

Spezialisierung notwendig
Ein Krankenhaus ist überfüllt mit Experten und Ärzten, von denen jeder seine eigenen Spezialgebiete hat und einzigartige Probleme löst. Chirurgen, Kardiologen, Kinderärzte – Experten aller Artwork arbeiten zusammen, um Patienten zu versorgen, und arbeiten oft zusammen, um ihnen die Versorgung zukommen zu lassen, die sie brauchen. Mit KI können wir dasselbe erreichen.
Die Combination of Specialists (MoE)-Architektur in der künstlichen Intelligenz wird als eine Mischung oder Mischung verschiedener „Experten“-Modelle definiert, die zusammenarbeiten, um komplexe Dateneingaben zu verarbeiten oder darauf zu reagieren. Wenn es um KI geht, ist jeder Experte in einem MoE-Modell auf ein viel größeres Downside spezialisiert – genau wie jeder Arzt auf sein medizinisches Fachgebiet spezialisiert ist. Dies verbessert die Effizienz und erhöht die Wirksamkeit und Genauigkeit des Methods.
Mistral AI liefert Open-Supply-LLMs, die mit denen von OpenAI konkurrieren. Sie haben offiziell die Verwendung einer MoE-Architektur in ihrem Mixtral 8x7B-Modell diskutiert, ein revolutionärer Durchbruch in Type eines hochmodernen Massive Language Mannequin (LLM). Wir werden uns eingehend damit befassen, warum Mixtral von Mistral AI sich von anderen LLMs abhebt und warum aktuelle LLMs jetzt die MoE-Architektur verwenden, wobei ihre Geschwindigkeit, Größe und Genauigkeit im Vordergrund stehen.
Gängige Methoden zum Improve großer Sprachmodelle (LLMs)
Um besser zu verstehen, wie die MoE-Architektur unsere LLMs verbessert, besprechen wir gängige Methoden zur Verbesserung der LLM-Effizienz. KI-Praktiker und -Entwickler verbessern Modelle, indem sie Parameter erhöhen, die Architektur anpassen oder Feinabstimmungen vornehmen.
- Zunehmende Parameter: Durch die Eingabe weiterer Informationen und deren Interpretation erhöht sich die Fähigkeit des Modells, komplexe Muster zu lernen und darzustellen. Dies kann jedoch zu Überanpassung und Halluzinationen führen, sodass ein umfangreiches Reinforcement Studying from Human Suggestions (RLHF) erforderlich ist.
- Architektur optimieren: Durch die Einführung neuer Schichten oder Module wird die steigende Anzahl an Parametern berücksichtigt und die Leistung bei bestimmten Aufgaben verbessert. Änderungen an der zugrunde liegenden Architektur sind jedoch schwierig umzusetzen.
- Feinabstimmung: Vorab trainierte Modelle können anhand spezifischer Daten oder durch Transferlernen optimiert werden, sodass vorhandene LLMs neue Aufgaben oder Domänen bewältigen können, ohne von vorne beginnen zu müssen. Dies ist die einfachste Methode und erfordert keine wesentlichen Änderungen am Modell.
Was ist die MoE-Architektur?
Die Combination of Specialists (MoE)-Architektur ist ein neuronales Netzwerkdesign, das die Effizienz und Leistung verbessert, indem es für jeden Enter dynamisch eine Teilmenge spezialisierter Netzwerke, sogenannte Experten, aktiviert. Ein Gating-Netzwerk bestimmt, welche Experten aktiviert werden sollen, was zu einer spärlichen Aktivierung und einem geringeren Rechenaufwand führt. Die MoE-Architektur besteht aus zwei kritischen Komponenten: dem Gating-Netzwerk und den Experten. Lassen Sie uns das im Element aufschlüsseln:
Im Kern funktioniert die MoE-Architektur wie ein effizientes Verkehrssystem, das jedes Fahrzeug – oder in diesem Fall die Daten – auf die beste Route leitet, basierend auf Echtzeitbedingungen und dem gewünschten Ziel. Jede Aufgabe wird an den am besten geeigneten Experten oder das am besten geeignete Untermodell weitergeleitet, das auf die Bearbeitung dieser bestimmten Aufgabe spezialisiert ist. Diese dynamische Weiterleitung stellt sicher, dass für jede Aufgabe die fähigsten Ressourcen eingesetzt werden, was die Gesamteffizienz und Effektivität des Modells verbessert. Die MoE-Architektur nutzt alle drei Möglichkeiten zur Verbesserung der Modelltreue.
- Durch die Implementierung mehrerer Experten erhöht das MoE von Natur aus die
- Parametergröße durch Hinzufügen weiterer Parameter professional Experte.
- MoE verändert die klassische neuronale Netzwerkarchitektur, die ein Gated Community einbezieht, um zu bestimmen, welche Experten für eine bestimmte Aufgabe eingesetzt werden sollen.
- Jedes KI-Modell verfügt über ein gewisses Maß an Feinabstimmung. Daher wird jeder Experte in einem MoE so feinabgestimmt, dass er die beabsichtigte Leistung erbringt und so eine zusätzliche Abstimmungsebene schafft, die herkömmliche Modelle nicht nutzen können.
