
Durch die Nutzung von KI-gesteuertem NLP zur Extraktion strukturierter Daten aus riesigen, unstrukturierten EHRs erhalten Forscher Zugang zu umfangreichen klinischen Datensätzen für epidemiologische Studien, die Gesundheit der Bevölkerung und die Entdeckung medizinischer Erkenntnisse, die sonst verborgen bleiben würden.
Extrahieren von Particulars aus unstrukturierten EHR-Daten 101: Ein Beispielworkflow
Der Prozess der Gewinnung von Erkenntnissen aus unstrukturierten EHR-Daten ist systematisch und muss von Fall zu Fall durchgeführt werden. Die Domänenanforderungen, die gesundheitsorganisationspezifischen Bedenken und Herausforderungen, die zweckorientierten Anwendungen und die damit verbundenen Auswirkungen sind subjektiv, und genau aus diesem Grund sollte der Prozess auch solche Faktoren berücksichtigen, die Ihr Unternehmen und seine Imaginative and prescient beeinflussen.
Da es jedoch für jeden Ansatz einen bestimmten Arbeitsablauf oder eine Faustregel gibt, haben wir auch eine Einführung für Sie zusammengestellt, auf die Sie sich beziehen können.
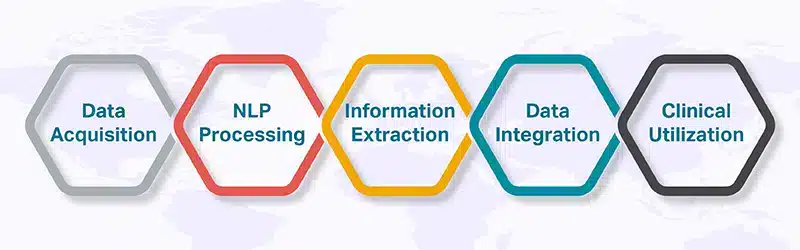
-
Datenerfassung und -vorverarbeitung: Der erste Schritt besteht darin, EHR-Daten mit klinischen Notizen, Medikamentenlisten, Allergielisten und Verfahrensberichten zusammenzustellen. Die Vorverarbeitung im KI-Modus umfasst Deidentifizierung, Bereinigung, Normalisierung und Tokenisierung, um Daten in konsistenten Formaten (Textformate, strukturiert vs. unstrukturiert) vorzubereiten.
-
NLP-Verarbeitung / KI-Modelltraining: Die zusammengestellten Daten werden dann in Ihre NLP-Algorithmen oder KI-Modelle eingespeist, um die Textdaten zu analysieren und wichtige klinische Einheiten wie Diagnosen, Medikamente, Allergien und Verfahren zu identifizieren. Das Coaching im „KI-Modus“ umfasst überwachtes Lernen, manchmal auch unbeaufsichtigtes oder halbüberwachtes Lernen, unter Verwendung gekennzeichneter Datensätze.
-
Informationsextraktion: Je nachdem, ob Ihr Modell überwachten oder unüberwachten Lernstrategien (oder dem Hybrid-KI-Modus) folgt, extrahiert es relevante Informationen zu jeder Entität, einschließlich Typ, Datum, zugehörige Particulars, Schweregrad, Dosierung usw.
-
Validierung und klinische Aufsicht: Sobald das KI-gestützte Modell Informationen extrahiert, müssen diese von medizinischem Fachpersonal auf klinische Genauigkeit validiert werden. Human-in-the-Loop-Systeme und Experten-Suggestions-Schleifen sorgen für eine zuverlässige Extraktion.
-
Datenintegration und Interoperabilität: Die strukturierten Daten werden dann in das EHR-System oder andere relevante Datenbanken integriert. Gewährleistung der Einhaltung von HL7 FHIR und anderer Gesundheitsstandards sowie Unterstützung der Interoperabilität.
