

Unsicherheit beim maschinellen Lernen: Wahrscheinlichkeit und Rauschen
Bild vom Autor
Anmerkung des Herausgebers: Dieser Artikel ist Teil unserer Serie zur Visualisierung der Grundlagen des maschinellen Lernens.
Willkommen zum neuesten Eintrag unserer Reihe zur Visualisierung der Grundlagen des maschinellen Lernens. In dieser Serie wollen wir wichtige und oft komplexe technische Konzepte in intuitive, visuelle Leitfäden herunterbrechen, um Ihnen dabei zu helfen, die Kernprinzipien des Fachgebiets zu beherrschen. Dieser Eintrag konzentriert sich auf die Unsicherheit, Wahrscheinlichkeit und das Rauschen beim maschinellen Lernen.
Unsicherheit beim maschinellen Lernen
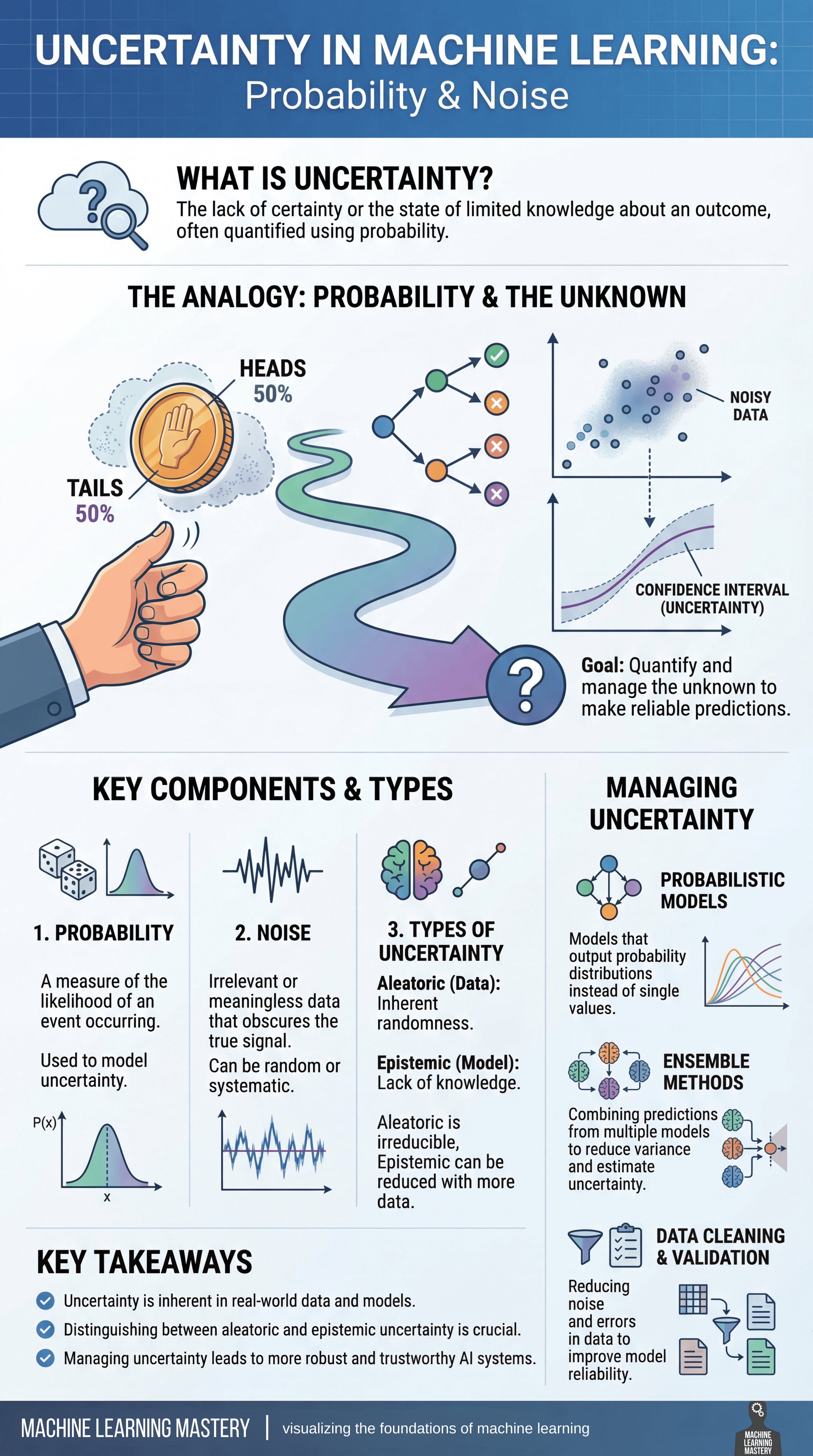
Unsicherheit ist ein unvermeidbarer Teil des maschinellen Lernens und entsteht immer dann, wenn Modelle versuchen, Vorhersagen über die reale Welt zu treffen. Im Kern spiegelt Unsicherheit a Mangel an vollständigem Wissen über ein Ergebnis und wird am häufigsten anhand der Wahrscheinlichkeit quantifiziert. Unsicherheit ist kein Fehler, sondern etwas, das Modelle explizit berücksichtigen müssen, um zuverlässige und vertrauenswürdige Vorhersagen zu erstellen.
Eine nützliche Möglichkeit, über Unsicherheit nachzudenken, ist die Betrachtung der Wahrscheinlichkeit und des Unbekannten. Ähnlich wie beim Werfen einer fairen Münze, bei der das Ergebnis ungewiss ist, obwohl die Wahrscheinlichkeiten klar definiert sind, funktionieren maschinelle Lernmodelle häufig in Umgebungen, in denen mehrere Ergebnisse möglich sind. Während Daten durch ein Modell fließen, verzweigen sich Vorhersagen in verschiedene Pfade, die durch Zufälligkeit, unvollständige Informationen und Variabilität in den Daten selbst beeinflusst werden.
