
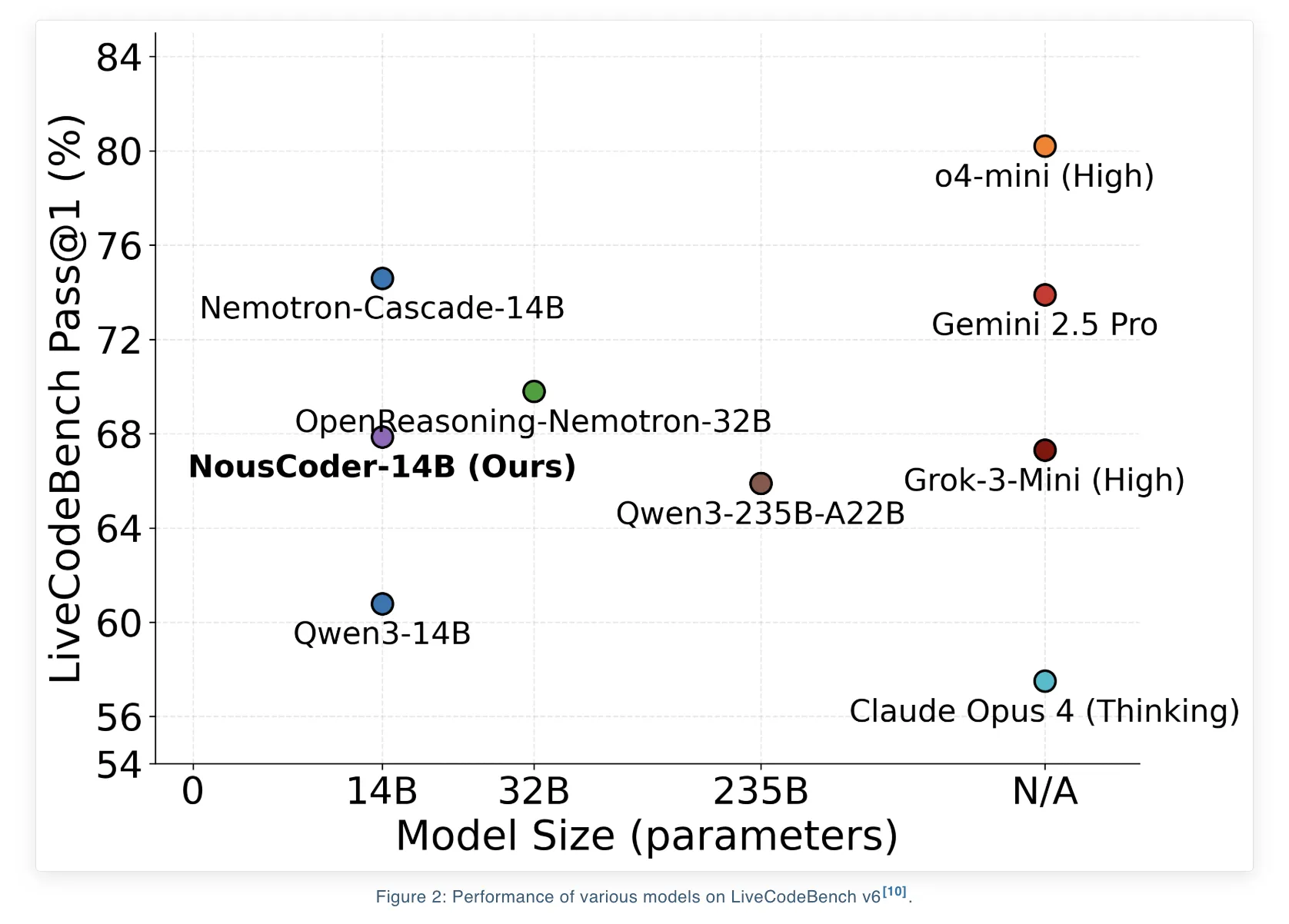
Nous Analysis hat NousCoder-14B eingeführt, ein wettbewerbsorientiertes Olympia-Programmiermodell, das auf Qwen3-14B unter Verwendung von Reinforcement Studying (RL) mit überprüfbaren Belohnungen nachtrainiert wird. Beim LiveCodeBench v6-Benchmark, der Probleme vom 01.08.2024 bis 01.05.2025 abdeckt, erreicht das Modell eine Cross@1-Genauigkeit von 67,87 Prozent. Das sind 7,08 Prozentpunkte mehr als der Qwen3-14B-Basiswert von 60,79 Prozent beim gleichen Benchmark. Das Forschungsteam trainierte das Modell an 24.000 überprüfbaren Codierungsproblemen mit 48 B200-GPUs über 4 Tage und veröffentlichte die Gewichte unter der Apache 2.0-Lizenz auf Hugging Face.
