
KI- und ML-Entwickler arbeiten bei der Vorverarbeitung von Daten häufig mit lokalen Datensätzen. Technische Funktionen und die Erstellung von Prototypen machen dies einfach, ohne den Overhead eines vollständigen Servers. Der häufigste Vergleich erfolgt zwischen SQLite, einer im Jahr 2000 veröffentlichten serverlosen Datenbank, die häufig für einfache Transaktionen verwendet wird, und DuckDB, das 2019 als SQLite der Analyse eingeführt wurde und sich auf schnelle prozessinterne Analyseabfragen konzentriert. Obwohl beide eingebettet sind, unterscheiden sich ihre Ziele. In diesem Artikel vergleichen wir DuckDB und SQLite, um Ihnen bei der Auswahl des richtigen Instruments für jede Part Ihres KI-Workflows zu helfen.
Was ist SQLite?
SQLite ist eine eigenständige Datenbank-Engine, die serverlos ist. Es erstellt eine Schaltfläche direkt aus einer Festplattendatei. Es ist nullkonfiguriert und hat einen geringen Platzbedarf. Die gesamte Datenbank wird in einer Datei namens.sqlite gespeichert und die Tabellen und Indizes sind alle in dieser Datei enthalten. Die Engine selbst ist eine C-Bibliothek, die in Ihre Anwendung eingebettet ist.
SQLite ist ein SÄURE-kompatible Datenbank, auch wenn sie einfach ist. Dies macht die Transaktionen und die Datenintegrität zuverlässig.
Zu den Hauptmerkmalen gehören:
- Zeilenorientierte Speicherung: Die Daten werden zeilenweise gespeichert. Dies macht das Aktualisieren oder Abrufen einer einzelnen Zeile sehr effizient.
- Einzeldateidatenbank: Die gesamte Datenbank befindet sich in einer einzigen Datei. Dies ermöglicht ein einfaches Kopieren oder Übertragen.
- Kein Serverprozess: Direktes Lesen und Schreiben in die Datenbankdatei erfolgt in Ihrer Anwendung. Es ist kein separater Server erforderlich.
- Umfassende SQL-Unterstützung: Es basiert auf den meisten SQL-2 und unterstützt Dinge wie Joins, Fensterfunktionen und Indizes.
SQLite wird häufig in mobilen Anwendungen und verwendet Web der Dingesowie kleine Webanwendungen. Es ist sinnvoll, wenn Sie eine unkomplizierte Lösung zum lokalen Speichern strukturierter Daten benötigen und zahlreiche kurze Lese- und Schreibvorgänge benötigen.
Was ist DuckDB?
DuckDB ist eine prozessinterne Datenanalysedatenbank. Es nutzt die Stärke der SQL-Datenbank für eingebettete Anwendungen. Es führt komplizierte analytische Abfragen effektiv und ohne Server aus. Dieser analytische Fokus ist häufig die Grundlage für den Vergleich zwischen DuckDB und SQLite.
Die wichtigen Merkmale von DuckDB Sind:
- Spaltenspeicherformat: DuckDB speichert Datenspalten. In diesem Format ist es in der Lage, große Datensätze mit viel höherer Geschwindigkeit zu scannen und zusammenzuführen. Es liest nur die Spalten, die es benötigt.
- Vektorisierte Abfrageausführung: DuckDB ist darauf ausgelegt, Berechnungen in Blöcken oder Vektoren statt in einer einzelnen Zeile durchzuführen. Bei dieser Methode werden die aktuellen CPU-Leistungen genutzt, um schneller zu rechnen.
- Direkte Dateiabfrage: DuckDB kann Parquet-, CSV- und Arrow-Dateien direkt abfragen. Es besteht keine Notwendigkeit, sie in die Datenbank aufzunehmen.
- Tiefe Information-Science-Integration: Es ist kompatibel mit Pandas, NumPy Und R. DataFrame können Fragen wie Datenbanktabellen gestellt werden.
Mit DuckDB lassen sich interaktive Datenanalysen in Jupyter-Notebooks schnell verarbeiten und Pandas-Workflows beschleunigen. Es umfasst Information-Warehouse-Funktionen in einem kleinen und lokalen Paket.
