
Wenn Sie über die jüngsten Entwicklungen bei KI und LLMs auf dem Laufenden sind, haben Sie wahrscheinlich erkannt, dass ein Großteil des Fortschritts immer noch auf die Erstellung größerer Modelle oder eine bessere Berechnungsweiterleitung zurückzuführen ist. Was wäre, wenn es noch eine different Route gäbe? Da kam Engram! Eine revolutionäre Methode der DeepSeek-KI, die unsere Sicht auf die Skalierung von Sprachmodellen verändert.
Welches Downside löst Engram?
Stellen Sie sich ein Szenario vor: Sie geben „Alexander der Große“ in ein Sprachmodell ein. Jetzt werden wertvolle Rechenressourcen aufgewendet, um diesen gebräuchlichen Ausdruck von Grund auf zu rekonstruieren. jedes Mal. Es ist, als hätte man einen brillanten Mathematiker, der alle 10 Ziffern nachzählen muss, bevor er eine komplexe Gleichung löst.
Aktuelle Transformatormodelle verfügen nicht über eine spezielle Möglichkeit, gängige Muster einfach „nachzuschlagen“. Sie simulieren den Speicherabruf durch Berechnung ineffizient. Engram stellt vor, was Forscher nennen bedingtes Gedächtnis, eine Ergänzung zur bedingten Berechnung, die wir in sehen Combination-of-Consultants (MoE) Modelle.
Die Ergebnisse sprechen für sich. In Benchmark-Assessments zeigte Engram-27B bemerkenswerte Verbesserungen gegenüber vergleichbaren MoE-Modellen:
- 5,0-Punkte-Gewinn bei BBH-Argumentationsaufgaben
- 3,4-Punkte-Verbesserung bei MMLU-Wissenstests
- 3,0-Punkte-Enhance bei der HumanEval-Codegenerierung
- 97,0 vs. 84,2 Genauigkeit bei Nadel-im-Heuhaufen-Assessments mit mehreren Abfragen
Hauptmerkmale von Engram:
Die Hauptmerkmale von Engram sind:
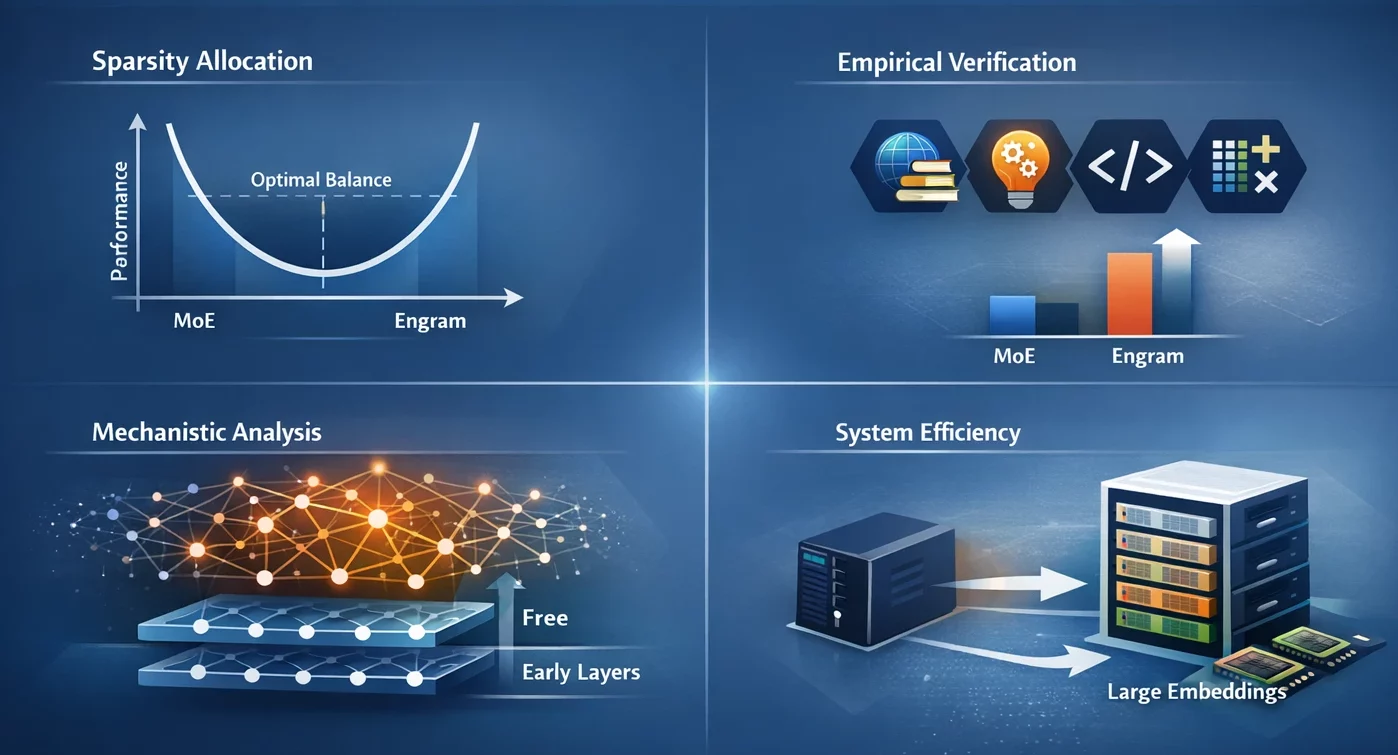
- Sparsity-Zuteilung: Wir haben ein U-förmiges Skalierungsgesetz identifiziert, das die optimale Kapazitätszuweisung steuert und den Kompromiss zwischen neuronaler Berechnung (MoE) und statischem Gedächtnis (Engram) als Dilemma darstellt.
- Empirische Überprüfung: Das Engram-27B-Modell bietet einen konsistenten Gewinn gegenüber MoE-Basislinien in den Bereichen Wissen, Argumentation, Code und Mathematik unter Bedingungen strenger Isoparameter- und Iso-FLOPs-Einschränkungen.