Benchmark-Fokus und was Cross@1 bedeutet
LiveCodeBench v6 ist für die wettbewerbsorientierte Programmierungsbewertung konzipiert. Der hier verwendete Testsplit enthält 454 Probleme. Das Trainingsset verwendet das gleiche Rezept wie das DeepCoder-14B-Projekt von Agentica und Collectively AI. Es kombiniert Probleme von TACO Verified, PrimeIntellect SYNTHETIC 1 und LiveCodeBench-Problemen, die vor dem 31.07.2024 erstellt wurden.
Der Benchmark umfasst nur Aufgaben im kompetitiven Programmierstil. Für jedes Downside muss eine Lösung strenge Zeit- und Speicherbeschränkungen einhalten und eine große Anzahl versteckter Eingabe-Ausgabe-Assessments bestehen. Cross@1 ist der Bruchteil der Probleme, bei denen das erste generierte Programm alle Assessments besteht, einschließlich Zeit- und Speicherbeschränkungen.
Datensatzkonstruktion für ausführungsbasiertes RL
Alle für das Coaching verwendeten Datensätze bestehen aus überprüfbaren Codegenerierungsproblemen. Für jedes Downside gibt es eine Referenzimplementierung und viele Testfälle. Das Trainingsset enthält 24.000 Probleme aus:
- TACO verifiziert
- PrimeIntellect SYNTHETISCH 1
- LiveCodeBench-Probleme, die vor dem 31.07.2024 auftreten
Der Testsatz ist LiveCodeBench v6, der zwischen dem 01.08.2024 und dem 01.05.2025 454 Probleme aufweist.
Jedes Downside ist eine vollständige wettbewerbsfähige Programmieraufgabe mit einer Beschreibung, einem Eingabeformat, einem Ausgabeformat und Testfällen. Dieses Setup ist für RL wichtig, da es ein binäres Belohnungssignal liefert, das nach der Ausführung des Codes kostengünstig zu berechnen ist.
RL-Umgebung mit Atropos und Modal
Die RL-Umgebung wird mit dem Atropos-Framework erstellt. NousCoder-14B wird mithilfe des standardmäßigen LiveCodeBench-Eingabeaufforderungsformats aufgefordert und generiert Python-Code für jedes Downside. Jeder Rollout erhält eine skalare Belohnung, die von den Testfallergebnissen abhängt:
- Belohnung 1, wenn der generierte Code alle Testfälle für dieses Downside besteht
- Belohnung –1, wenn der Code eine falsche Antwort ausgibt, ein Zeitlimit von 15 Sekunden überschreitet oder in einem Testfall ein Speicherlimit von 4 GB überschreitet
Um nicht vertrauenswürdigen Code sicher und im großen Maßstab auszuführen, verwendet das Crew Modal als automatisch skalierte Sandbox. Das System startet professional Rollout einen Modal-Container im Hauptdesign, das das Forschungsteam als verwendete Einstellung beschreibt. Jeder Container führt alle Testfälle für diesen Rollout aus. Dadurch wird vermieden, dass Trainingsberechnungen mit Verifizierungsberechnungen vermischt werden, und die RL-Schleife bleibt stabil.
Das Forschungsteam leitet auch Inferenz und Verifizierung weiter. Wenn ein Inferenzarbeiter eine Generierung abschließt, sendet er den Abschluss an einen Modalprüfer und startet sofort eine neue Generierung. Mit vielen Inferenzarbeitern und einem festen Pool an modalen Containern sorgt dieses Design dafür, dass die Inferenzberechnung der Trainingsschleife und nicht die Verifizierungsgrenze gebunden bleibt.
Das Crew diskutiert drei Verifizierungs-Parallelisierungsstrategien. Sie untersuchen einen Container professional Downside, einen professional Rollout und einen professional Testfall. Sie vermeiden schließlich die Einstellung professional Testfall aufgrund des Mehraufwands beim Containerstart und verwenden einen Ansatz, bei dem jeder Container viele Testfälle auswertet und sich zunächst auf eine kleine Menge der schwierigsten Testfälle konzentriert. Wenn einer dieser Schritte fehlschlägt, kann das System die Überprüfung vorzeitig stoppen.
GRPO-Ziele, DAPO, GSPO und GSPO+
NousCoder-14B verwendet Group Relative Coverage Optimization (GRPO), die kein separates Wertemodell erfordert. Zusätzlich zum GRPO testet das Forschungsteam 3 Ziele: Dynamic sAmpling Coverage Optimization (DAPO), Group Sequence Coverage Optimization (GSPO) und eine modifizierte GSPO-Variante namens GSPO+.