Das Ziel der Arbeit mit Unsicherheit besteht nicht darin, sie zu beseitigen, sondern darin, sie zu beseitigen messen und verwalten. Dazu gehört das Verständnis mehrerer Schlüsselkomponenten:
- Wahrscheinlichkeit bietet einen mathematischen Rahmen, um auszudrücken, wie wahrscheinlich es ist, dass ein Ereignis eintritt
- Lärm stellt irrelevante oder zufällige Variationen in Daten dar, die das wahre Sign verschleiern und entweder zufällig oder systematisch sein können
Zusammen, Diese Faktoren prägen die Unsicherheit, die in den Vorhersagen eines Modells vorhanden ist.
Nicht jede Unsicherheit ist gleich. Aleatorische Unsicherheit beruht auf der inhärenten Zufälligkeit der Daten und kann auch mit mehr Informationen nicht reduziert werden. Epistemische UnsicherheitAndererseits entsteht sie durch mangelndes Wissen über das Modell oder den Datengenerierungsprozess und kann oft durch die Sammlung weiterer Daten oder die Verbesserung des Modells reduziert werden. Die Unterscheidung zwischen diesen beiden Typen ist für die Interpretation des Modellverhaltens und die Entscheidung, wie die Leistung verbessert werden kann, von entscheidender Bedeutung.
Um mit Unsicherheit umzugehen, greifen Praktiker des maschinellen Lernens auf mehrere Strategien zurück. Wahrscheinlichkeitsmodelle Geben Sie vollständige Wahrscheinlichkeitsverteilungen anstelle von Einzelpunktschätzungen aus, wodurch die Unsicherheit deutlich wird. Ensemble-Methoden Kombinieren Sie Vorhersagen aus mehreren Modellen, um die Varianz zu reduzieren und die Unsicherheit besser abzuschätzen. Datenbereinigung und -validierung Verbessern Sie die Zuverlässigkeit weiter, indem Sie Rauschen reduzieren und Fehler vor dem Coaching korrigieren.
