
Die Zukunft der künstlichen Intelligenz ist da und für die Entwickler liegt sie in Type neuer Instruments, die die Artwork und Weise, wie wir programmieren, Probleme erstellen und lösen, verändern. GLM-4.7 Flash, ein Open-Supply-Modell für große Sprachen von Zhipu AI, ist der neueste große Neuzugang, aber nicht einfach eine weitere Model. Dieses Modell bringt große Leistung und erstaunliche Effizienz mit sich, sodass modernste KI im Bereich der Codegenerierung, mehrstufigen Argumentation und Inhaltsgenerierung einen noch nie dagewesenen Beitrag zu diesem Bereich leistet. Wir sollten uns die Gründe genauer ansehen, warum GLM-4.7 Flash bahnbrechend ist.
Architektur und Evolution: Sensible, schlank und leistungsstark
GLM-4.7 Flash verfügt im Kern über eine fortschrittliche Funktion Combination-of-Specialists (MoE) Transformatorarchitektur. Denken Sie an ein Workforce aus spezialisierten Fachleuten. Nehmen wir an, nicht jeder einzelne Experte befasst sich mit allen Problemen, sondern nur die relevantesten mit einer bestimmten Aufgabe. So funktionieren MoE-Modelle. Obwohl das gesamte GLM-4.7-Modell enorme und riesige (in die Tausende gehende) 358 Milliarden Parameter enthält, ist nur ein Teil davon: etwa 32 Milliarden Parameter sind in einer bestimmten Abfrage aktiv.
Die Flash-Model von GLM-4.7 ist mit rund 30 Milliarden Gesamtparametern und Tausenden aktiven Parametern professional Anfrage noch einfacher. Ein solches Design macht es sehr effizient, da es auf relativ kleiner {Hardware} betrieben werden kann und dennoch auf eine große Menge an Wissen zugreifen kann.
