maßstab und lang laufende Sitzungen konzipiert ist. Das System zielt auf echte GitHub-Projekte, komplexe Take a look at-Toolchains zum Zeitpunkt der Evaluierung und reproduzierbare Ergebnisse bei Benchmarks wie SWE Bench Professional und SWE Bench Verified ab und stellt gleichzeitig das gesamte Gerüst für Entwickler bereit.
Konfuzius SDK, Gerüst rund um das Modell
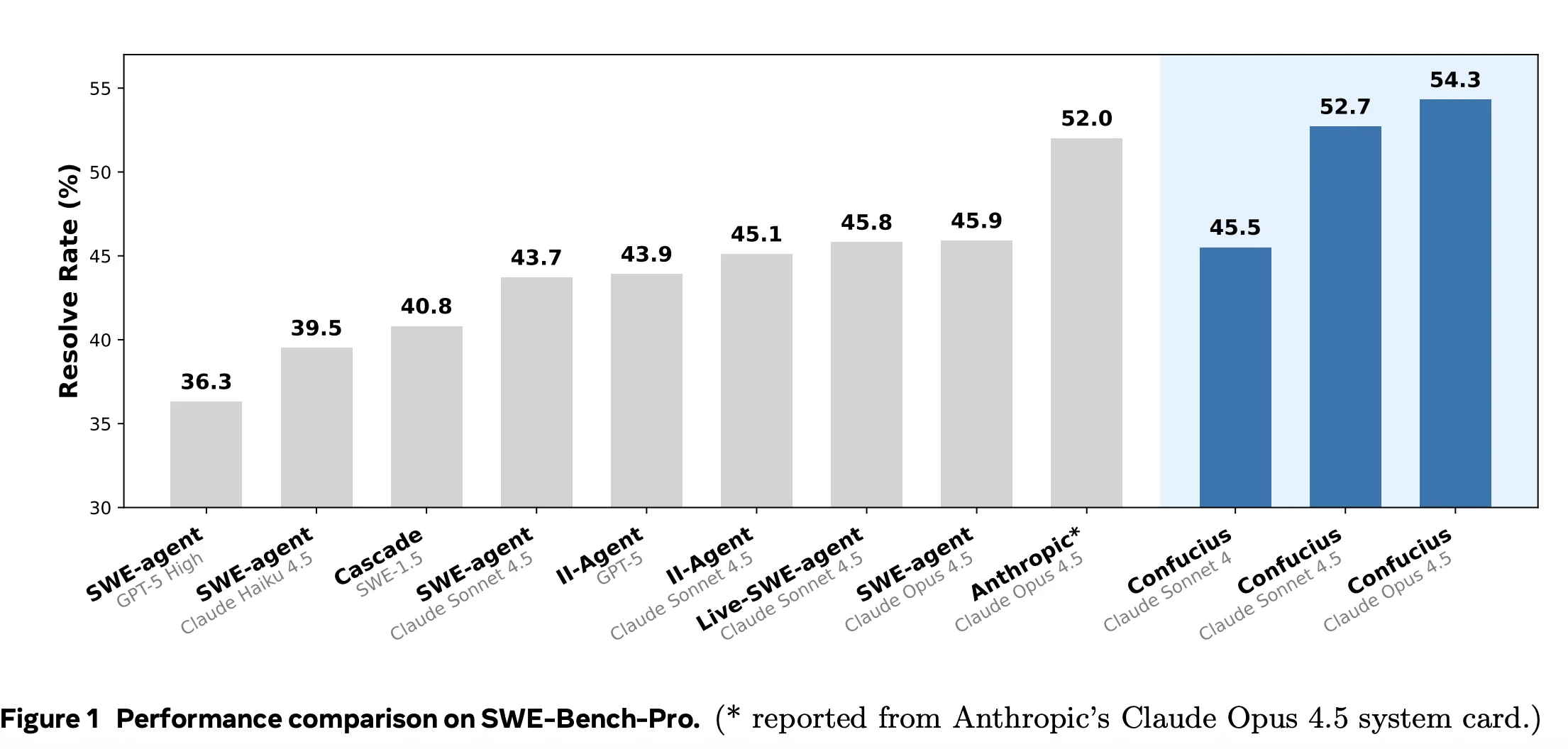
Das Confucius SDK ist eine Agentenentwicklungsplattform, die Gerüstbau als primäres Designproblem und nicht als dünne Hülle um ein Sprachmodell behandelt. Es ist um 3 Achsen herum organisiert, Agentenerfahrung, Benutzererfahrung und Entwicklererfahrung.
