Ich habe das Konzept des föderierten Lernens (FL) durch a Comedian von Google im Jahr 2019. Es struggle ein brillanter Artikel und hat hervorragend erklärt, wie Produkte verbessert werden können, ohne Benutzerdaten in die Cloud zu senden. In letzter Zeit wollte ich die technische Seite dieses Bereichs genauer verstehen. Trainingsdaten sind zu einem so wichtigen Intestine geworden, da sie für die Erstellung guter Modelle unerlässlich sind. Viele davon bleiben jedoch ungenutzt, weil sie fragmentiert, unstrukturiert oder in Silos eingeschlossen sind.
Als ich anfing, dieses Gebiet zu erkunden, fand ich das Blumenrahmenum die unkomplizierteste und anfängerfreundlichste Artwork zu sein, in FL durchzustarten. Es ist Open Supply, die Dokumentation ist klar und die Group ist sehr aktiv und hilfsbereit. Dies ist einer der Gründe für mein erneutes Interesse an diesem Bereich.
Dieser Artikel ist der erste Teil einer Reihe, in der ich mich eingehender mit föderiertem Lernen befasse. Dabei gehe ich darauf ein, was es ist, wie es implementiert wird, welche offenen Probleme es mit sich bringt und warum es in datenschutzrelevanten Umgebungen wichtig ist. In den nächsten Teilen werde ich tiefer auf die praktische Umsetzung mit dem eingehen Blume diskutieren Sie den Datenschutz beim föderierten Lernen und untersuchen Sie, wie sich diese Ideen auf fortgeschrittenere Anwendungsfälle übertragen lassen.
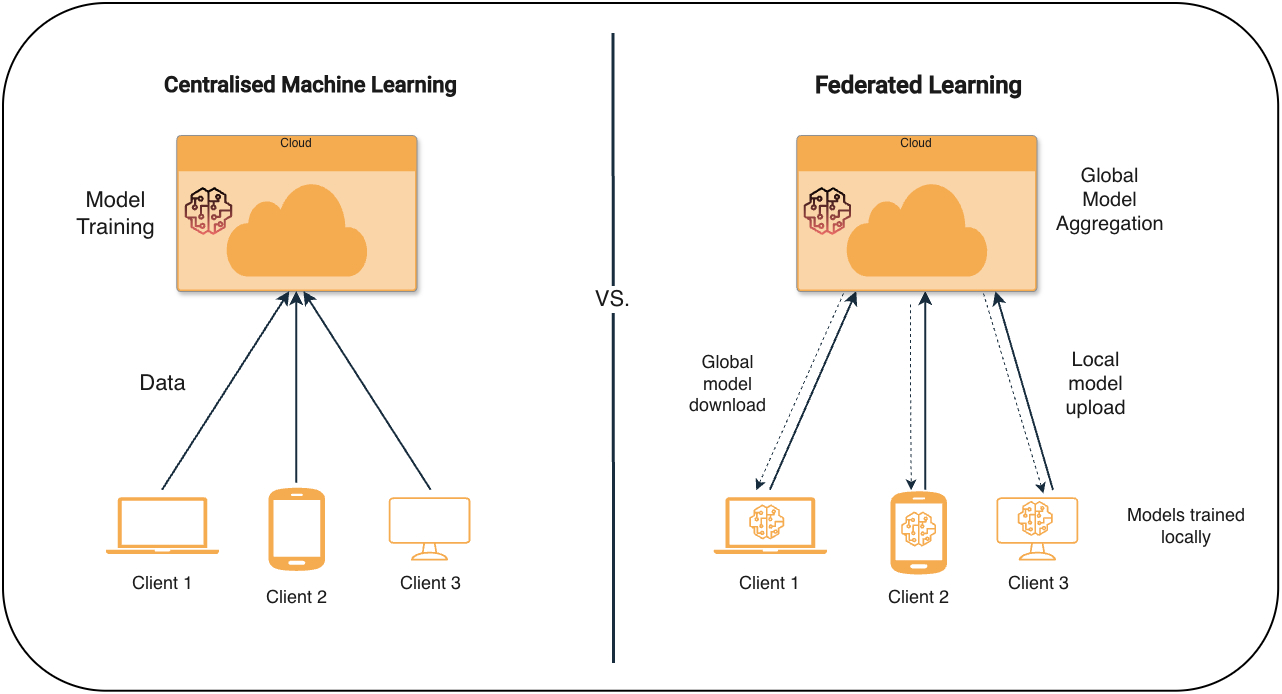
Wenn zentralisiertes maschinelles Lernen nicht superb ist
Wir wissen, dass KI-Modelle auf großen Datenmengen basieren, doch viele der nützlichsten Daten sind sensibel, verteilt und schwer zugänglich. Denken Sie an Daten in Krankenhäusern, Telefonen, Autos, Sensoren und anderen Edge-Systemen. Datenschutzbedenken, lokale Regeln, begrenzter Speicher und Netzwerkbeschränkungen machen die Übertragung dieser Daten an einen zentralen Ort sehr schwierig oder sogar unmöglich. Dadurch bleiben große Mengen wertvoller Daten ungenutzt. Im Gesundheitswesen ist dieses Downside besonders sichtbar. Krankenhäuser erzeugen jedes Jahr Dutzende Petabytes an Daten, Studien gehen jedoch davon aus, dass es bis zu 10 Petabytes an Daten sind 97 % dieser Daten bleiben ungenutzt.
