NVIDIA-Forscher haben PersonaPlex-7B-v1 veröffentlicht, ein Vollduplex-Speech-to-Speech-Konversationsmodell, das auf natürliche Sprachinteraktionen mit präziser Persona-Steuerung abzielt.
Von ASR→LLM→TTS zu einem einzelnen Vollduplex-Modell
Herkömmliche Sprachassistenten betreiben meist eine Kaskade. Die automatische Spracherkennung (ASR) wandelt Sprache in Textual content um, ein Sprachmodell generiert eine Textantwort und Textual content to Speech (TTS) wandelt sie wieder in Audio um. Jede Stufe erhöht die Latenz und die Pipeline kann überlappende Sprache, natürliche Unterbrechungen oder dichte Rückkanäle nicht verarbeiten.
PersonaPlex ersetzt diesen Stack durch ein einzelnes Transformer-Modell, das Streaming-Sprachverständnis und Sprachgenerierung in einem Netzwerk durchführt. Das Modell arbeitet mit kontinuierlichem Audio, das mit einem neuronalen Codec codiert ist, und sagt sowohl Textual content-Tokens als auch Audio-Tokens autoregressiv voraus. Eingehende Audiodaten des Benutzers werden inkrementell kodiert, während PersonaPlex gleichzeitig seine eigene Sprache generiert, was Einschleusen, Überlappungen, schnelle Abwechslung und kontextbezogene Rückkanäle ermöglicht.
PersonaPlex läuft in einer Twin-Stream-Konfiguration. Ein Stream verfolgt Benutzeraudio, der andere Stream verfolgt die Sprache und den Textual content des Agenten. Beide Streams haben denselben Modellstatus, sodass der Agent beim Sprechen weiter zuhören und seine Reaktion anpassen kann, wenn der Benutzer unterbricht. Dieses Design ist direkt vom Moshi-Vollduplex-Framework von Kyutai inspiriert.
Hybride Eingabeaufforderung, Sprachsteuerung und Rollensteuerung
PersonaPlex verwendet zwei Eingabeaufforderungen, um die Konversationsidentität zu definieren.
- Die Sprachaufforderung ist eine Folge von Audio-Tokens, die Stimmmerkmale, Sprechstil und Prosodie kodiert.
- Die Textaufforderung beschreibt Rolle, Hintergrund, Organisationsinformationen und Szenariokontext.
Zusammen schränken diese Aufforderungen sowohl den sprachlichen Inhalt als auch das akustische Verhalten des Agenten ein. Darüber hinaus unterstützt eine Systemeingabeaufforderung Felder wie Identify, Firmenname, Agentenname und Geschäftsinformationen mit einem Finances von bis zu 200 Token.
Architektur, Helium-Spine und Audiopfad
Das PersonaPlex-Modell verfügt über 7B-Parameter und folgt der Moshi-Netzwerkarchitektur. Ein Mimi-Sprachencoder, der ConvNet- und Transformer-Ebenen kombiniert, wandelt Wellenform-Audio in diskrete Token um. Zeit- und Tiefentransformatoren verarbeiten mehrere Kanäle, die Benutzeraudio, Agententext und Agentenaudio darstellen. Ein Mimi-Sprachdecoder, der auch Transformer- und ConvNet-Schichten kombiniert, generiert die Ausgabe-Audio-Tokens. Audio verwendet eine Abtastrate von 24 kHz sowohl für die Eingabe als auch für die Ausgabe.
PersonaPlex basiert auf Moshi-Gewichten und -Anwendungen Helium als zugrunde liegendes Sprachmodell-Rückgrat. Helium bietet semantisches Verständnis und ermöglicht eine Verallgemeinerung außerhalb der überwachten Gesprächsszenarien. Dies wird am Beispiel des „Weltraumnotfalls“ deutlich, wo eine Aufforderung zu einem Reaktorkernausfall bei einer Marsmission zu einer kohärenten technischen Argumentation mit angemessenem emotionalem Ton führt, obwohl diese Scenario nicht Teil der Trainingsverteilung ist.
Trainingsdatenmischung, echte Gespräche und synthetische Rollen
Das Coaching besteht aus einer Stufe und verwendet eine Mischung aus realen und synthetischen Dialogen.