Agentenerfahrung steuert, was das Modell sieht, einschließlich Kontextlayout, Arbeitsspeicher und Werkzeugergebnisse. Benutzererfahrung Der Schwerpunkt liegt auf lesbaren Spuren, Codeunterschieden und Schutzmaßnahmen für menschliche Ingenieure. Entwicklererfahrung Der Schwerpunkt liegt auf der Beobachtbarkeit, Konfiguration und dem Debuggen des Agenten selbst.
Das SDK führt drei Kernmechanismen ein: einen einheitlichen Orchestrator mit hierarchischem Arbeitsspeicher, ein dauerhaftes Notizensystem und eine modulare Erweiterungsschnittstelle für Instruments. Ein Meta-Agent automatisiert dann die Synthese und Verfeinerung von Agent-Konfigurationen durch eine Schleife zum Erstellen, Testen und Verbessern. Der Confucius Code Agent ist eine konkrete Instanziierung dieses Gerüsts für die Softwareentwicklung.
Hierarchischer Arbeitsspeicher für Codierung über einen langen Zeitraum
Echte Softwareaufgaben auf SWE Bench Professional erfordern oft das Nachdenken über Dutzende Dateien und viele Interaktionsschritte. Der Orchestrator im Confucius SDK unterhält einen hierarchischen Arbeitsspeicher, der eine Trajektorie in Bereiche unterteilt, vergangene Schritte zusammenfasst und komprimierten Kontext für spätere Runden bereithält.
Dieses Design trägt dazu bei, Eingabeaufforderungen innerhalb der Modellkontextgrenzen zu halten und gleichzeitig wichtige Artefakte wie Patches, Fehlerprotokolle und Designentscheidungen beizubehalten. Der entscheidende Punkt ist, dass effektive, werkzeugbasierte Codierungsagenten eine explizite Speicherarchitektur benötigen und nicht nur ein Schiebefenster früherer Nachrichten.
Ständiges Notieren für sitzungsübergreifendes Lernen
Der zweite Mechanismus ist ein Notizensystem, das einen dedizierten Agenten verwendet, um strukturierte Markdown-Notizen aus Ausführungsspuren zu schreiben. Diese Notizen erfassen aufgabenspezifische Strategien, Repository-Konventionen und häufige Fehlermodi und werden im Langzeitspeicher gespeichert, der sitzungsübergreifend wiederverwendet werden kann.
Das Forschungsteam führte Confucius Code Agent zweimal auf 151 SWE Bench Professional-Instanzen mit Claude 4.5 Sonnet aus. Beim ersten Durchlauf löst der Agent Aufgaben von Grund auf und erstellt Notizen. Beim zweiten Durchlauf liest der Agent diese Notizen. In dieser Einstellung sinken die durchschnittlichen Runden von 64 auf 61, die Token-Nutzung sinkt von etwa 104.000 auf 93.000 und Resolve@1 verbessert sich von 53,0 auf 54,4. Dies zeigt, dass Notizen nicht nur Protokolle sind, sondern als effektiver sitzungsübergreifender Speicher fungieren.
Modulare Erweiterungen und ausgefeilte Werkzeugnutzung
Das Confucius SDK stellt Instruments als Erweiterungen bereit, zum Beispiel Dateibearbeitung, Befehlsausführung, Testläufer und Codesuche. Jede Erweiterung kann ihren eigenen Standing beibehalten und die Verkabelung steuern.