Traditionelles maschinelles Lernen geht davon aus, dass alle Trainingsdaten an einem Ort gesammelt werden können, normalerweise auf einem zentralen Server oder Rechenzentrum. Dies funktioniert, wenn Daten frei verschoben werden können, funktioniert jedoch nicht, wenn die Daten privat oder geschützt sind. In der Praxis hängt ein zentralisiertes Coaching auch von stabiler Konnektivität, ausreichender Bandbreite und geringer Latenz ab, was in verteilten oder Edge-Umgebungen nur schwer zu gewährleisten ist.

In solchen Fällen gibt es zwei häufige Möglichkeiten. Eine Möglichkeit besteht darin, die Daten überhaupt nicht zu nutzen, was bedeutet, dass wertvolle Informationen in Silos eingeschlossen bleiben.
Die andere Möglichkeit besteht darin, jede lokale Entität ein Modell anhand ihrer eigenen Daten trainieren zu lassen und nur das weiterzugeben, was das Modell lernt, während die Rohdaten niemals ihren ursprünglichen Speicherort verlassen. Diese zweite Possibility bildet die Grundlage des föderierten Lernens, das es Modellen ermöglicht, aus verteilten Daten zu lernen, ohne diese zu verschieben. Ein bekanntes Beispiel ist Google Gboard auf Androidwo Funktionen wie die Vorhersage des nächsten Wortes und Intelligentes Verfassen laufen auf Hunderten Millionen Geräten.
Föderiertes Lernen: Das Modell auf die Daten übertragen
Föderiertes Lernen kann als eine kollaborative Einrichtung für maschinelles Lernen betrachtet werden, bei der das Coaching stattfindet, ohne dass Daten an einem zentralen Ort gesammelt werden. Bevor wir uns ansehen, wie es unter der Haube funktioniert, sehen wir uns einige Beispiele aus der Praxis an, die zeigen, warum dieser Ansatz in Umgebungen mit hohem Risiko wichtig ist, die sich über Bereiche vom Gesundheitswesen bis hin zu sicherheitsrelevanten Umgebungen erstrecken.
Gesundheitspflege
Im Gesundheitswesen wird föderiertes Lernen frühzeitig ermöglicht COVID-Screening durch Kuriale KIein System, das in mehreren NHS-Krankenhäusern unter Verwendung routinemäßiger Vitalparameter und Bluttests trainiert wird. Da Patientendaten nicht zwischen Krankenhäusern ausgetauscht werden konnten, wurde die Schulung lokal an jedem Standort durchgeführt und es wurden nur Modellaktualisierungen ausgetauscht. Das resultierende globale Modell ließ sich besser verallgemeinern als Modelle, die in einzelnen Krankenhäusern trainiert wurden, insbesondere wenn es an unbekannten Standorten evaluiert wurde.