MoE-Gating-Netzwerk
Das Gating-Netzwerk fungiert als Entscheidungsträger oder Controller innerhalb des MoE-Modells. Es bewertet eingehende Aufgaben und bestimmt, welcher Experte für deren Bearbeitung geeignet ist. Diese Entscheidung basiert in der Regel auf erlernten Gewichtungen, die im Laufe der Zeit durch Coaching angepasst werden, wodurch die Fähigkeit, Aufgaben Experten zuzuordnen, weiter verbessert wird. Das Gating-Netzwerk kann verschiedene Strategien anwenden, von probabilistischen Methoden, bei denen mehrere Experten mit Tender-Aufgaben betraut werden, bis hin zu deterministischen Methoden, bei denen jede Aufgabe an einen einzelnen Experten weitergeleitet wird.
MoE-Experten
Jeder Experte im MoE-Modell stellt ein kleineres neuronales Netzwerk, ein maschinelles Lernmodell oder ein LLM dar, das für eine bestimmte Teilmenge des Problembereichs optimiert ist. In Mistral beispielsweise können sich verschiedene Experten auf das Verstehen bestimmter Sprachen, Dialekte oder sogar Abfragetypen spezialisieren. Die Spezialisierung stellt sicher, dass jeder Experte in seiner Nische kompetent ist, was in Kombination mit den Beiträgen anderer Experten zu einer überlegenen Leistung bei einer Vielzahl von Aufgaben führt.
MoE-Verlustfunktion
Obwohl sie nicht als Hauptkomponente der MoE-Architektur gilt, spielt die Verlustfunktion eine entscheidende Rolle für die zukünftige Leistung des Modells, da sie darauf ausgelegt ist, sowohl die einzelnen Experten als auch das Gating-Netzwerk zu optimieren.
Dabei werden in der Regel die für jeden Experten berechneten Verluste kombiniert, die nach der ihnen vom Gating-Netzwerk zugewiesenen Wahrscheinlichkeit oder Bedeutung gewichtet werden. Dies hilft dabei, die Experten für ihre spezifischen Aufgaben zu optimieren und gleichzeitig das Gating-Netzwerk anzupassen, um die Routing-Genauigkeit zu verbessern.
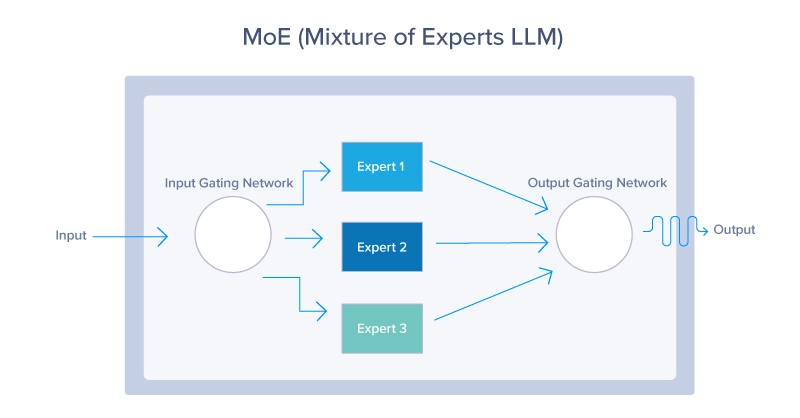
Der MoE-Prozess von Anfang bis Ende
Lassen Sie uns nun den gesamten Prozess zusammenfassen und weitere Particulars hinzufügen.
Hier finden Sie eine zusammengefasste Erklärung, wie der Routing-Prozess von Anfang bis Ende funktioniert:
- Eingabeverarbeitung: Erste Verarbeitung der eingehenden Daten. Bei LLMs vor allem unser Immediate.
- Merkmalsextraktion: Umwandlung von Roheingaben für die Analyse.
- Gating Community Analysis: Beurteilung der Experteneignung anhand von Wahrscheinlichkeiten oder Gewichten.
- Gewichtetes Routing: Zuweisung der Eingaben auf Grundlage berechneter Gewichte. Hier wird der Prozess der Auswahl des am besten geeigneten LLM abgeschlossen. In einigen Fällen werden mehrere LLMs ausgewählt, um eine einzelne Eingabe zu beantworten.
- Aufgabenausführung: Verarbeitung der zugewiesenen Eingaben durch jeden Experten.
- Integration von Expertenergebnissen: Kombinieren einzelner Expertenergebnisse für die endgültige Ausgabe.
- Suggestions und Anpassung: Leistungsfeedback zur Verbesserung von Modellen nutzen.
- Iterative Optimierung: Kontinuierliche Verfeinerung der Routenführung und der Modellparameter.
Beliebte Modelle, die eine MoE-Architektur verwenden
- GPT-4 und GPT-4o von OpenAI: GPT-4 und GPT4o bilden die Grundlage für die Premium-Model von ChatGPT. Diese multimodalen Modelle nutzen MoE, um verschiedene Quellmedien wie Bilder, Textual content und Sprache verarbeiten zu können. Gerüchten zufolge und auch leicht bestätigt, verfügt GPT-4 über 8 Experten mit jeweils 220 Milliarden Parametern, was das gesamte Modell auf über 1,7 Billionen Parameter bringt.