Alle drei Ziele haben die gleiche Definition von Vorteil. Der Vorteil für jeden Rollout ist die Belohnung für diesen Rollout, normalisiert durch den Mittelwert und die Standardabweichung der Belohnungen innerhalb der Gruppe. DAPO wendet Wichtigkeitsgewichtung und Clipping auf Token-Ebene an führt drei wesentliche Änderungen gegenüber GRPO ein:
- Eine Clip-Increased-Regel, die die Exploration nach Token mit geringer Wahrscheinlichkeit erhöht
- Ein Richtliniengradientenverlust auf Token-Ebene, der jedem Token das gleiche Gewicht verleiht
- Dynamisches Sampling, bei dem Gruppen, die alle richtig oder alle falsch sind, verworfen werden, weil sie keinen Vorteil bieten
GSPO verschiebt die Wichtigkeitsgewichtung auf die Sequenzebene. Es definiert ein Sequenzwichtigkeitsverhältnis, das die Token-Verhältnisse über das gesamte Programm hinweg aggregiert. GSPO+ behält die Korrektur auf Sequenzebene bei, skaliert jedoch Farbverläufe neu, sodass Token unabhängig von der Sequenzlänge gleich gewichtet werden.
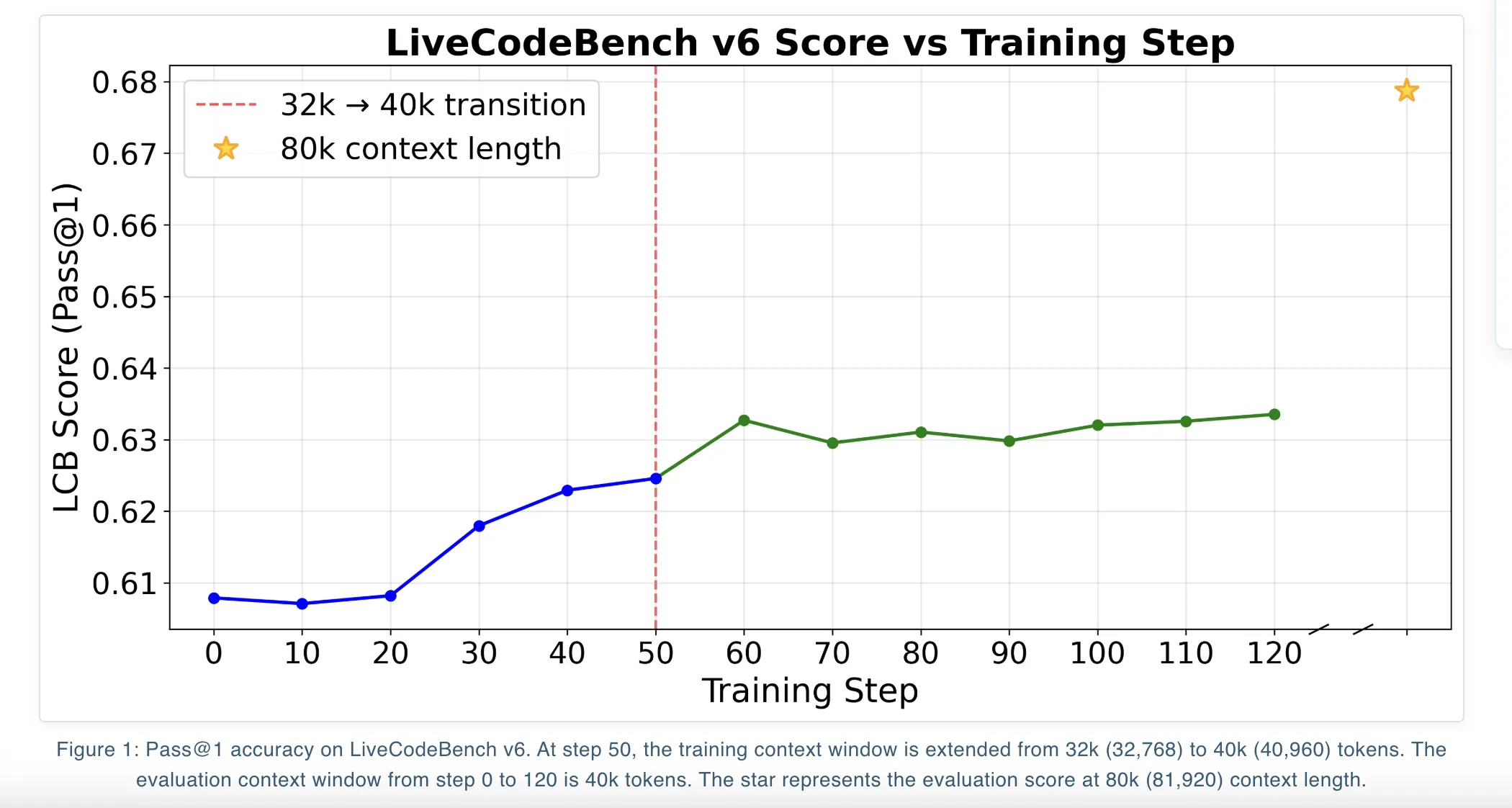
Bei LiveCodeBench v6 sind die Unterschiede zwischen diesen Zielen gering. Bei einer Kontextlänge von 81.920 Token erreicht DAPO einen Cross@1 von 67,87 Prozent, während GSPO und GSPO+ 66,26 Prozent und 66,52 Prozent erreichen. Bei 40.960 Token liegen alle drei Ziele bei rund 63 Prozent Cross@1.