-
Klinische Nutzung und Suggestions-Zyklus: Die Integration ermöglicht es medizinischem Fachpersonal, extrahierte Informationen für klinische Entscheidungsfindung, Forschung und Initiativen im Bereich der öffentlichen Gesundheit zu nutzen. Feedbackschleifen im KI-Modus tragen dazu bei, die Modellgenauigkeit im Laufe der Zeit zu verbessern und sich an neue Datentypen oder Sprachmuster anzupassen.
Herausforderungen bei der Nutzung von NLP zur Extraktion von EHR-Daten
Die Aufgabe, unstrukturierte Daten aus EHRs zu extrahieren, ist ehrgeizig und kann das Leben von Interessengruppen im Gesundheitswesen einfacher machen. Allerdings gibt es Engpässe, die den reibungslosen Umsetzungsprozess behindern könnten. Schauen wir uns die häufigsten Probleme an, damit Sie proaktiv Strategien entwickeln können, um sie anzugehen oder zu mildern.
-
Datenqualität, -vielfalt und -verzerrung: Die Genauigkeit der NLP-Extraktion hängt von der Qualität, Konsistenz und Repräsentativität der EHR-Daten ab. Unterschiedliche Formate, Terminologien, unvollständige Datensätze oder verzerrte Stichproben können die Leistung des KI-Modells beeinträchtigen.
-
Datenschutz, Sicherheit und Compliance im KI-Modus: Es müssen Maßnahmen umgesetzt werden, um die Privatsphäre und Datensicherheit der Patienten während der NLP/KI-gestützten Verarbeitung und Speicherung zu gewährleisten. Regulatorische Richtlinien wie DSGVO, HIPAA usw. müssen eingehalten werden. Dazu gehören Anonymisierung, sichere Speicherung und Zugriffskontrollen.
-
Klinische Validierung und Interpretierbarkeit: Extrahierte Informationen müssen von medizinischem Fachpersonal validiert werden, um ihre Genauigkeit und klinische Relevanz sicherzustellen. Komplexe Terminologien, mehrdeutige Formulierungen oder seltene Bedingungen können Modelle verwirren. Außerdem müssen Systeme im KI-Modus erklärbar sein, damit Ärzte ihnen vertrauen können.
-
Integration, Interoperabilität und Requirements: Die extrahierten Daten müssen nahtlos in bestehende EHR-Systeme und andere IT-Systeme im Gesundheitswesen integriert werden. KI-Modelle sollten HL7, FHIR, SNOMED, RadLex usw. unterstützen, um die Interoperabilität sicherzustellen.
-
Skalierbarkeit und Wartung: Im KI-Modus erfordern Systeme eine kontinuierliche Neuschulung, Überwachung und Versionierung, um neuen klinischen Praktiken, sich entwickelnder medizinischer Terminologie oder Änderungen im Dokumentationsstil Rechnung zu tragen.
-
Kosten- und Ressourcenbedarf: Die Entwicklung, Schulung, Validierung und Bereitstellung KI-gestützter NLP-Systeme erfordert Investitionen in Datenannotation, Expertenaufsicht, Rechenressourcen und qualifiziertes Private.
Letzte Gedanken
Kurz gesagt: Das Potenzial ist bei der Bereitstellung grenzenlos KI-gestütztes NLP um Gesundheitsdaten aus EHRs zu extrahieren. Für eine narrensichere Implementierung empfehlen wir, die Herausforderungen anzugehen, die klinische Aufsicht durchzusetzen und einen verantwortungsvollen Einsatz im „KI-Modus“ sicherzustellen.
Wenn Sie den Weg für eine lückenlose Einhaltung von Gesundheitsdatenvorschriften ebnen und das Beste bekommen möchten KI-Trainingsdaten Für Ihre Modelle können Sie Kontakt zu uns aufnehmen. Da wir ein Branchenpionier sind, verstehen wir das Fachgebiet, Ihre Unternehmensvisionen und die Feinheiten, die mit der Schulung eines im Gesundheitswesen nativen, KI-optimierten klinischen NLP-Modells verbunden sind. Kontaktieren Sie uns noch heute.