Medizinische Bildgebung

Föderiertes Lernen wird auch in der medizinischen Bildgebung untersucht. Forscher am UCL und am Moorfields Eye Hospital nutzen es dazu Feinabstimmung großer Imaginative and prescient Basis-Modelle bei Scans empfindlicher Augen das lässt sich nicht zentralisieren.
Verteidigung
Über das Gesundheitswesen hinaus wird föderiertes Lernen auch in anderen Bereichen eingesetzt sicherheitsrelevante Bereiche wie Verteidigung und Luftfahrt. Dabei werden Modelle auf verteilte physiologische und betriebliche Daten trainiert, die lokal bleiben müssen.
Verschiedene Arten des Federated Studying
Auf einer übergeordneten Ebene kann Federated Studying basierend auf einigen gängigen Typen gruppiert werden wer die Kunden sind Und wie die Daten aufgeteilt werden.
• Geräteübergreifendes vs. siloübergreifendes föderiertes Lernen
Geräteübergreifendes föderiertes Lernen Die Nutzung vieler Purchasers, die bis zu Millionen umfassen können, wie persönliche Geräte oder Telefone, umfasst jeweils eine kleine Menge lokaler Daten und eine unzuverlässige Konnektivität. Zu einem bestimmten Zeitpunkt nimmt jedoch nur ein kleiner Bruchteil der Geräte an einer bestimmten Runde teil. Google Gboard ist ein typisches Beispiel für dieses Setup.
Siloübergreifend föderiertes Lernen, auf der anderen Seite, Beteiligt ist eine viel kleinere Anzahl von Kunden, in der Regel Organisationen wie Krankenhäuser oder Banken. Jeder Consumer verfügt über einen großen Datensatz und verfügt über stabile Rechenleistung und Konnektivität. Die meisten realen Anwendungsfälle in Unternehmen und im Gesundheitswesen sehen aus wie siloübergreifendes, föderiertes Lernen.
• Horizontales vs. vertikales föderiertes Lernen

Horizontales föderiertes Lernen beschreibt, wie Daten auf mehrere Purchasers aufgeteilt werden. In diesem Fall teilen sich alle Purchasers den gleichen Characteristic-Area, aber jeder enthält unterschiedliche Samples. Beispielsweise können mehrere Krankenhäuser dieselben medizinischen Variablen erfassen, jedoch für unterschiedliche Patienten. Dies ist die häufigste Type des föderierten Lernens.
Vertikales föderiertes Lernen wird verwendet, wenn Purchasers denselben Entitätssatz teilen, aber über unterschiedliche Funktionen verfügen. Beispielsweise verfügen möglicherweise ein Krankenhaus und ein Versicherungsanbieter über Daten zu denselben Personen, jedoch mit unterschiedlichen Attributen. Das Coaching erfordert in diesem Fall eine sichere Koordination, da sich die Characteristic-Räume unterscheiden, und dieser Aufbau ist weniger verbreitet als horizontales föderiertes Lernen.
Diese Kategorien schließen sich gegenseitig nicht aus. Ein reales System wird oft mit beiden Achsen beschrieben, zum Beispiel a Siloübergreifendes, horizontales föderiertes Lernen aufstellen.
Wie Federated Studying funktioniert
Federated Studying folgt einem einfachen, wiederholten Prozess, der von einem zentralen Server koordiniert und von mehreren Purchasers ausgeführt wird, die Daten lokal speichern, wie im Diagramm unten dargestellt.