Einfacher API-Zugriff für nahtlose Integration
Der Einstieg in GLM-4.7 Flash ist einfach. Es ist als Zhipu erhältlich Z.AI API-Plattform Bereitstellung einer ähnlichen Schnittstelle wie OpenAI oder Anthropic. Das Modell ist außerdem vielseitig für eine Vielzahl von Aufgaben geeignet, sei es für direkte REST-Aufrufe oder ein SDK.
Dies sind einige der praktischen Anwendungen mit Python:
1. Kreative Textgenerierung
Brauchen Sie einen Funken Kreativität? Sie können das Mannequin ein Gedicht oder einen Marketingtext schreiben lassen.
import requests
api_url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content material-Kind": "software/json"
}
user_message = {"position": "consumer", "content material": "Write a brief, optimistic poem about the way forward for expertise."}
payload = {
"mannequin": "glm-4.7-flash",
"messages": (user_message),
"max_tokens": 200,
"temperature": 0.8
}
response = requests.publish(api_url, headers=headers, json=payload)
outcome = response.json()
print(outcome("decisions")(0)("message")("content material"))Ausgabe:
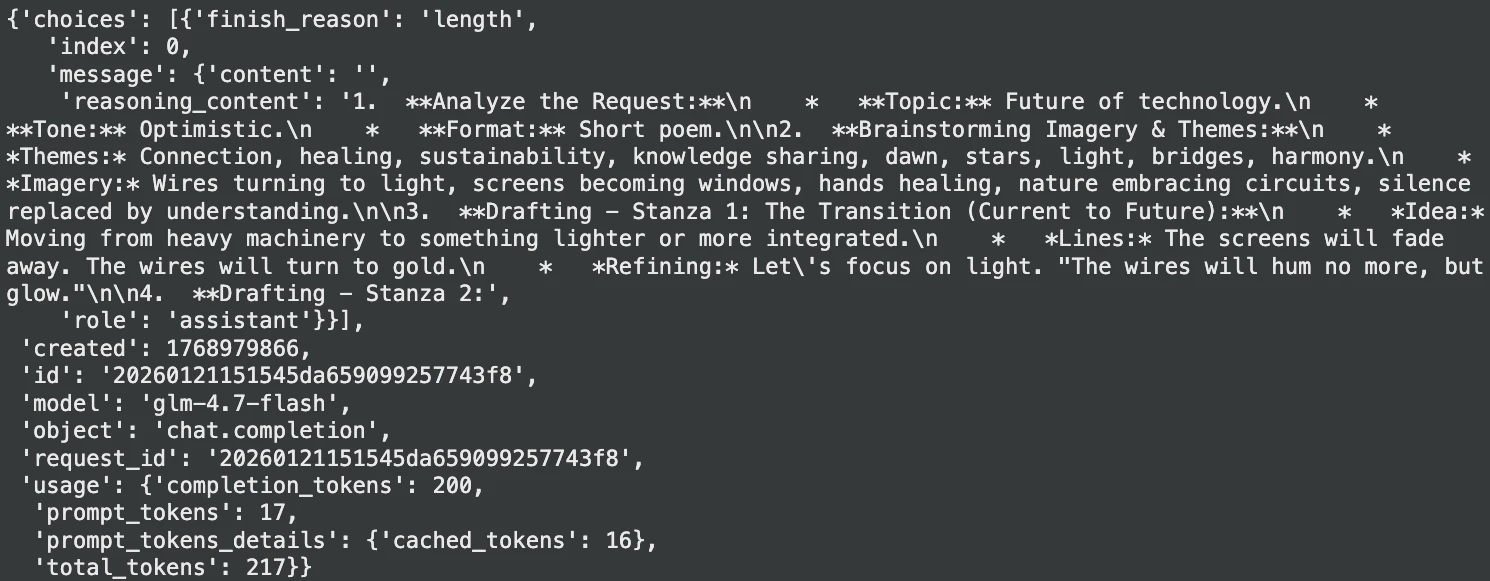
2. Zusammenfassung des Dokuments
Es verfügt über ein großes Kontextfenster, das den Überblick über umfangreiche Dokumente erleichtert.
text_to_summarize = "Your intensive article or report goes right here..."
immediate = f"Summarize the next textual content into three key bullet factors:n{text_to_summarize}"
payload = {
"mannequin": "glm-4.7-flash",
"messages": ({"position": "consumer", "content material": immediate}),
"max_tokens": 500,
"temperature": 0.3
}