Das Forschungsteam untersucht die Auswirkungen einer ausgefeilten Werkzeugnutzung anhand einer Ablation an einer 100-Beispiel-Teilmenge von SWE Bench Professional. Mit Claude 4 Sonnet erhöht der Wechsel von einer Konfiguration ohne erweiterte Kontextfunktionen zu einer mit erweitertem Kontext Resolve@1 von 42,0 auf 48,6. Mit Claude 4.5 Sonnet erreicht eine einfache Werkzeugnutzungskonfiguration 44,0, während eine umfangreichere Werkzeughandhabung 51,6 erreicht, mit 51,0 für eine Zwischenvariante. Diese Zahlen zeigen, dass die Artwork und Weise, wie der Agent die Instruments auswählt und sequenziert, quick genauso wichtig ist wie die Wahl des Spine-Modells.
Metaagent für automatisches Agentendesign
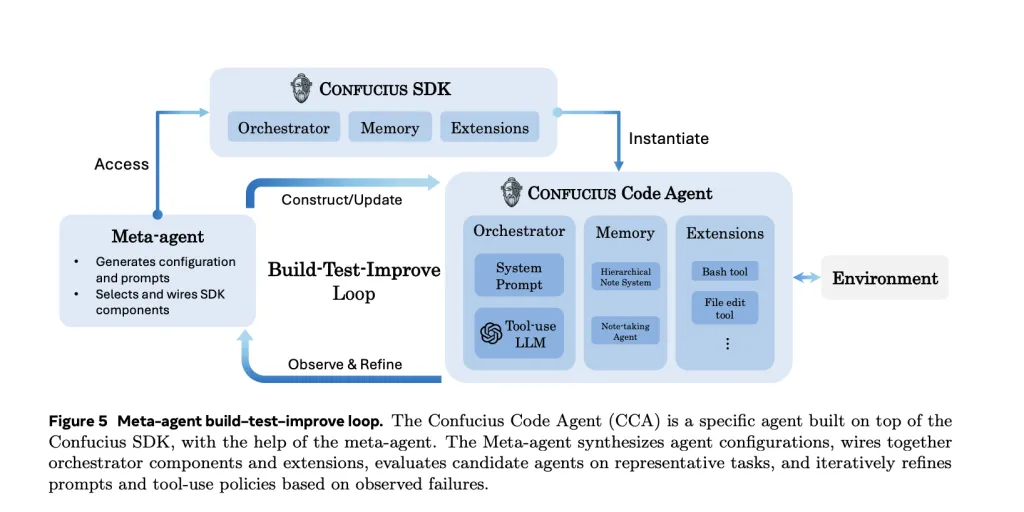
Zusätzlich zu diesen Mechanismen enthält das Confucius SDK einen Meta-Agenten, der eine natürliche Sprachspezifikation eines Agenten übernimmt und iterativ Konfigurationen, Eingabeaufforderungen und Erweiterungssätze vorschlägt. Anschließend führt es den Kandidatenagenten für Aufgaben aus, prüft Ablaufverfolgungen und Metriken und bearbeitet die Konfiguration in einer Schleife zum Erstellen, Testen und Verbessern.
Der Konfuzius-Code-Agent, den das Forschungsteam evaluiert, wird mit Hilfe dieses Meta-Agenten erstellt und nicht nur von Hand abgestimmt. Dieser Ansatz verwandelt einen Teil des Agent-Engineering-Prozesses selbst in ein LLM-gesteuertes Optimierungsproblem.
Ergebnisse zu SWE Bench Professional und SWE Bench Verified
Die Hauptbewertung verwendet SWE Bench Professional, das 731 GitHub-Probleme aufweist, die eine Änderung realer Repositorys erfordern, bis die Assessments erfolgreich sind. Alle verglichenen Systeme nutzen die gleichen Repositories, die gleiche Instrument-Umgebung und die gleichen Evaluierungssysteme, sodass Unterschiede auf die Gerüste und Modelle zurückzuführen sind.