- Mechanistische Analyse: Die Ergebnisse unserer Analyse deuten darauf hin, dass Engram es ermöglicht, dass die frühen Schichten frei von statischen Musterrekonstruktionen sind, was dazu führen könnte, dass die effektive Tiefe für komplexe Überlegungen erhalten bleibt.
- Systemeffizienz: Das Modul verwendet deterministische Adressierung, die es ermöglicht, sehr große Einbettungstabellen mit nur geringfügiger Verlängerung der Inferenzzeit in den Hostspeicher zu verschieben.
Wie funktioniert Engram eigentlich?
Bei Sprachmodellen, die leicht auf häufige Muster zugreifen können, wurde Engram mit einer Hochgeschwindigkeits-Nachschlagetabelle verglichen.
Die Kernarchitektur
Der Ansatz von Engram basiert auf einer sehr einfachen, aber auch sehr wirkungsvollen Idee: Er basiert auf N-Gramm-Einbettungen (Sequenzen von N aufeinanderfolgenden Token), in denen nachgeschlagen werden kann konstante Zeit O(1). Anstatt jede mögliche Wortkombination zu speichern, verwendet es Hash-Funktionen, um Muster auf effiziente Weise Einbettungen zuzuordnen.
Diese Architektur besteht aus drei Hauptteilen:
- Tokenizer-Komprimierung: Bevor Engram nach Mustern sucht, standardisiert es Token, sodass sich „Apfel“ und „Apfel“ auf dasselbe Konzept beziehen. Dies führt zu einer Reduzierung der effektiven Wortschatzgröße um 23 %, was zu einer höheren Effizienz des Techniques führt.
- Multi-Head-Hashing: Um Kollisionen zu verhindern (d. h. die Zuordnung verschiedener Muster zum gleichen Ort), verwendet Engram mehrere Hash-Funktionen. Stellen Sie sich zum Beispiel vor, dass Sie mehrere verschiedene Telefonbücher haben – wenn Ihnen eines die falsche Nummer gibt, werden die anderen hinter Ihnen stehen.
- Kontextbewusstes Gating: Das ist der intelligente Teil. Nicht jede abgerufene Erinnerung ist related, daher verwendet Engram aufmerksamkeitsähnliche Mechanismen, um zu bestimmen, wie sehr jeder Suche im aktuellen Kontext vertraut werden soll. Wenn ein Muster fehl am Platz ist, sinkt der Gate-Wert in Richtung Null und das Muster wird praktisch ignoriert.