Iterative Kontexterweiterung und überlange Filterung
Qwen3-14B unterstützt lange Kontexte und das Coaching folgt einem iterativen Kontexterweiterungsplan. Das Crew trainiert das Modell zunächst mit einem 32.000-Kontextfenster und setzt dann das Coaching mit dem maximalen Qwen3-14B-Kontextfenster von 40.000 fort. In jeder Part wählen sie den Prüfpunkt mit dem besten LiveCodeBench-Rating bei 40.000 Kontext aus und verwenden dann zum Zeitpunkt der Auswertung die YaRN-Kontexterweiterung, um 80.000 Token, additionally 81.920 Token, zu erreichen.
Ein wichtiger Trick ist die zu lange Filterung. Wenn ein generiertes Programm das maximale Kontextfenster überschreitet, wird sein Vorteil auf Null zurückgesetzt. Dadurch wird dieser Rollout aus dem Gradientensignal entfernt, anstatt ihn zu benachteiligen. Das Forschungsteam berichtet, dass dieser Ansatz vermeidet, das Modell aus reinen Optimierungsgründen in Richtung kürzerer Lösungen zu drängen, und dabei hilft, die Qualität aufrechtzuerhalten, wenn die Kontextlänge zum Testzeitpunkt skaliert wird.
Wichtige Erkenntnisse
- NousCoder 14B ist ein Qwen3-14B-basiertes, wettbewerbsfähiges Programmiermodell, das mit ausführungsbasiertem RL trainiert wurde. Es erreicht 67,87 Prozent Cross@1 auf LiveCodeBench v6, ein Plus von 7,08 Prozentpunkten gegenüber der Qwen3-14B-Basislinie von 60,79 Prozent auf demselben Benchmark.
- Das Modell wird auf 24.000 überprüfbare Codierungsprobleme von TACO Verified, PrimeIntellect SYNTHETIC-1 und LiveCodeBench-Aufgaben vor dem 31.07.2024 trainiert und an einem disjunkten LiveCodeBench v6-Testsatz von 454 Problemen vom 01.08.2024 bis 01.05.2025 ausgewertet.
- Das RL-Setup verwendet Atropos mit Python-Lösungen, die in Sandbox-Containern ausgeführt werden, einer einfachen Belohnung von 1 für die Lösung aller Testfälle und minus 1 für jeden Fehler oder jede Verletzung des Ressourcenlimits sowie ein Pipeline-Design, bei dem Inferenz und Überprüfung asynchron ausgeführt werden.
- Gruppenrelative Richtlinienoptimierungsziele DAPO, GSPO und GSPO+ werden für RL mit langem Kontextcode verwendet, arbeiten alle mit gruppennormalisierten Belohnungen und zeigen eine ähnliche Leistung, wobei DAPO den besten Cross@1 im längsten 81.920-Token-Kontext erreicht.
- Das Coaching verwendet eine iterative Kontexterweiterung, zunächst auf 32.000, dann auf 40.000 Token, zusammen mit einer YaRN-basierten Erweiterung zur Evaluierungszeit auf 81.920 Token, umfasst überlange Rollout-Filterung für Stabilität und wird als vollständig reproduzierbarer offener Stapel mit Apache 2.0-Gewichten und RL-Pipeline-Code geliefert.
Schauen Sie sich das an Modellgewichte Und Technische Particulars. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser Publication. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Asif Razzaq ist CEO von Marktechpost Media Inc.. Als visionärer Unternehmer und Ingenieur setzt sich Asif dafür ein, das Potenzial der künstlichen Intelligenz für das soziale Wohl zu nutzen. Sein jüngstes Unterfangen ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch eine ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die sowohl technisch fundiert als auch für ein breites Publikum leicht verständlich ist. Die Plattform verfügt über mehr als 2 Millionen monatliche Aufrufe, was ihre Beliebtheit beim Publikum verdeutlicht.