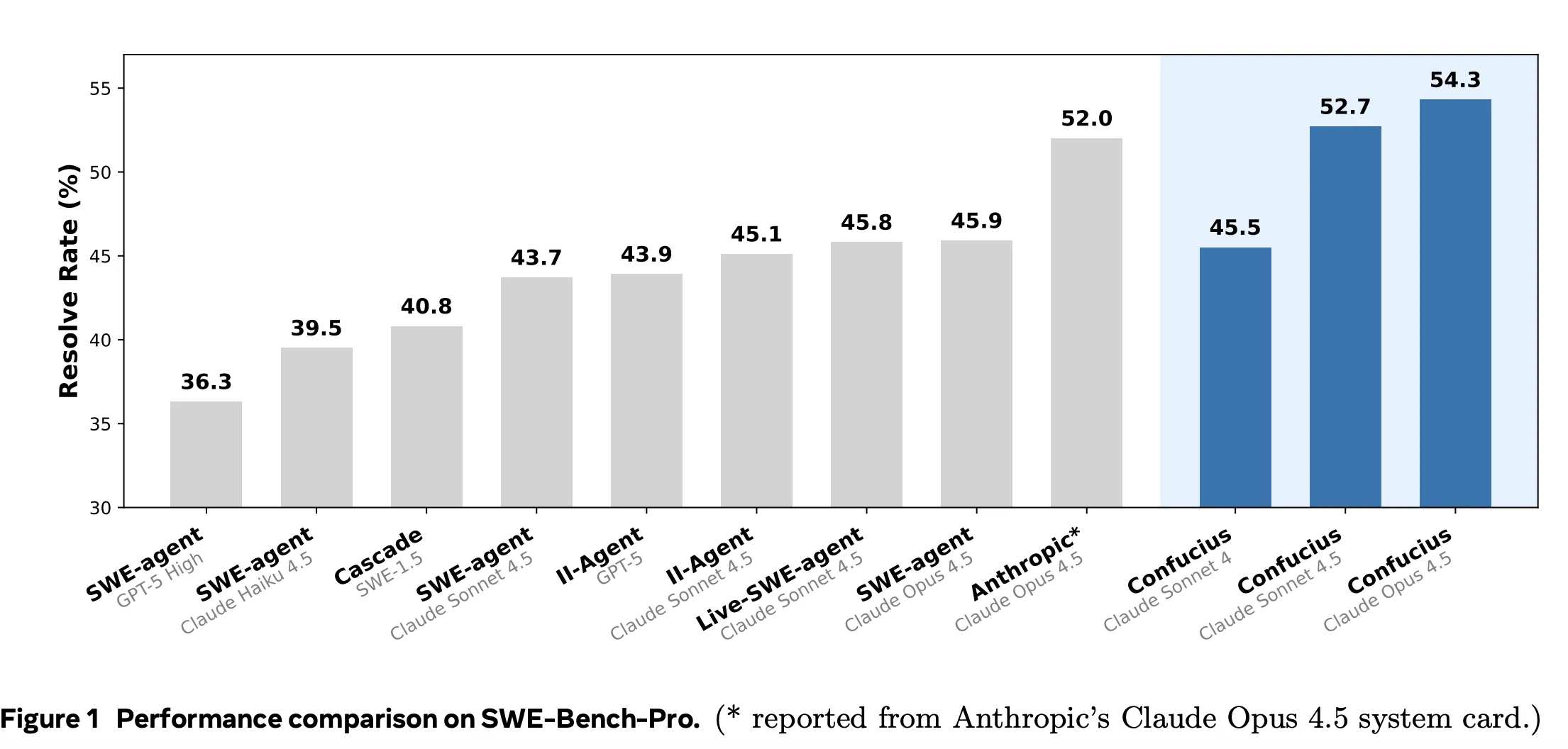
Auf SWE Bench Professional lauten die gemeldeten Resolve@1-Ergebnisse
- Claude 4 Sonett mit SWE Agent, 42.7
- Claude 4 Sonett mit Konfuzius Code Agent, 45,5
- Claude 4.5 Sonett mit SWE Agent, 43.6
- Claude 4.5 Sonett mit Stay SWE Agent, 45.8
- Claude 4,5 Sonett mit Konfuzius-Code-Agent, 52,7
- Claude 4,5 Opus mit Anthropic-Systemkartengerüst, 52,0
- Claude 4,5 Opus mit Konfuzius-Code-Agent, 54,3
Diese Ergebnisse zeigen, dass ein starkes Gerüst mit einem Mittelklassemodell, Claude 4.5 Sonnet mit Confucius Code Agent bei 52,7, ein stärkeres Modell mit einem schwächeren Gerüst, Claude 4.5 Opus mit 52,0, übertreffen kann.