Unsicherheit ist in realen Daten und maschinellen Lernsystemen inhärent. Durch das Erkennen der Quellen und deren direkte Einbeziehung in die Modellierung und Entscheidungsfindung können Praktiker Modelle erstellen, die nicht nur genauer, sondern auch genauer sind Sturdy, clear und vertrauenswürdig.
Die folgende Visualisierung bietet eine kurze Zusammenfassung dieser Informationen zum schnellen Nachschlagen. Sie können eine finden PDF der Infografik in hoher Auflösung hier.
Unsicherheit, Wahrscheinlichkeit und Rauschen: Visualisierung der Grundlagen des maschinellen Lernens (zum Vergrößern klicken)
Bild vom Autor
Ressourcen zur Beherrschung des maschinellen Lernens
Dies sind einige ausgewählte Ressourcen, um mehr über Wahrscheinlichkeit und Rauschen zu erfahren:
- Eine sanfte Einführung in die Unsicherheit beim maschinellen Lernen – Dieser Artikel erklärt, was Unsicherheit beim maschinellen Lernen bedeutet, untersucht die Hauptursachen wie Datenrauschen, unvollständige Abdeckung und unvollständige Modelle und beschreibt, wie Wahrscheinlichkeit die Werkzeuge zur Quantifizierung und Verwaltung dieser Unsicherheit bereitstellt.
Schlüssel zum Mitnehmen: Wahrscheinlichkeit ist für das Verständnis und den Umgang mit Unsicherheiten bei der Vorhersagemodellierung von entscheidender Bedeutung. - Wahrscheinlichkeit für maschinelles Lernen (7-tägiger Minikurs) – Dieser strukturierte Crashkurs führt Leser durch die wichtigsten Wahrscheinlichkeitskonzepte, die beim maschinellen Lernen erforderlich sind, von grundlegenden Wahrscheinlichkeitstypen und -verteilungen bis hin zu Naive Bayes und Entropie, mit praktischen Lektionen, die dazu dienen sollen, Vertrauen bei der Anwendung dieser Ideen in Python aufzubauen.
Schlüssel zum Mitnehmen: Der Aufbau einer soliden Wahrscheinlichkeitsgrundlage verbessert Ihre Fähigkeit, Modelle des maschinellen Lernens anzuwenden und zu interpretieren. - Wahrscheinlichkeitsverteilungen für maschinelles Lernen mit Python verstehen – Dieses Tutorial stellt wichtige Wahrscheinlichkeitsverteilungen vor, die beim maschinellen Lernen verwendet werden, zeigt, wie sie auf Aufgaben wie die Modellierung von Residuen und die Klassifizierung angewendet werden, und stellt Python-Beispiele bereit, um Praktikern zu helfen, sie zu verstehen und effektiv zu nutzen.
Schlüssel zum Mitnehmen: Die Beherrschung von Wahrscheinlichkeitsverteilungen hilft Ihnen, Unsicherheiten zu modellieren und geeignete statistische Instruments im gesamten maschinellen Lernworkflow auszuwählen.
Halten Sie Ausschau nach weiteren Einträgen in unserer Reihe zur Visualisierung der Grundlagen des maschinellen Lernens.
Über Matthew Mayo
Matthew Mayo (@mattmayo13) hat einen Grasp-Abschluss in Informatik und ein Diplom in Knowledge Mining. Als geschäftsführender Herausgeber von KDnuggets & Statistikund Mitherausgeber bei Beherrschung des maschinellen LernensZiel von Matthew ist es, komplexe datenwissenschaftliche Konzepte zugänglich zu machen. Zu seinen beruflichen Interessen zählen die Verarbeitung natürlicher Sprache, Sprachmodelle, Algorithmen für maschinelles Lernen und die Erforschung neuer KI. Seine Mission ist es, das Wissen in der Datenwissenschaftsgemeinschaft zu demokratisieren. Matthew programmiert seit seinem sechsten Lebensjahr.