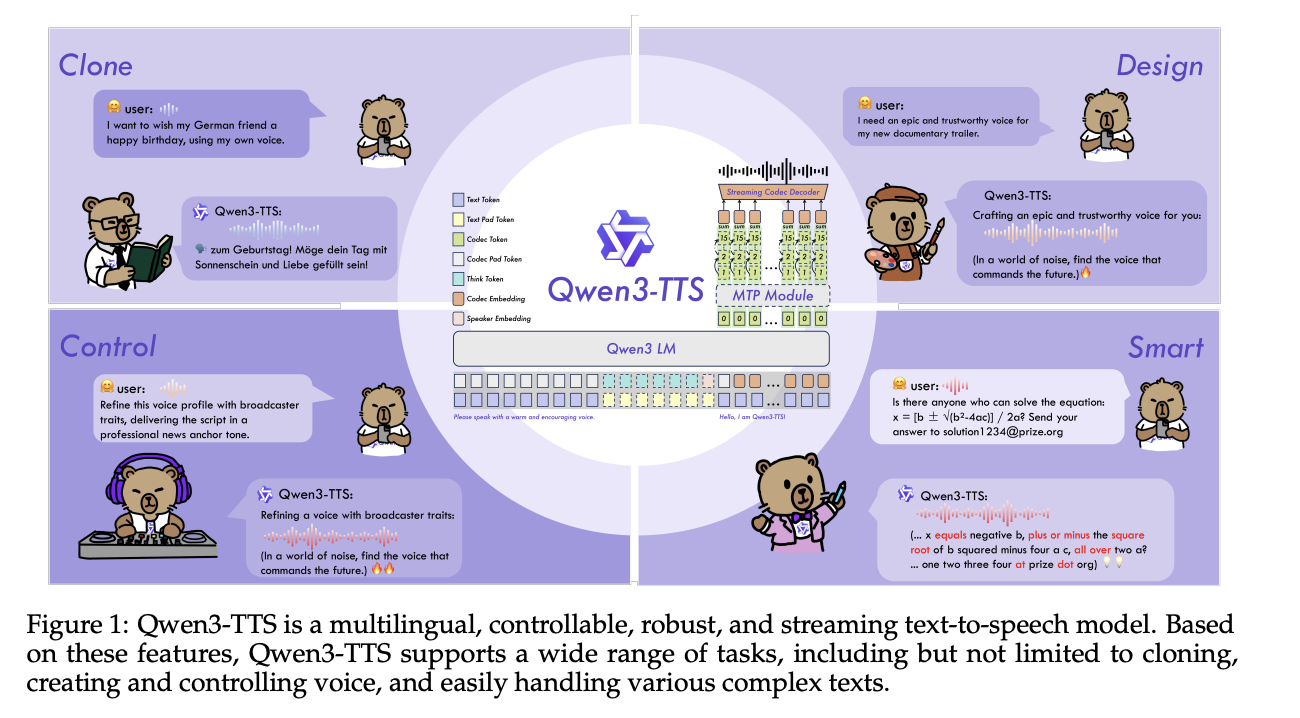
Das Qwen-Workforce von Alibaba Cloud verfügt über Open-Supply-Qwen3-TTS, eine Familie mehrsprachiger Textual content-to-Speech-Modelle, die auf drei Kernaufgaben in einem Stapel abzielen: Sprachklon, Sprachdesign und hochwertige Sprachgenerierung.
Modellfamilie und Fähigkeiten
Qwen3-TTS verwendet einen 12-Hz-Sprach-Tokenizer und zwei Sprachmodellgrößen, 0,6B und 1,7B, verpackt in drei Hauptaufgaben. Die offene Model stellt 5 Modelle zur Verfügung: Qwen3-TTS-12Hz-0.6B-Base und Qwen3-TTS-12Hz-1.7B-Base für das Klonen von Stimmen und generisches TTS, Qwen3-TTS-12Hz-0.6B-CustomVoice und Qwen3-TTS-12Hz-1.7B-CustomVoice für aufforderungsfähige voreingestellte Lautsprecher und Qwen3-TTS-12Hz-1.7B-VoiceDesign für die Freiform-Stimmenerstellung aus Beschreibungen natürlicher Sprache, zusammen mit dem Qwen3-TTS-Tokenizer-12Hz-Codec.