Hauptunterschiede
Hier ist zunächst eine Übersichtstabelle, in der SQLite und DuckDB hinsichtlich wichtiger Aspekte verglichen werden.
| Aspekt | SQLite (seit 2000) | DuckDB (seit 2019) |
| Hauptzweck | Eingebettete OLTP-Datenbank (Transaktionen) | Eingebettete OLAP-Datenbank (Analyse) |
| Speichermodell | Zeilenbasiert (speichert ganze Zeilen zusammen) | Columnar (speichert Spalten zusammen) |
| Abfrageausführung | Iterative zeilenweise Verarbeitung | Vektorisierte Stapelverarbeitung |
| Leistung | Hervorragend geeignet für kleine, häufige Transaktionen | Hervorragend geeignet für analytische Abfragen großer Datenmengen |
| Datengröße | Optimiert für kleine bis mittlere Datensätze | Verarbeitet große Datensätze mit nicht genügend Arbeitsspeicher |
| Parallelität | Multi-Reader, Single-Author (über Sperren) | Multi-Reader, Single-Author; parallele Abfrageausführung |
| Speichernutzung | Standardmäßig minimaler Speicherbedarf | Nutzt den Speicher für Geschwindigkeit; kann mehr RAM verwenden |
| SQL-Funktionen | Robustes Foundation-SQL mit einigen Einschränkungen | Umfassende SQL-Unterstützung für erweiterte Analysen |
| Indizes | B-Tree-Indizes werden häufig benötigt | Verlässt sich auf Spaltenscans; Die Indizierung ist weniger verbreitet |
| Integration | Unterstützt in quick jeder Sprache | Native Integration mit Pandas, Arrow, NumPy |
| Dateiformate | Proprietäre Datei; kann CSVs importieren/exportieren | Kann Parquet, CSV, JSON, Arrow direkt abfragen |
| Transaktionen | Vollständig ACID-konform | ACID innerhalb eines einzigen Prozesses |
| Parallelität | Single-Threaded-Abfrageausführung | Multithread-Ausführung für eine einzelne Abfrage |
| Typische Anwendungsfälle | Cellular Apps, IoT-Geräte, lokaler App-Speicher | Datenwissenschaftliche Notizbücher, lokale ML-Experimente |
| Lizenz | Public Area | MIT-Lizenz (Open Supply) |
Diese Tabelle zeigt, dass SQLite sich auf die Zuverlässigkeit und den Betrieb von Transaktionen konzentriert. DuckDB ist für die Unterstützung schneller Analyseabfragen zu Huge Information optimiert. Jetzt werden wir jeden einzelnen davon besprechen.
Praxisnah in Python: Von der Theorie zur Praxis
Wir werden sehen, wie man beide Datenbanken nutzt Python. Es handelt sich um eine Open-Supply-KI-Entwicklungsumgebung.
Verwendung von SQLite
Dies ist eine einfache Darstellung von SQLite Python. Wir werden eine Tabelle entwickeln, Daten eingeben und eine Abfrage ausführen.
import sqlite3
# Connect with a SQLite database file
conn = sqlite3.join("instance.db")
cur = conn.cursor()
# Create a desk
cur.execute(
"""
CREATE TABLE customers (
id INTEGER PRIMARY KEY,
identify TEXT,
age INTEGER
);
"""
)
# Insert data into the desk
cur.execute(
"INSERT INTO customers (identify, age) VALUES (?, ?);",
("Alice", 30)
)
cur.execute(
"INSERT INTO customers (identify, age) VALUES (?, ?);",
("Bob", 35)
)
conn.commit()
# Question the desk
for row in cur.execute(
"SELECT identify, age FROM customers WHERE age > 30;"
):
print(row)
# Anticipated output: ('Bob', 35)
conn.shut()Ausgabe:
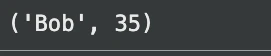
Die Datenbank wird in diesem Fall im gespeichert instance.db Datei. Wir haben eine Tabelle erstellt, ihr zwei Zeilen hinzugefügt und eine einfache Abfrage ausgeführt. Mit SQLite können Sie Daten in die Tabellen laden und dann abfragen. Falls Sie eine CSV-Datei haben, müssen Sie die Informationen zuerst importieren.