Die Entdeckung des Skalierungsgesetzes
Unter den zahlreichen interessanten Entdeckungen sticht das U-förmige Skalierungsgesetz hervor. Forscher konnten die optimale Leistung ermitteln, wenn etwa 75–80 % der Kapazität dem MoE und nur 20–25 % dem Engram-Speicher zugewiesen wurden.
Volles MoE (100 %) bedeutet, dass kein dedizierter Speicher für das Modell vorhanden ist und daher keine ordnungsgemäße Verwendung der Berechnungen zur Rekonstruktion der gemeinsamen Muster erfolgt. Kein MoE (0 %) bedeutet, dass das Modell aufgrund der sehr geringen Rechenkapazität keine anspruchsvollen Überlegungen anstellen konnte. Der perfekte Punkt ist, wo beide im Gleichgewicht sind.
Erste Schritte mit Engram
- Installieren Python mit Model 3.8 und höher.
- Installieren
numpymit dem folgenden Befehl:
pip set up numpy Praktisch: N-Gramm-Hashing verstehen
Schauen wir uns an, wie der Kern-Hashing-Mechanismus von Engram anhand einer praktischen Aufgabe funktioniert.
Implementierung der grundlegenden N-Gramm-Hash-Suche
In dieser Aufgabe werden wir sehen, wie Engram deterministisches Hashing verwendet, um Token-Sequenzen Einbettungen zuzuordnen, wodurch die Notwendigkeit, jedes mögliche N-Gramm separat zu speichern, vollständig vermieden wird.
1: Einrichten der Umgebung
import numpy as np
from typing import Record
# Configuration
MAX_NGRAM = 3
VOCAB_SIZE = 1000
NUM_HEADS = 4
EMBEDDING_DIM = 128 2: Erstellen Sie einen einfachen Tokenizer-Komprimierungssimulator
def compress_token(token_id: int) -> int:
# Simulate normalization by mapping comparable tokens
# In actual Engram, this makes use of NFKC normalization
return token_id % (VOCAB_SIZE // 2)
def compress_sequence(token_ids: Record(int)) -> np.ndarray:
return np.array((compress_token(tid) for tid in token_ids))3: Implementieren Sie die Hash-Funktion
def hash_ngram(tokens: Record(int),
ngram_size: int,
head_idx: int,
table_size: int) -> int:
# Multiplicative-XOR hash as utilized in Engram
multipliers = (2 * i + 1 for i in vary(ngram_size))
combine = 0
for i, token in enumerate(tokens(-ngram_size:)):
combine ^= token * multipliers(i)
# Add head-specific variation
combine ^= head_idx * 10007
return combine % table_size
# Check it
sample_tokens = (42, 108, 256, 512)
compressed = compress_sequence(sample_tokens)
hash_value = hash_ngram(
compressed.tolist(),
ngram_size=2,
head_idx=0,
table_size=5003
)
print(f"Hash worth for 2-gram: {hash_value}")4: Erstellen Sie eine Multi-Head-Einbettungssuche
def multi_head_lookup(token_sequence: Record(int),
embedding_tables: Record(np.ndarray)) -> np.ndarray:
compressed = compress_sequence(token_sequence)
embeddings = ()
for ngram_size in vary(2, MAX_NGRAM + 1):
for head_idx in vary(NUM_HEADS):
desk = embedding_tables(ngram_size - 2)(head_idx)
table_size = desk.form(0)
hash_idx = hash_ngram(
compressed.tolist(),
ngram_size,
head_idx,
table_size
)
embeddings.append(desk(hash_idx))
return np.concatenate(embeddings)
# Initialize random embedding tables
tables = (
(
np.random.randn(5003, EMBEDDING_DIM // NUM_HEADS)
for _ in vary(NUM_HEADS)
)
for _ in vary(MAX_NGRAM - 1)
)
consequence = multi_head_lookup((42, 108, 256), tables)
print(f"Retrieved embedding form: {consequence.form}")Ausgabe:

Verstehen Sie Ihre Ergebnisse:
Hashwert 292: Ihr 2-Gramm-Muster befindet sich an diesem Index in der Einbettungstabelle. Der Wert ändert sich zusammen mit Ihren Eingabetokens und zeigt somit die deterministische Zuordnung an.