Alle Modelle unterstützen 10 Sprachen: Chinesisch, Englisch, Japanisch, Koreanisch, Deutsch, Französisch, Russisch, Portugiesisch, Spanisch und Italienisch. CustomVoice-Varianten werden mit 9 kuratierten Klangfarben ausgeliefert, darunter Vivian, eine strahlende junge chinesische Frauenstimme, Ryan, eine dynamische englische Männerstimme und Ono_Anna, eine verspielte japanische Frauenstimme, jeweils mit einer kurzen Beschreibung, die Klangfarbe und Sprechstil kodiert.
Das VoiceDesign-Modell ordnet Textanweisungen direkt neuen Stimmen zu, zum Beispiel „Sprechen Sie mit einer nervösen männlichen Teenagerstimme mit steigender Intonation“ und kann dann mit dem Basismodell kombiniert werden, indem zunächst ein kurzer Referenzclip erstellt und über wiederverwendet wird create_voice_clone_prompt.
Architektur, Tokenizer und Streaming-Pfad
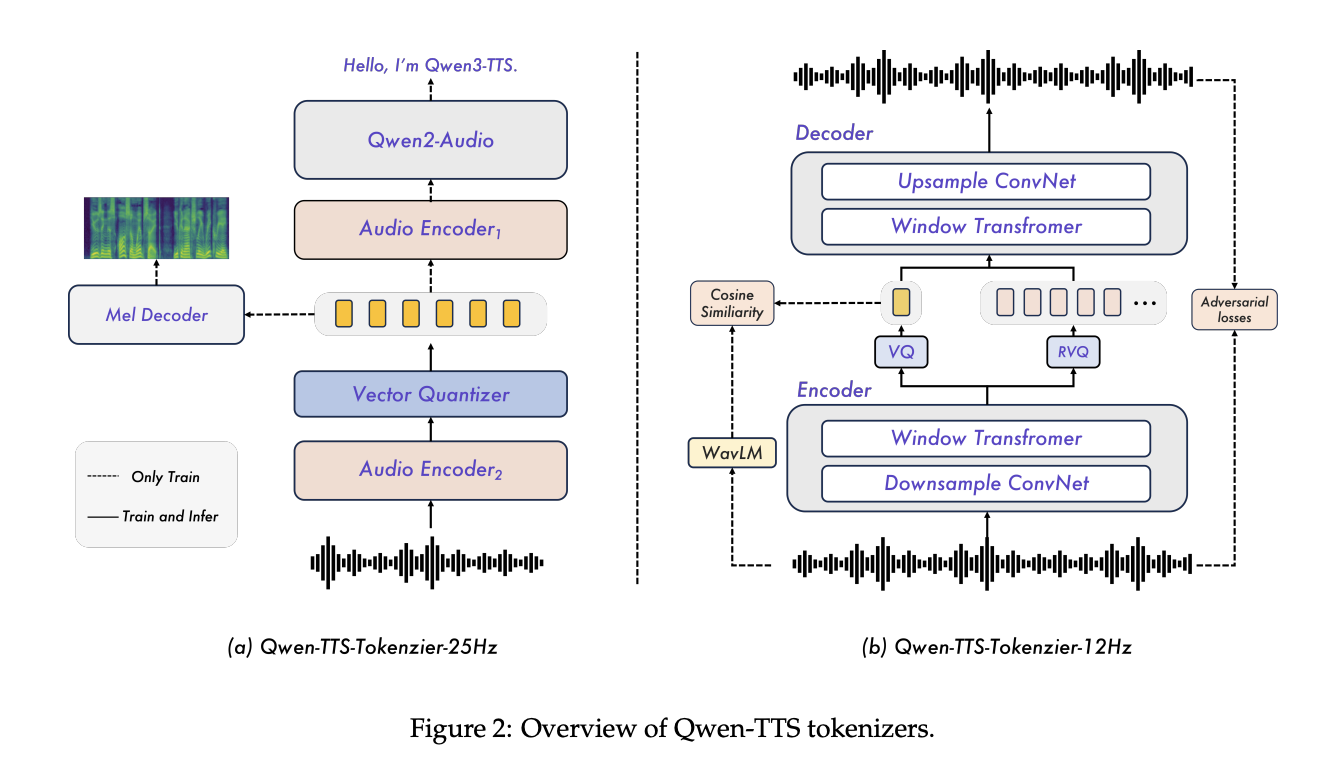
Qwen3-TTS ist ein zweispuriges Sprachmodell. Eine Spur sagt diskrete akustische Token aus Textual content voraus, die andere verarbeitet Ausrichtungs- und Steuersignale. Das System wird auf mehr als 5 Millionen Stunden mehrsprachiger Sprache in drei Vortrainingsphasen trainiert, die von der allgemeinen Zuordnung über hochwertige Daten bis hin zur Langzeitkontextunterstützung von bis zu 32.768 Token reichen.