Verwenden von DuckDB
Dennoch ist es an der Zeit, diese Choice mit DuckDB zu wiederholen. Wir werden Sie auch auf die datenwissenschaftlichen Annehmlichkeiten aufmerksam machen.
import duckdb
import pandas as pd
# Connect with an in-memory DuckDB database
conn = duckdb.join()
# Create a desk and insert knowledge
conn.execute(
"""
CREATE TABLE customers (
id INTEGER,
identify VARCHAR,
age INTEGER
);
"""
)
conn.execute(
"INSERT INTO customers VALUES (1, 'Alice', 30), (2, 'Bob', 35);"
)
# Run a question on the desk
outcome = conn.execute(
"SELECT identify, age FROM customers WHERE age > 30;"
).fetchall()
print(outcome) # Anticipated output: (('Bob', 35))Ausgabe:
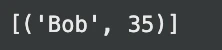
Die einfache Verwendung ähnelt der grundlegenden Verwendung. Dennoch können auch externe Daten von DuckDB abgefragt werden.
Lassen Sie uns einen zufälligen Datensatz für die Abfrage generieren:
import pandas as pd
import numpy as np
# Generate random gross sales knowledge
np.random.seed(42)
num_entries = 1000
knowledge = {
"class": np.random.selection(
("Electronics", "Clothes", "Dwelling Items", "Books"),
num_entries
),
"worth": np.spherical(
np.random.uniform(10, 500, num_entries),
2
),
"area": np.random.selection(
("EUROPE", "AMERICA", "ASIA"),
num_entries
),
"sales_date": (
pd.to_datetime("2023-01-01")
+ pd.to_timedelta(
np.random.randint(0, 365, num_entries),
unit="D"
)
)
}
sales_df = pd.DataFrame(knowledge)
# Save to sales_data.csv
sales_df.to_csv("sales_data.csv", index=False)
print("Generated 'sales_data.csv' with 1000 entries.")
print(sales_df.head())Ausgabe:
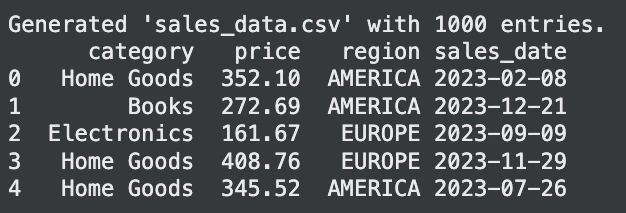
Fragen wir nun diese Tabelle ab:
# Assume 'sales_data.csv' exists
# Instance 1: Querying a CSV file instantly
avg_prices = conn.execute(
"""
SELECT
class,
AVG(worth) AS avg_price
FROM 'sales_data.csv'
WHERE area = 'EUROPE'
GROUP BY class;
"""
).fetchdf() # Returns a Pandas DataFrame
print(avg_prices.head())
# Instance 2: Querying a Pandas DataFrame instantly
df = pd.DataFrame({
"id": vary(1000),
"worth": vary(1000)
})
outcome = conn.execute(
"SELECT COUNT(*) FROM df WHERE worth % 2 = 0;"
).fetchone()
print(outcome) # Anticipated output: (500,)Ausgabe:
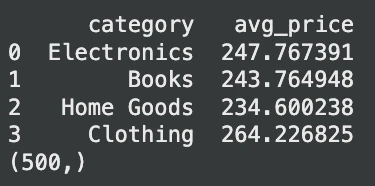
In diesem Fall liest DuckDB die CSV-Datei im laufenden Betrieb. Es ist kein wichtiger Schritt erforderlich. Es ist auch in der Lage, a abzufragen Pandas Datenrahmen. Durch diese Flexibilität entfällt ein Großteil des Datenladecodes und vereinfacht KI-Pipelines.
Architektur: Warum sie so unterschiedlich funktionieren
Die Unterschiede in der Leistung von SQLite und DuckDB hängen mit ihren Speicher- und Abfrage-Engines zusammen.
- Speichermodell: SQLite ist zeilenbasiert. Es gruppiert darin alle Daten einer Zeile. Dies eignet sich sehr intestine zum Aktualisieren eines einzelnen Datensatzes. Dennoch ist es mit der Analyse nicht schnell. Angenommen, Sie benötigen nur eine einzelne Spalte, dann muss SQLite trotzdem alle Daten jeder Zeile lesen. DuckDB ist spaltenorientiert. Es fügt alle Werte einer Spalte in eine einzige Spalte ein. Dies ist supreme für Analysen. Eine Abfrage wie
SELECT AVG(age)liest nur die Alter Spalte, was viel schneller ist. - Abfrageausführung: SQLite eine Abfrage professional Zeile. Dies ist speichereffizient, wenn es um kleine Abfragen geht. DuckDB basiert auf einer vektorisierten Ausführung. Es funktioniert mit Daten in großen Mengen. Diese Technik nutzt aktuelle CPUs, um große Scans und Verknüpfungen erheblich zu beschleunigen. Es ist auch in der Lage, mehrere Threads auszuführen, um jeweils eine einzelne Abfrage auszuführen.