response = requests.publish(api_url, json=payload, headers=headers)
abstract = response.json()("decisions")(0)("message")("content material")
print("Abstract:", abstract)Ausgabe:
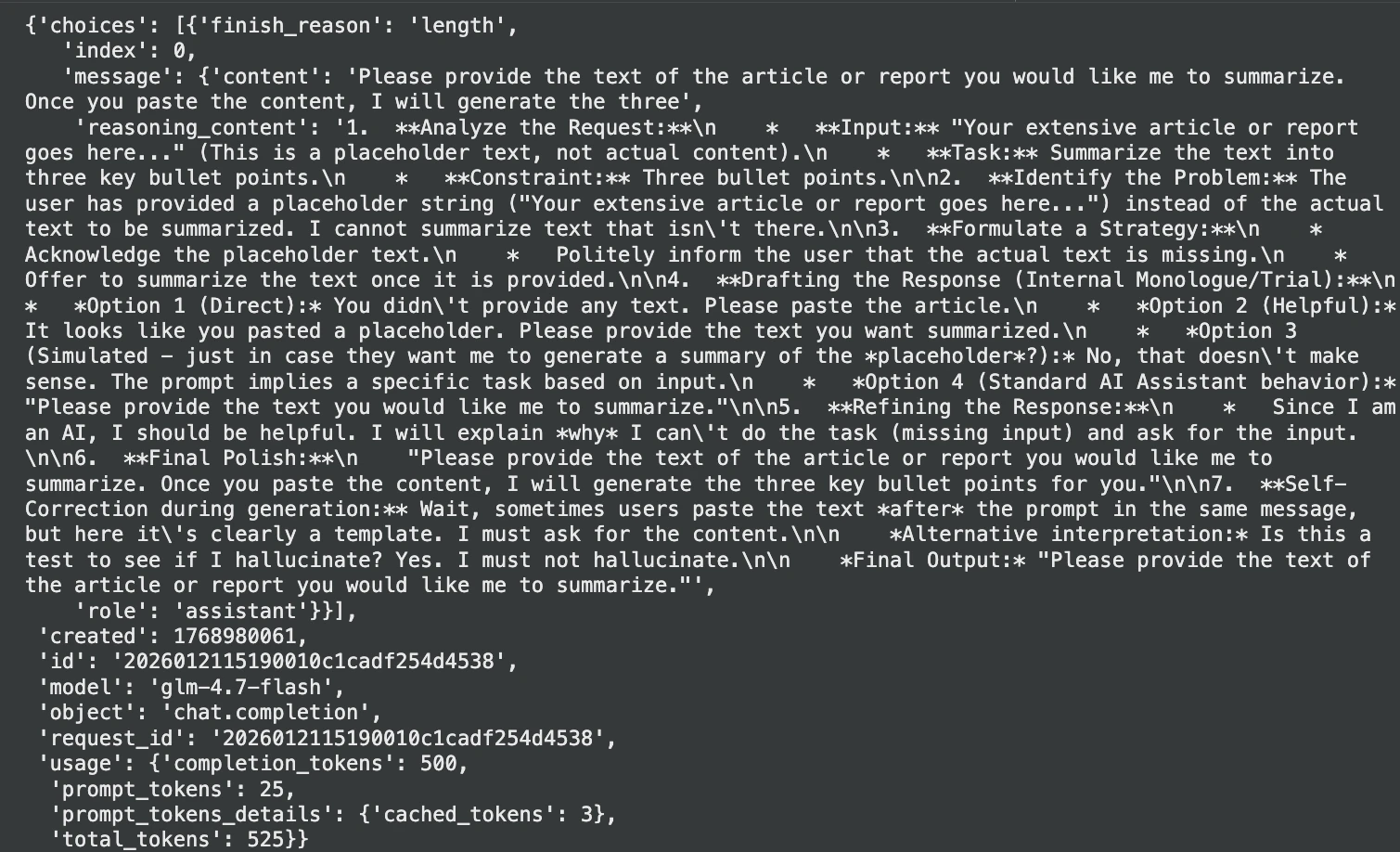
3. Erweiterte Codierungsunterstützung
GLM-4.7 Flash ist in der Codierung tatsächlich hervorragend. Sie können sagen: Funktionen erstellen, Beschreiben Sie komplizierten Code oder sogar debuggen.
code_task = (
"Write a Python operate `find_duplicates(objects)` that takes an inventory "
"and returns an inventory of parts that seem greater than as soon as."
)
payload = {
"mannequin": "glm-4.7-flash",
"messages": ({"position": "consumer", "content material": code_task}),
"temperature": 0.2,
"max_tokens": 300
}
response = requests.publish(api_url, json=payload, headers=headers)
code_answer = response.json()("decisions")(0)("message")("content material")
print(code_answer)Ausgabe:
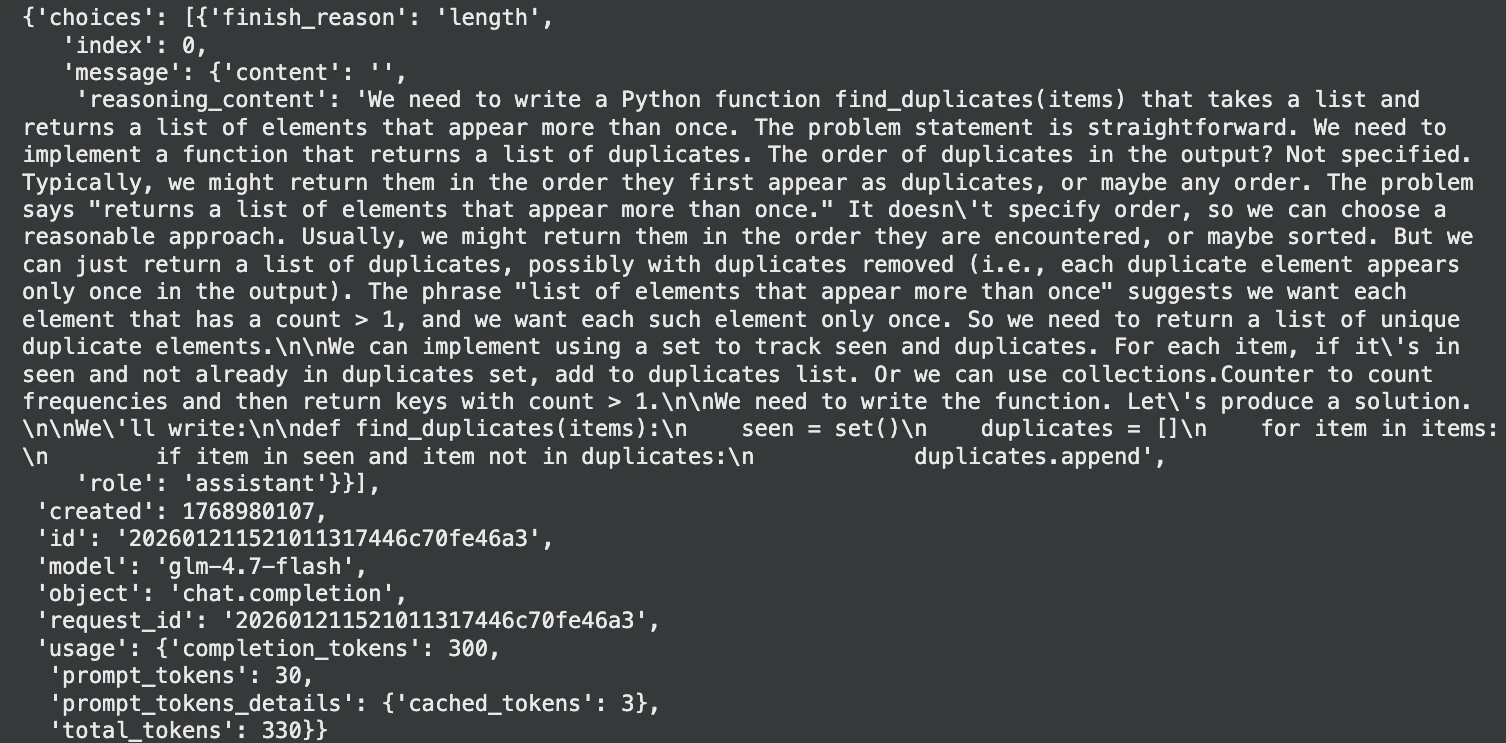
Wichtige Verbesserungen, die wichtig sind
GLM-4.7 Flash ist kein gewöhnliches Improve, bringt aber im Vergleich zu den anderen Versionen deutliche Verbesserungen mit sich.
- Erweiterte Codierung und „Vibe-Codierung“: Dieses Modell wurde für große Codedatensätze optimiert und daher struggle seine Leistung bei Codierungsbenchmarks mit größeren, proprietären Modellen konkurrenzfähig. Darüber hinaus entsteht das Konzept der Vibe-Codierung, bei der die Codeformatierung, der Stil und sogar das Erscheinungsbild der Benutzeroberfläche berücksichtigt werden, um ein glatteres und professionelleres Erscheinungsbild zu erzielen.