Kind (256,): Insgesamt wurden 8 Einbettungen abgerufen (2 N-Gramm-Größen × jeweils 4 Köpfe), wobei jede Einbettung eine Dimension von 32 hat (EMBEDDING_DIM=128 / NUM_HEADS=4). Verkettet: 8 × 32 = 256 Dimensionen.
Notiz: Sie können auch die Implementierung von Engram über die Kernlogik von sehen Engram-Modul.
Reale Leistungssteigerungen
Die Tatsache, dass Engram bei Wissensaufgaben helfen kann, ist ein großer Pluspunkt, aber es macht das Denken und die Codegenerierung trotzdem deutlich besser.
Engram verlagert die lokale Mustererkennung auf die Suche im Gedächtnis und ermöglicht so den Aufmerksamkeitsmechanismen, auch im globalen Kontext zu arbeiten. Die Leistungsverbesserung ist in diesem Fall sehr bedeutend. Beim RULER-Benchmark-Check mit 32.000 Kontextfenstern konnte Engram Folgendes erreichen:
- NIAH für mehrere Abfragen: 97,0 (vs. 84,2 Basiswert)
- Variablenverfolgung: 89,0 (vs. 77,0 Basislinie)
- Extraktion gebräuchlicher Wörter: 99,6 (vs. 73,0 Basiswert)
Abschluss
Engram offenbart sehr interessante Forschungspfade. Ist es möglich, die festen Funktionen durch erlerntes Hashing zu ersetzen? Was ist, wenn der Speicher dynamisch ist und während der Inferenz in Echtzeit aktualisiert wird? Wie wird die Reaktion im Hinblick auf die Verarbeitung größerer Zusammenhänge sein?
Das Engram-Repository von DeepSeek-AI verfügt über die vollständigen technischen Particulars und den Code, und die Methode wird bereits in realen Systemen übernommen. Die wichtigste Erkenntnis ist, dass es bei der KI-Entwicklung nicht nur um größere Modelle oder besseres Routing geht. Manchmal geht es um die Suche nach geeigneten Werkzeugen für die Modelle und manchmal handelt es sich bei diesem bestimmten Werkzeug einfach um ein sehr effizientes Speichersystem.
Häufig gestellte Fragen
A. Engram ist ein Speichermodul für Sprachmodelle, das es ihnen ermöglicht, gängige Tokenmuster direkt nachzuschlagen, anstatt sie jedes Mal neu zu berechnen. Stellen Sie sich vor, dass Sie einem LLM neben seiner Denkfähigkeit auch ein schnelles, zuverlässiges Gedächtnis verleihen.
A. Herkömmliche Transformatoren simulieren den Speicher durch Berechnung. Selbst für sehr häufige Phrasen berechnet das Modell Muster wiederholt neu. Engram beseitigt diese Ineffizienz durch die Einführung eines bedingten Gedächtnisses, wodurch Berechnungen für das Denken statt für das Erinnern frei werden.
A. MoE konzentriert sich auf die selektive Routing-Berechnung. Engram ergänzt dies, indem es den Speicher selektiv weiterleitet. Das MoE entscheidet, welche Experten denken sollen. Engram entscheidet, welche Muster sofort gespeichert und abgerufen werden sollen.
Information Science Trainee bei Analytics Vidhya
Derzeit arbeite ich als Information Science Trainee bei Analytics Vidhya, wo ich mich auf die Entwicklung datengesteuerter Lösungen und die Anwendung von KI/ML-Techniken zur Lösung realer Geschäftsprobleme konzentriere. Meine Arbeit ermöglicht es mir, fortschrittliche Analysen, maschinelles Lernen und KI-Anwendungen zu erforschen, die es Unternehmen ermöglichen, intelligentere, evidenzbasierte Entscheidungen zu treffen.
Mit einem starken Fundament in den Bereichen Informatik, Softwareentwicklung und Datenanalyse ist es mir eine Leidenschaft, KI zu nutzen, um wirkungsvolle, skalierbare Lösungen zu schaffen, die die Lücke zwischen Technologie und Geschäft schließen.
📩 Du kannst mich auch erreichen unter (e mail protected)
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.