- Speicher und Verhalten auf der Festplatte: SQLite ist so konzipiert, dass es nur minimalen Speicher benötigt. Es liest nach Bedarf von der Festplatte. DuckDB nutzt Speicher, um die Geschwindigkeit zu erhöhen. Bei der Out-of-Core-Ausführung können Daten ausgeführt werden, die größer sind als der verfügbare RAM. Dies bedeutet, dass DuckDB zusätzlichen RAM verbrauchen kann, bei einer Analyseaufgabe jedoch viel schneller ist. Es wurde gezeigt, dass Aggregationsabfragen in DuckDB 10–100 Mal schneller sind als in SQLite.
Das Urteil: Wann sollte man DuckDB vs. SQLite verwenden?
Dies ist eine gute Richtlinie, die Sie bei Ihren KI- und maschinellen Lernprojekten befolgen sollten.
| Aspekt | Verwenden Sie SQLite, wenn | Verwenden Sie DuckDB, wenn |
|---|---|---|
| Hauptzweck | Sie benötigen eine schlanke Transaktionsdatenbank | Sie benötigen schnelle lokale Analysen |
| Datengröße | Geringes Datenvolumen, bis zu einigen hundert MB | Mittlere bis große Datensätze |
| Arbeitslasttyp | Einfügungen, Aktualisierungen und einfache Suchvorgänge | Aggregationen, Joins und große Tabellenscans |
| Transaktionsbedarf | Häufige kleine Updates mit Transaktionsintegrität | Leseintensive analytische Abfragen |
| Dateiverwaltung | In der Datenbank gespeicherte Daten | Fragen Sie CSV- oder Parquet-Dateien direkt ab |
| Leistungsfokus | Minimaler Platzbedarf und Einfachheit | Hochgeschwindigkeits-Analyseleistung |
| Integration | Cellular Apps, eingebettete Systeme, IoT | Beschleunigung der Pandas-basierten Analyse |
| Parallele Ausführung | Keine Priorität | Verwendet mehrere CPU-Kerne |
| Typischer Anwendungsfall | Anwendungsstatus und leichter Speicher | Lokale Datenexploration und -analyse |
Abschluss
Sowohl SQLite als auch DuckDB sind starke eingebettete Datenbanken. SQLite ist ein sehr gutes, leichtes Datenspeicher- und benutzerfreundliches Transaktionstool. Allerdings kann DuckDB die Datenverarbeitung und das Prototyping von KI-Entwicklern, die mit Huge Information arbeiten, erheblich beschleunigen. Denn wenn Sie sich der Unterschiede bewusst sind, wissen Sie, welches Werkzeug für verschiedene Aufgaben das richtige ist. Bei zeitgemäßen Datenanalyse- und Machine-Studying-Prozessen kann DuckDB Ihnen viel Zeit sparen und gleichzeitig einen erheblichen Leistungsvorteil bieten.
Häufig gestellte Fragen
A. Nein, sie dienen anderen Zwecken. DuckDB wird für den Zugriff auf schnelle Analysen (OLAP) verwendet, während SQLite für die Durchführung zuverlässiger Transaktionen verwendet wird. Wählen Sie entsprechend Ihrer Arbeitsbelastung.
A. SQLite eignet sich in der Regel besser für Webanwendungen mit einer großen Anzahl kleiner, kommunizierender Lese- und Schreibvorgänge, da es über ein solides Transaktionsmodell und einen WAL-Modus verfügt.
A. Ja, bei den meisten Großaufträgen wie Gruppierungen und Verknüpfungen kann DuckDB aufgrund seiner parallelen, vektorisierten Engine viel schneller als Pandas sein.
Harsh Mishra ist ein KI/ML-Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit echten Menschen. Leidenschaftlich für GenAI, NLP und die intelligentere Entwicklung von Maschinen (damit sie ihn noch nicht ersetzen). Wenn er nicht gerade Modelle optimiert, optimiert er wahrscheinlich seinen Kaffeekonsum. 🚀☕
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.