Echte Konversationen stammen aus 7.303 Anrufen, etwa 1.217 Stunden, im Fisher English-Korpus. Diese Konversationen werden mithilfe von GPT-OSS-120B mit Eingabeaufforderungen kommentiert. Die Eingabeaufforderungen sind auf unterschiedlichen Granularitätsebenen verfasst, von einfachen Personenhinweisen wie „Sie führen gerne ein gutes Gespräch“ bis hin zu längeren Beschreibungen, die Lebensgeschichte, Standort und Vorlieben umfassen. Dieses Korpus bietet natürliche Rückkanäle, Störungen, Pausen und emotionale Muster, die mit TTS allein nur schwer zu erreichen sind.
Synthetische Daten umfassen Assistenten- und Kundendienstrollen. Das NVIDIA-Staff meldet 39.322 synthetische Assistentengespräche, etwa 410 Stunden, und 105.410 synthetische Kundendienstgespräche, etwa 1.840 Stunden. Qwen3-32B und GPT-OSS-120B generieren die Transkripte und Chatterbox TTS wandelt sie in Sprache um. Für Assistenteninteraktionen ist die Textaufforderung auf „Sie sind ein kluger und freundlicher Lehrer“ festgelegt. Beantworten Sie Fragen oder geben Sie Ratschläge auf klare und ansprechende Weise.“ Für Kundendienstszenarien kodieren Eingabeaufforderungen Organisation, Rollentyp, Agentennamen und strukturierte Geschäftsregeln wie Preise, Stunden und Einschränkungen.
Dieses Design ermöglicht es PersonaPlex, natürliches Gesprächsverhalten, das hauptsächlich von Fisher stammt, von Aufgabentreue und Rollenkonditionierung zu trennen, die hauptsächlich von synthetischen Szenarien herrühren.