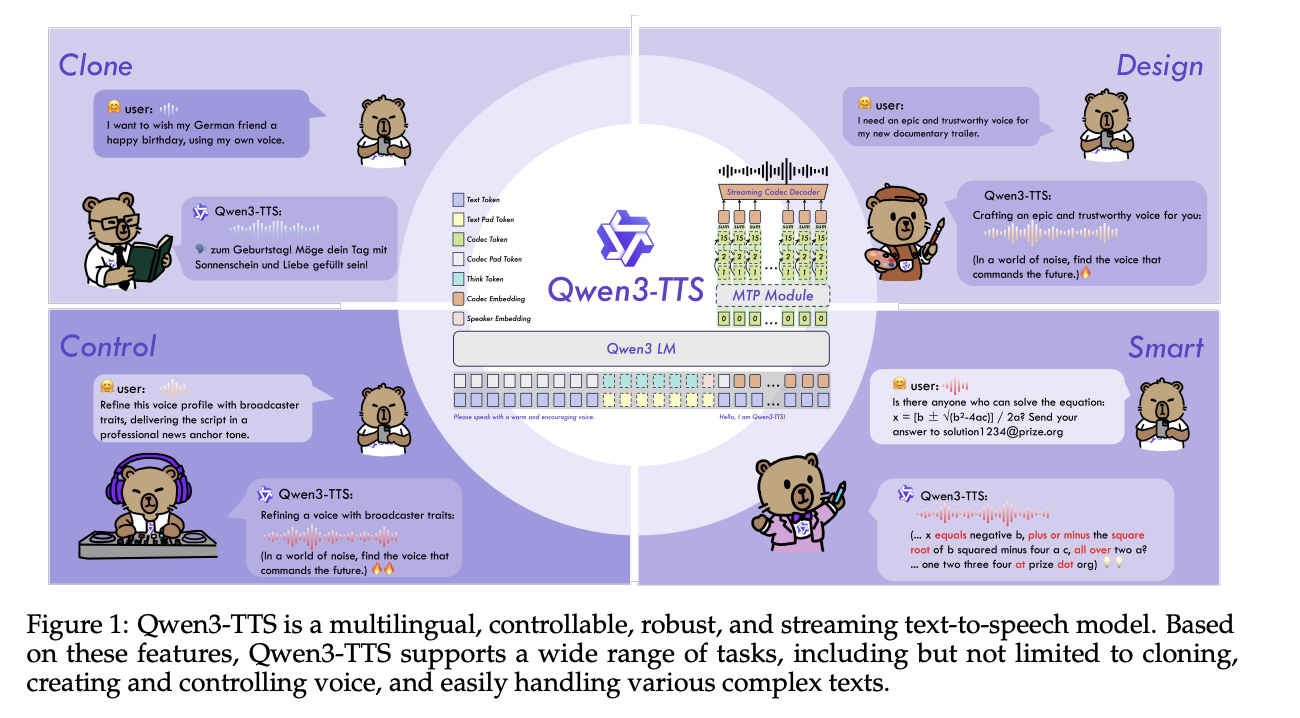
Eine Schlüsselkomponente ist der Qwen3-TTS-Tokenizer-12Hz-Codec. Es arbeitet mit 12,5 Bildern professional Sekunde, etwa 80 ms professional Token, und verwendet 16 Quantisierer mit einem Codebuch mit 2048 Einträgen. Bei der LibriSpeech-Testbereinigung erreicht es PESQ-Breitband 3,21, STOI 0,96 und UTMOS 4,16 und übertrifft damit SpeechTokenizer, XCodec, Mimi, FireredTTS 2 und andere neuere semantische Tokenizer, während eine ähnliche oder niedrigere Bildrate verwendet wird.