Das Coaching im föderierten Lernen erfolgt durch Wiederholung Verbundlernrunden. In jeder Runde wählt der Server eine kleine zufällige Teilmenge von Purchasers aus, sendet ihnen die aktuellen Modellgewichte und wartet auf Aktualisierungen. Jeder Consumer trainiert das Modell lokal mit stochastischer Gradientenabstiegnormalerweise für mehrere lokale Epochen in eigenen Stapeln, und gibt nur die aktualisierten Gewichte zurück. Auf hoher Ebene folgt es den folgenden fünf Schritten:
- Initialisierung
Auf dem Server wird ein globales Modell erstellt, das als Koordinator fungiert. Das Modell kann zufällig initialisiert werden oder in einem vorab trainierten Zustand beginnen.
2. Modellverteilung
In jeder Runde wählt der Server eine Reihe von Purchasers aus (basierend auf Zufallsstichproben oder einer vordefinierten Strategie), die am Coaching teilnehmen, und sendet ihnen die aktuellen globalen Modellgewichte. Bei diesen Purchasers kann es sich um Telefone, IoT-Geräte oder einzelne Krankenhäuser handeln.
3. Lokale Ausbildung
Jeder ausgewählte Consumer trainiert das Modell dann lokal mit seinen eigenen Daten. Die Daten verlassen nie den Kunden und alle Berechnungen erfolgen auf dem Gerät oder innerhalb einer Organisation wie einem Krankenhaus oder einer Financial institution.
4. Modellaktualisierungskommunikation
Nach dem lokalen Coaching senden Purchasers nur die aktualisierten Modellparameter (z. B. Gewichtungen oder Gradienten) an den Server zurück, während Rohdaten jederzeit geteilt werden.
5. Aggregation
Der Server aggregiert die Consumer-Updates, um ein neues globales Modell zu erstellen. Während Föderierte Mittelwertbildung (Fed Avg) ist ein gängiger Ansatz für die Aggregation, Es werden auch andere Strategien verwendet. Das aktualisierte Modell wird dann an die Purchasers zurückgesendet und der Vorgang wiederholt sich bis zur Konvergenz.
Federated Studying ist ein iterativer Prozess und jeder Durchgang durch diese Schleife wird als Runde bezeichnet. Das Coaching eines föderierten Modells erfordert normalerweise viele Runden, manchmal Hunderte, abhängig von Faktoren wie Modellgröße, Datenverteilung und dem zu lösenden Downside.
Mathematische Instinct hinter Federated Averaging
Der oben beschriebene Workflow kann auch formeller geschrieben werden. Die Abbildung unten zeigt das Unique Föderierte Mittelwertbildung (Fed Avg) Algorithmus von Googles bahnbrechendes Papier. Dieser Algorithmus wurde später zum Hauptbezugspunkt und zeigte, dass föderiertes Lernen in der Praxis funktionieren kann. Diese Formulierung wurde heute tatsächlich zum Bezugspunkt für die meisten föderierten Lernsysteme.

Der ursprüngliche Federated Averaging-Algorithmus, der die Server-Consumer-Trainingsschleife und die gewichtete Aggregation lokaler Modelle zeigt.
Das Herzstück von Federated Averaging ist der Aggregationsschritt, bei dem der Server das globale Modell aktualisiert, indem er einen gewichteten Durchschnitt der lokal trainierten Clientmodelle ermittelt. Dies kann wie folgt geschrieben werden:

Diese Gleichung macht deutlich, wie jeder Kunde zum globalen Modell beiträgt. Kunden mit mehr lokalen Daten haben einen größeren Einfluss, während Kunden mit weniger Stichproben proportional weniger beitragen. In der Praxis ist diese einfache Idee der Grund, warum Fed Avg zur Standardbasis für föderiertes Lernen wurde.