Auswertung auf FullDuplexBench und ServiceDuplexBench
PersonaPlex wird auf FullDuplexBench, einem Benchmark für Vollduplex-Modelle für gesprochene Dialoge, und auf einer neuen Erweiterung namens ServiceDuplexBench für Kundendienstszenarien evaluiert.
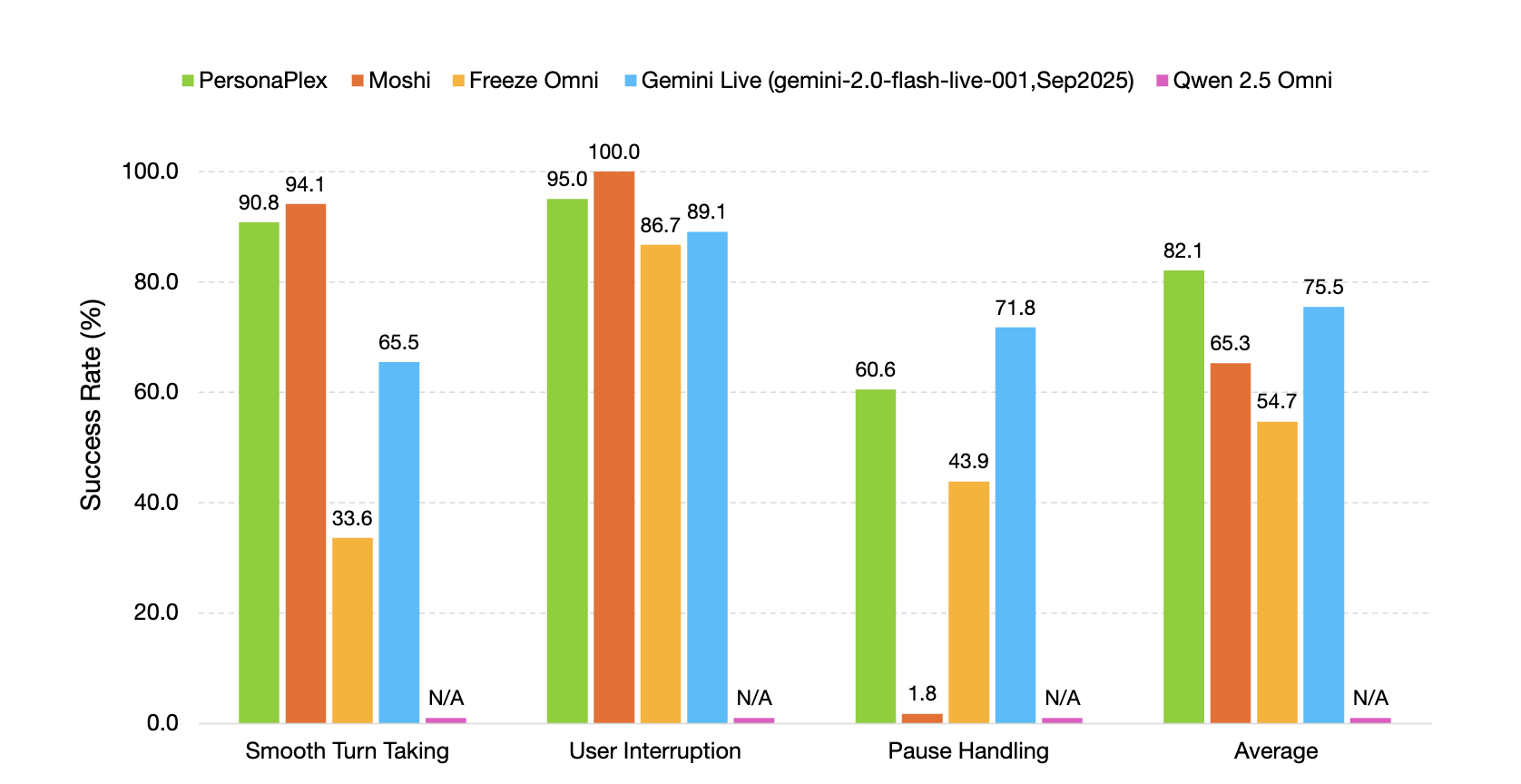
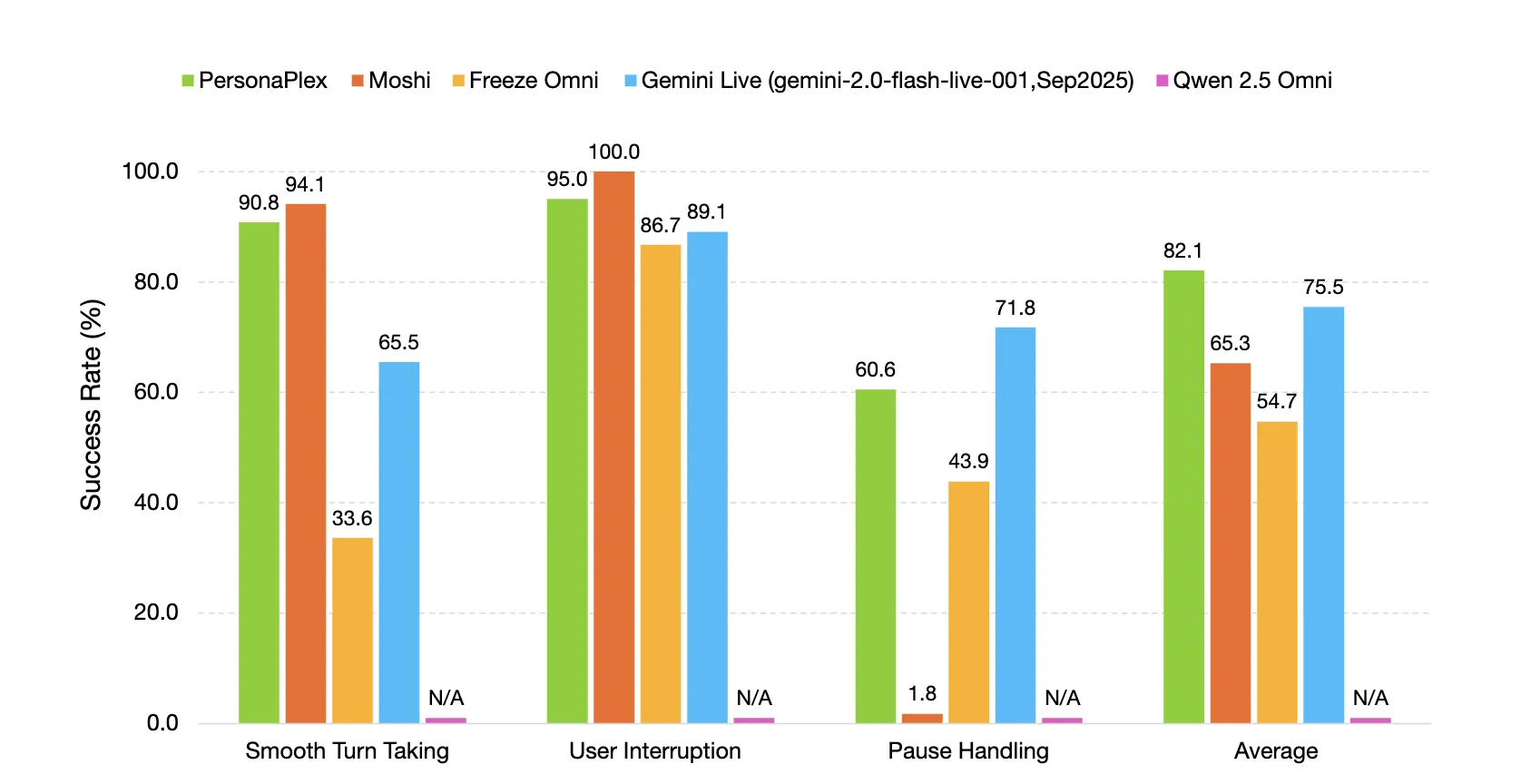
FullDuplexBench misst die Konversationsdynamik mit Übernahmerate und Latenzmetriken für Aufgaben wie reibungsloses Abwechseln, Umgang mit Benutzerunterbrechungen, Umgang mit Pausen und Rückkanalisierung. GPT-4o fungiert als LLM-Richter für die Antwortqualität in Frage-Antwort-Kategorien. PersonaPlex erreicht eine reibungslose Wende mit TOR 0,908 mit einer Latenz von 0,170 Sekunden und Benutzerunterbrechung TOR 0,950 mit einer Latenz von 0,240 Sekunden. Die Sprecherähnlichkeit zwischen Sprachansagen und Ausgaben in der Teilmenge der Benutzerunterbrechungen verwendet WavLM-TDNN-Einbettungen und erreicht 0,650.
PersonaPlex übertrifft viele andere Open-Supply- und geschlossene Systeme in Bezug auf Gesprächsdynamik, Antwortlatenz, Unterbrechungslatenz und Aufgabeneinhaltung sowohl in Assistenten- als auch in Kundendienstrollen.
Wichtige Erkenntnisse
- PersonaPlex-7B-v1 ist ein Vollduplex-Sprach-zu-Sprache-Konversationsmodell mit 7B-Parametern von NVIDIA, das auf der Moshi-Architektur mit einem Helium-Sprachmodell-Spine, Code unter MIT und Gewichtungen unter der NVIDIA Open Mannequin License basiert.