Der Tokenizer ist als reiner Linkskontext-Streaming-Decoder implementiert, sodass er Wellenformen aussenden kann, sobald genügend Token verfügbar sind. Bei 4 Token professional Paket überträgt jedes Streaming-Paket 320 ms Audio. Der Nicht-DiT-Decoder und das BigVGAN-freie Design reduzieren die Dekodierungskosten und vereinfachen die Stapelverarbeitung.
Auf der Seite des Sprachmodells berichtet das Forschungsteam über Finish-to-Finish-Streaming-Messungen auf einem einzigen vLLM-Backend mit Torch.compile- und CUDA-Graph-Optimierungen. Für Qwen3-TTS-12Hz-0.6B-Base und Qwen3-TTS-12Hz-1.7B-Base bei Parallelität 1 beträgt die erste Paketlatenz etwa 97 ms und 101 ms, mit Echtzeitfaktoren von 0,288 bzw. 0,313. Selbst bei Parallelität 6 bleibt die Latenz des ersten Pakets bei etwa 299 ms und 333 ms.
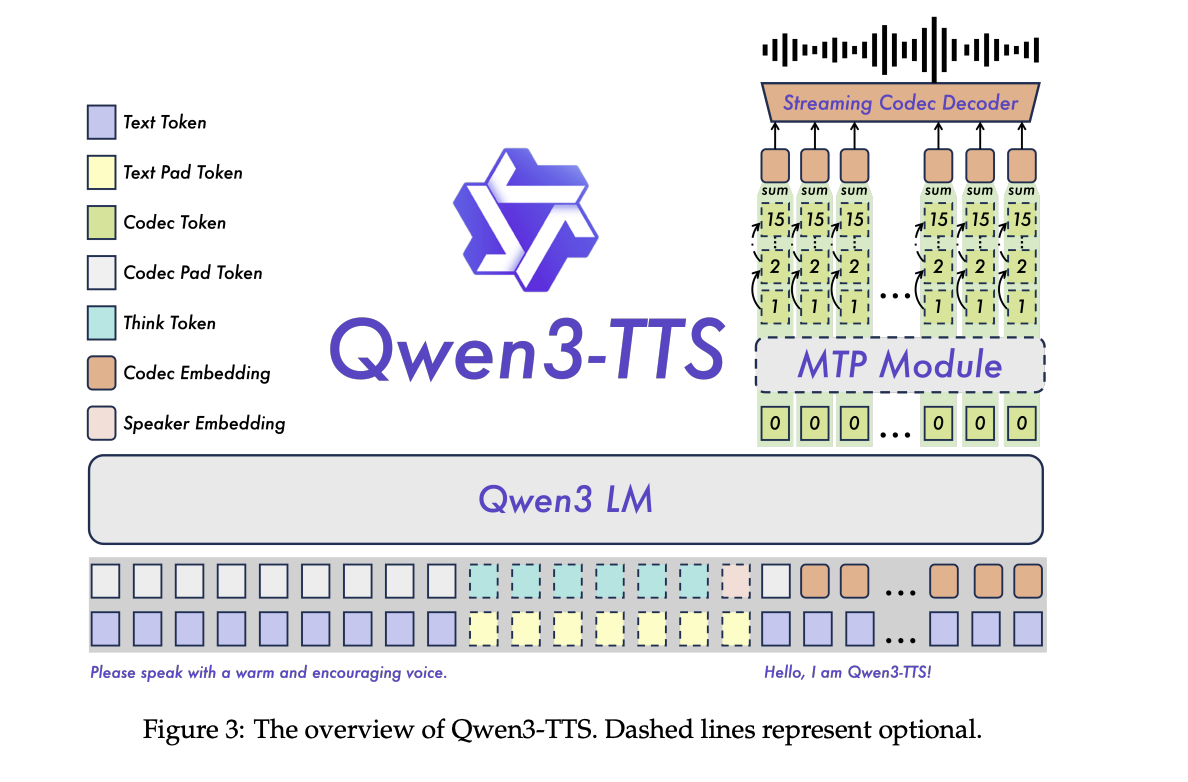
Ausrichtung und Kontrolle
Nach dem Coaching wird eine abgestufte Ausrichtungspipeline verwendet. Erstens richtet die direkte Präferenzoptimierung die generierte Sprache an den menschlichen Präferenzen für mehrsprachige Daten aus. Dann verbessert GSPO mit regelbasierten Belohnungen Stabilität und Prosodie. Eine abschließende Feinabstimmungsphase der Lautsprecher am Basismodell ergibt Ziellautsprechervarianten unter Beibehaltung der Kernfunktionen des allgemeinen Modells.