Auf der SWE Bench Verified erreicht Confucius Code Agent mit Claude 4 Sonnet Resolve@1 74,6, verglichen mit 66,6 für SWE Agent und 72,8 für OpenHands. Eine Mini-SWE-Agent-Variante mit Claude 4.5 Sonnet erreicht 70,6, was ebenfalls unter Confucius Code Agent mit Claude 4 Sonnet liegt.
Das Forschungsteam berichtet auch über die Leistung als Funktion der Anzahl der bearbeiteten Dateien. Für Aufgaben, die 1 bis 2 Dateien bearbeiten, erreicht Confucius Code Agent 57,8 Resolve@1, für 3 bis 4 Dateien erreicht er 49,2, für 5 bis 6 Dateien erreicht er 44,1, für 7 bis 10 Dateien erreicht er 52,6 und für mehr als 10 Dateien erreicht er 44,4. Dies weist auf ein stabiles Verhalten bei Änderungen mehrerer Dateien in großen Codebasen hin.
Wichtige Erkenntnisse
- Das Gerüst kann die Modellgröße überwiegen: Confucius Code Agent zeigt, dass Claude 4.5 Sonnet mit einem starken Gerüst 52,7 Resolve@1 auf SWE-Bench-Professional erreicht und damit Claude 4.5 Opus mit einem schwächeren Gerüst von 52,0 übertrifft.
- Hierarchisches Arbeitsgedächtnis ist für die Codierung über einen langen Zeitraum hinweg unerlässlich: Der Confucius SDK-Orchestrator verwendet hierarchischen Arbeitsspeicher und Kontextkomprimierung, um lange Trajektorien über große Repositorys zu verwalten, anstatt sich auf einen einfachen fortlaufenden Verlauf zu verlassen.
- Persistente Notizen dienen als effektiver sitzungsübergreifender Speicher: Bei 151 SWE-Bench-Professional-Aufgaben mit Claude 4.5 Sonnet reduziert die Wiederverwendung strukturierter Notizen die Runden von 64 auf 61, den Token-Verbrauch von etwa 104.000 auf 93.000 und erhöht Resolve@1 von 53,0 auf 54,4.
- Die Werkzeugkonfiguration hat wesentlichen Einfluss auf die Erfolgsquote: Bei einer SWE-Bench-Professional-Teilmenge mit 100 Aufgaben erhöht der Übergang von der einfachen zur umfassenderen Werkzeughandhabung mit Claude 4.5 Sonnet Resolve@1 von 44,0 auf 51,6, was darauf hinweist, dass erlernte Werkzeugrouting- und Wiederherstellungsstrategien ein wichtiger Leistungshebel und nicht nur ein Implementierungsdetail sind.
- Der Meta-Agent automatisiert das Design und die Optimierung von Agenten: Ein Meta-Agent schlägt iterativ Eingabeaufforderungen, Instrument-Units und Konfigurationen vor, bewertet und bearbeitet sie dann in einer Schleife zum Erstellen, Testen und Verbessern, und der Konfuzius-Code-Agent für die Produktion wird mit diesem Prozess selbst generiert und nicht nur mit manueller Optimierung.
Schauen Sie sich das an PAPIER HIER. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Schauen Sie sich unsere neueste Model von anai2025.deveine auf das Jahr 2025 ausgerichtete Analyseplattform, die Modelleinführungen, Benchmarks und Ökosystemaktivitäten in einen strukturierten Datensatz umwandelt, den Sie filtern, vergleichen und exportieren können.
Der Beitrag Meta- und Harvard-Forscher stellen den Confucius Code Agent (CCA) vor: einen Software program-Engineering-Agenten, der mit großen Codebasen arbeiten kann erschien zuerst auf MarkTechPost.