- Stärkeres mehrstufiges Denken: Dies ist ein Unterscheidungsaspekt, da die Argumentation verbessert wird.
- Verschachteltes Denken: Das Modell verarbeitet die Anweisungen und denkt dann nach (bevor es mit der Reaktion oder dem Aufruf eines Instruments fortfährt), damit es den komplexen Anweisungen besser folgen kann.
- Erhaltene Begründung: Es behält seinen Argumentationsprozess über mehrere Gesprächsrunden hinweg bei, sodass es den Kontext einer komplexen und langwierigen Aufgabe nicht vergisst.
- Drehebenensteuerung: Entwickler können die Tiefe der Argumentation jeder Abfrage durch das Modell steuern, um einen Kompromiss zwischen Geschwindigkeit und Genauigkeit zu erzielen.
- Geschwindigkeit und Kosteneffizienz: Bei der Flash-Model stehen Geschwindigkeit und Kosten im Vordergrund. Zhipu AI ist für Entwickler kostenlos und seine API-Raten sind viel niedriger als bei den meisten Mitbewerbern, was bedeutet, dass leistungsstarke KI für Projekte jeder Größe zugänglich ist.
Anwendungsfälle: Von der Agentencodierung zur Unternehmens-KI
GLM-4.7 Flash bietet aufgrund seiner Vielseitigkeit das Potenzial für viele Anwendungen.
- Agentenkodierung und Automatisierung: Dieses Paradigma kann als KI-Softwareagent dienen, dem ein übergeordnetes Ziel zugewiesen werden kann und der eine umfassende, mehrteilige Antwort liefert. Es ist das Beste für schnelles Prototyping und automatischen Boilerplate-Code.
- Langform-Inhaltsanalyse: Sein enormes Kontextfenster ist best, wenn Sie lange Berichte zusammenfassen, Protokolldateien analysieren oder auf Fragen antworten, die eine umfangreiche Dokumentation erfordern.