Eine einfache NumPy-Implementierung
Schauen wir uns ein Minimalbeispiel an, bei dem fünf Kunden ausgewählt wurden. Der Einfachheit halber gehen wir davon aus, dass jeder Kunde das lokale Coaching bereits abgeschlossen hat und seine aktualisierten Modellgewichte zusammen mit der Anzahl der verwendeten Proben zurückgegeben hat. Anhand dieser Werte berechnet der Server eine gewichtete Summe, die das neue globale Modell für die nächste Runde erzeugt. Dies spiegelt direkt die Fed-Durchschnittsgleichung wider, ohne dass Schulungen oder kundenseitige Particulars eingeführt werden müssen.
import numpy as np
# Consumer fashions after native coaching (w_{t+1}^ok)
client_weights = (
np.array((1.0, 0.8, 0.5)), # consumer 1
np.array((1.2, 0.9, 0.6)), # consumer 2
np.array((0.9, 0.7, 0.4)), # consumer 3
np.array((1.1, 0.85, 0.55)), # consumer 4
np.array((1.3, 1.0, 0.65)) # consumer 5
)
# Variety of samples at every consumer (n_k)
client_sizes = (50, 150, 100, 300, 4000)
# m_t = whole variety of samples throughout chosen shoppers S_t
m_t = sum(client_sizes) # 50+150+100+300+400
# Initialize international mannequin w_{t+1}
w_t_plus_1 = np.zeros_like(client_weights(0))
# FedAvg aggregation:
# w_{t+1} = sum_{ok in S_t} (n_k / m_t) * w_{t+1}^ok
# (50/1000) * w_1 + (150/1000) * w_2 + ...
for w_k, n_k in zip(client_weights, client_sizes):
w_t_plus_1 += (n_k / m_t) * w_k
print("Aggregated international mannequin w_{t+1}:", w_t_plus_1)
-------------------------------------------------------------
Aggregated international mannequin w_{t+1}: (1.27173913 0.97826087 0.63478261)
Wie die Aggregation berechnet wird
Um die Dinge ins rechte Licht zu rücken: Wir können den Aggregationsschritt auf nur zwei Kunden erweitern und sehen, wie die Zahlen übereinstimmen.

Herausforderungen in föderierten Lernumgebungen
Föderiertes Lernen bringt seine eigenen Herausforderungen mit sich. Eines der Hauptprobleme bei der Implementierung besteht darin, dass die Daten zwischen den Purchasers häufig nicht-IID (nicht unabhängig und identisch verteilt) sind. Dies bedeutet, dass verschiedene Purchasers möglicherweise sehr unterschiedliche Datenverteilungen sehen, was wiederum das Coaching verlangsamen und das globale Modell instabiler machen kann. Beispielsweise können Krankenhäuser in einer Föderation unterschiedliche Bevölkerungsgruppen versorgen, die unterschiedlichen Mustern folgen können.
Föderierte Systeme können alles umfassen, von einigen wenigen Organisationen bis hin zu Millionen von Geräten, und die Verwaltung von Beteiligung, Abbrüchen und Aggregation wird mit zunehmender Systemgröße schwieriger.
Während föderiertes Lernen die Rohdaten lokal hält, löst es keine vollständige Lösung Privatsphäre von allein. Bei Modellaktualisierungen können immer noch personal Informationen verloren gehen, wenn sie nicht geschützt sind. Daher sind häufig zusätzliche Datenschutzmethoden erforderlich. Endlich, Kommunikation kann eine Quelle von Engpässen sein. Da Netzwerke langsam oder unzuverlässig sein können und das Senden häufiger Updates kostspielig sein kann.
Fazit und wie es weitergeht
In diesem Artikel haben wir verstanden, wie föderiertes Lernen auf hohem Niveau funktioniert, und sind auch eine einfache Numpy-Implementierung durchgegangen. Anstatt jedoch die Kernlogik von Hand zu schreiben, gibt es Frameworks wie Flower, die eine einfache und versatile Möglichkeit zum Aufbau föderierter Lernsysteme bieten. Im nächsten Teil nutzen wir Flower, um die schwere Arbeit für uns zu erledigen, damit wir uns auf das Modell und die Daten konzentrieren können und nicht auf die Mechanismen des föderierten Lernens. Wir werden auch einen Blick darauf werfen föderierte LLMswo Modellgröße, Kommunikationskosten und Datenschutzbeschränkungen noch wichtiger werden.
Hinweis: Alle Bilder wurden, sofern nicht anders angegeben, vom Autor erstellt.