- Das Modell verwendet einen Twin-Stream-Transformer mit Mimi-Sprachkodierer und -Dekodierer bei 24 kHz, kodiert kontinuierliches Audio in diskrete Token und generiert gleichzeitig Textual content- und Audio-Token, was Einschleichen, Überlappungen, schnelles Abbiegen und natürliche Rückkanäle ermöglicht.
- Die Persona-Steuerung erfolgt durch Hybrid-Immediate. Ein Sprach-Immediate aus Audio-Tokens legt Klangfarbe und Stil fest, ein Textual content-Immediate und ein System-Immediate mit bis zu 200 Token definieren Rolle, Geschäftskontext und Einschränkungen, mit vorgefertigten Spracheinbettungen wie NATF- und NATM-Familien.
- Das Coaching verwendet eine Mischung aus 7.303 Fisher-Gesprächen, etwa 1.217 Stunden, kommentiert mit GPT-OSS-120B, plus synthetischen Assistenten- und Kundendienstdialogen, etwa 410 Stunden und 1.840 Stunden, generiert mit Qwen3-32B und GPT-OSS-120B und gerendert mit Chatterbox TTS, das die Natürlichkeit von Gesprächen von der Einhaltung von Aufgaben trennt.
- Auf FullDuplexBench und ServiceDuplexBench erreicht PersonaPlex eine reibungslose Flip-Take-Over-Charge von 0,908 und eine Benutzer-Unterbrechungs-Takeover-Charge von 0,950 mit einer Latenz von weniger als einer Sekunde und verbesserter Aufgabentreue.
Schauen Sie sich das an Technische Particulars, Modellgewichte Und Repo. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Der Beitrag NVIDIA veröffentlicht PersonaPlex-7B-v1: ein Echtzeit-Speech-to-Speech-Modell, das für natürliche und Vollduplex-Gespräche entwickelt wurde erschien zuerst auf MarkTechPost.