Das Befolgen von Anweisungen wird in einem ChatML-Format implementiert, bei dem der Eingabe Textanweisungen zu Stil, Emotion oder Tempo vorangestellt werden. Dieselbe Schnittstelle unterstützt VoiceDesign, Ansagen im CustomVoice-Stil und feinkörnige Bearbeitungen für geklonte Lautsprecher.
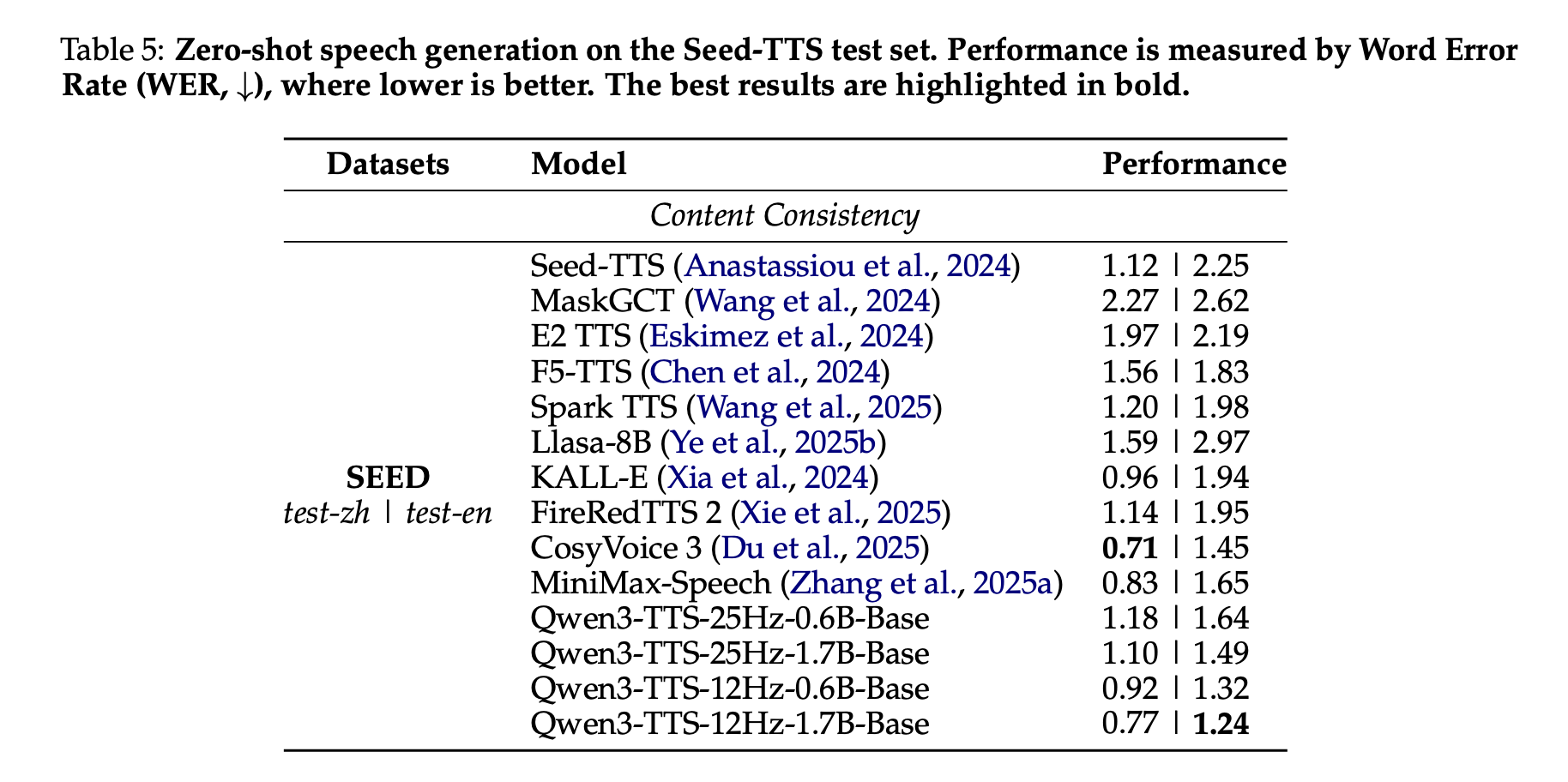
Benchmarks, Zero-Shot-Klonen und mehrsprachige Sprache
Im Seed-TTS-Testsatz wird Qwen3-TTS als Zero-Shot-System zum Klonen von Stimmen bewertet. Das Qwen3-TTS-12Hz-1.7B-Base-Modell erreicht eine Wortfehlerrate von 0,77 bei test-zh und 1,24 bei test-en. Das Forschungsteam hebt den 1,24 WER auf test-en als State of the Artwork unter den verglichenen Systemen hervor, während der chinesische WER nahe am besten CosyVoice 3-Wert liegt, aber nicht darunter liegt.