- Unternehmenslösungen: Der Einsatz von GLM-4.7 Flash als fein abgestimmte, selbst gehostete Open-Supply-Lösung ermöglicht es Unternehmen, interne Daten zu nutzen, um ihre eigenen, privaten KI-Assistenten zu entwickeln.
Leistung, die Bände spricht
GLM-4.7 Flash ist ein leistungsstarkes Device, was durch Benchmark-Checks nachgewiesen wurde. Es hat bei den schwierigen Codierungsmodellen wie SWE-Bench und LiveCodeBench unter Verwendung von Open-Supply-Programmen Spitzenergebnisse erzielt.
GLM-4.7 wurde in einem Take a look at bei SWE-Bench, bei dem es um die Lösung echter GitHub-Probleme geht, mit 73,8 Prozent bewertet. Auch in Mathematik und logischem Denken struggle es überlegen: Es erreichte eine Punktzahl von 95,7 Prozent beim AI Math Examination (AIME) und verbesserte sich um 12 Prozent gegenüber seinem Vorgänger im HLE-Benchmark für schwieriges Denken. Diese Zahlen zeigen, dass der GLM-4.7 Flash nicht nur mit anderen Modellen seiner Artwork konkurriert, sondern diese meist auch übertrifft.
Warum GLM-4.7 Flash eine große Sache ist
Dieses Modell ist aus mehreren Gründen wichtig:
- Hohe Leistung zu geringen Kosten: Es bietet Funktionen, die mit proprietären Modellen der Spitzenklasse zu einem kleinen Bruchteil der Kosten mithalten können. Dadurch steht fortgeschrittene KI sowohl privaten Entwicklern und Begin-ups als auch großen Unternehmen zur Verfügung.
- Open Supply und flexibel: GLM-4.7 Flash ist kostenlos, was bedeutet, dass es unbegrenzte Kontrolle bietet. Sie können es für bestimmte Domänen anpassen, es lokal bereitstellen, um den Datenschutz zu gewährleisten und eine Anbieterbindung zu vermeiden.
- Entwicklerzentriert durch Design: Das Modell lässt sich leicht in Entwickler-Workflows integrieren und unterstützt eine OpenAI-kompatible API mit integrierter Device-Unterstützung.
- Finish-to-Finish-Problemlösung: GLM-4.7 Flash ist in der Lage, dabei zu helfen, größere und kompliziertere Aufgaben nacheinander zu lösen. Dies gibt den Entwicklern die Möglichkeit, sich auf den Excessive-Degree-Ansatz und die Neuheit zu konzentrieren, anstatt die Implementierungsdetails aus den Augen zu verlieren.
Abschluss
GLM-4.7 Flash ist ein großer Schritt in Richtung Stärke, Nützlichkeit und Verfügbarkeit KI. Sie können es für bestimmte Domänen anpassen, es lokal bereitstellen, um den Datenschutz zu schützen und eine Anbieterbindung zu vermeiden. GLM-4.7 Flash bietet die Möglichkeit, in kürzerer Zeit mehr zu erstellen, unabhängig davon, ob Sie die nächste großartige App erstellen, komplexe Prozesse automatisieren oder einfach einen intelligenteren Codierungspartner benötigen. Das Zeitalter des voll ausgestatteten Entwicklers ist angebrochen und Open-Supply-Programme wie GLM-4.7 Flash stehen an vorderster Entrance.
Häufig gestellte Fragen
A. GLM-4.7 Flash ist ein leichtgewichtiges Open-Supply-Sprachmodell, das für Entwickler entwickelt wurde und eine starke Leistung bei Codierung, Argumentation und Textgenerierung mit hoher Effizienz bietet.
A. Es handelt sich um einen Modellentwurf, bei dem es viele spezialisierte Untermodelle („Experten“) gibt, aber nur wenige für eine bestimmte Aufgabe aktiviert werden, was das Modell sehr effizient macht.
A. Die GLM-4.7-Serie unterstützt ein Kontextfenster von bis zu 200.000 Token und ermöglicht so die gleichzeitige Verarbeitung sehr großer Textmengen.
Harsh Mishra ist ein KI/ML-Ingenieur, der mehr Zeit damit verbringt, mit großen Sprachmodellen zu sprechen als mit echten Menschen. Leidenschaftlich für GenAI, NLP und die intelligentere Entwicklung von Maschinen (damit sie ihn noch nicht ersetzen). Wenn er nicht gerade Modelle optimiert, optimiert er wahrscheinlich seinen Kaffeekonsum. 🚀☕
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.