Bei einem mehrsprachigen TTS-Testset, das 10 Sprachen abdeckt, erreicht Qwen3-TTS den niedrigsten WER in 6 Sprachen, Chinesisch, Englisch, Italienisch, Französisch, Koreanisch und Russisch, und eine konkurrenzfähige Leistung in den verbleibenden 4 Sprachen, während es im Vergleich zu MiniMax-Speech und ElevenLabs Multilingual v2 auch die höchste Sprecherähnlichkeit in allen 10 Sprachen erreicht.
Sprachübergreifende Auswertungen zeigen, dass Qwen3-TTS-12Hz-1.7B-Base die gemischte Fehlerrate für mehrere Sprachpaare reduziert, wie z. B. zh-to-ko, wo der Fehler von 14,4 für CosyVoice3 auf 4,82 sinkt, was einer relativen Reduzierung von etwa 66 Prozent entspricht.
Auf InstructTTSEval setzt das Qwen3TTS-12Hz-1.7B-VD VoiceDesign-Modell neue Spitzenwerte unter Open-Supply-Modellen in Bezug auf Beschreibungs-Sprachkonsistenz und Antwortpräzision in Chinesisch und Englisch und ist in mehreren Metriken mit kommerziellen Systemen wie Hume und Gemini konkurrenzfähig.
Wichtige Erkenntnisse
- Vollständiger mehrsprachiger Open-Supply-TTS-Stack: Qwen3-TTS ist eine Apache 2.0-lizenzierte Suite, die 3 Aufgaben in einem Stapel, hochwertiges TTS, 3-Sekunden-Sprachklonen und anweisungsbasiertes Sprachdesign in 10 Sprachen mithilfe der 12-Hz-Tokenizer-Familie abdeckt.
- Effizienter diskreter Codec und Echtzeit-Streaming: Der Qwen3-TTS-Tokenizer-12Hz verwendet 16 Codebücher bei 12,5 Bildern professional Sekunde, erreicht starke PESQ-, STOI- und UTMOS-Werte und unterstützt paketiertes Streaming mit etwa 320 ms Audio professional Paket und einer Latenzzeit des ersten Pakets von unter 120 ms für die 0,6B- und 1,7B-Modelle im gemeldeten Setup.
- Aufgabenspezifische Modellvarianten: Die Model bietet Basismodelle zum Klonen und generisches TTS, CustomVoice-Modelle mit 9 vordefinierten Lautsprechern und Stilansagen sowie ein VoiceDesign-Modell, das neue Stimmen direkt aus Beschreibungen in natürlicher Sprache generiert, die dann vom Basismodell wiederverwendet werden können.
- Starke Ausrichtung und mehrsprachige Qualität: Eine mehrstufige Alignment-Pipeline mit DPO, GSPO und Sprecher-Feinabstimmung verleiht Qwen3-TTS niedrige Wortfehlerraten und hohe Sprecherähnlichkeit, mit dem niedrigsten WER in 6 von 10 Sprachen und der besten Sprecherähnlichkeit in allen 10 Sprachen unter den bewerteten Systemen sowie modernstem Zero-Shot-Englisch-Klonen auf Seed TTS.
Schauen Sie sich das an Modellgewichte, Repo Und Spielplatz. Sie können uns auch gerne weiter folgen Twitter und vergessen Sie nicht, bei uns mitzumachen 100.000+ ML SubReddit und Abonnieren Unser E-newsletter. Warten! Bist du im Telegram? Jetzt können Sie uns auch per Telegram kontaktieren.
Der Beitrag Qwen-Forscher veröffentlichen Qwen3-TTS: eine offene mehrsprachige TTS-Suite mit Echtzeitlatenz und feinkörniger Sprachsteuerung erschien zuerst auf MarkTechPost.