- Mixtral 8x7b von Mistral AI: Mistral AI liefert sehr leistungsstarke KI-Modelle als Open Supply und hat erklärt, dass ihr Mixtral-Modell ein sMoE-Modell oder ein spärliches Combination of Specialists-Modell ist, das in einem kleinen Paket geliefert wird. Mixtral 8x7b hat insgesamt 46,7 Milliarden Parameter, verwendet aber nur 12,9 Milliarden Parameter professional Token und verarbeitet daher Ein- und Ausgaben zu diesen Kosten. Ihr MoE-Modell übertrifft Llama2 (70 Milliarden) und GPT-3.5 (175 Milliarden) durchweg und ist dabei kostengünstiger.
Die Vorteile von MoE und warum es die bevorzugte Architektur ist
Das Hauptziel der MoE-Architektur besteht letztlich darin, einen Paradigmenwechsel in der Herangehensweise an komplexe Aufgaben des maschinellen Lernens herbeizuführen. Sie bietet einzigartige Vorteile und zeigt ihre Überlegenheit gegenüber herkömmlichen Modellen in mehrfacher Hinsicht.
- Verbesserte Modellskalierbarkeit
- Jeder Experte ist für einen Teil einer Aufgabe verantwortlich. Eine Skalierung durch Hinzufügen weiterer Experten führt daher nicht zu einer proportionalen Erhöhung des Rechenleistungsbedarfs.
- Dieser modulare Ansatz kann größere und vielfältigere Datensätze verarbeiten und erleichtert die parallele Verarbeitung, wodurch die Abläufe beschleunigt werden. Wenn Sie beispielsweise einem textbasierten Modell ein Bilderkennungsmodell hinzufügen, können Sie einen zusätzlichen LLM-Experten für die Interpretation von Bildern integrieren und gleichzeitig weiterhin Textual content ausgeben. Oder
- Durch die Vielseitigkeit kann das Modell seine Fähigkeiten auf verschiedene Arten von Dateneingaben erweitern.
- Verbesserte Effizienz und Flexibilität
- MoE-Modelle sind äußerst effizient und binden im Gegensatz zu herkömmlichen Architekturen, die alle Parameter unabhängig davon verwenden, selektiv nur die erforderlichen Experten für bestimmte Eingaben ein.
- Die Architektur reduziert den Rechenaufwand professional Inferenz und ermöglicht es dem Modell, sich an unterschiedliche Datentypen und spezielle Aufgaben anzupassen.
- Spezialisierung und Genauigkeit:
- Jeder Experte in einem MoE-System kann auf bestimmte Aspekte des Gesamtproblems abgestimmt werden, was zu größerer Experience und Genauigkeit in diesen Bereichen führt
- Eine solche Spezialisierung ist in Bereichen wie der medizinischen Bildgebung oder der Finanzprognose hilfreich, wo Präzision der Schlüssel ist.
- MoE kann aufgrund seines differenzierten Verständnisses, seines detaillierten Wissens und der Fähigkeit, generalistische Modelle bei speziellen Aufgaben zu übertreffen, in engen Domänen bessere Ergebnisse erzielen.
Die Nachteile der MoE-Architektur
Zwar bietet die MoE-Architektur erhebliche Vorteile, doch bringt sie auch Herausforderungen mit sich, die ihre Akzeptanz und Wirksamkeit beeinträchtigen können.
- Modellkomplexität: Die Verwaltung mehrerer Experten für neuronale Netzwerke und eines Gating-Netzwerks zur Verkehrslenkung erschwert die Entwicklung und die Betriebskosten des MoE
- Trainingsstabilität: Durch die Interaktion zwischen dem Gating-Netzwerk und den Experten kommt es zu unvorhersehbaren Dynamiken, die das Erreichen gleichmäßiger Lernraten behindern und eine umfassende Feinabstimmung der Hyperparameter erfordern.
- Ungleichgewicht: Experten ungenutzt zu lassen, ist eine schlechte Optimierung für das MoE-Modell. Es werden Ressourcen für Experten verschwendet, die nicht gebraucht werden, oder man verlässt sich zu sehr auf bestimmte Experten. Für eine leistungsstarke MoE-KI ist es entscheidend, die Arbeitslast auszugleichen und ein effektives Gate zu optimieren.
Es ist zu beachten, dass die oben genannten Nachteile im Allgemeinen mit der Zeit abnehmen, wenn die MoE-Architektur verbessert wird.
Spezialisierung prägt die Zukunft
Wenn wir über den MoE-Ansatz und seine menschliche Parallele nachdenken, sehen wir, dass spezialisierte Groups mehr erreichen als eine allgemeine Belegschaft. Und spezialisierte Modelle übertreffen ihre monolithischen Gegenstücke in KI-Modellen. Durch die Priorisierung von Vielfalt und Fachwissen wird die Komplexität großer Probleme in überschaubare Segmente aufgeteilt, die Experten effektiv bewältigen können.
Wenn wir in die Zukunft blicken, sollten wir die umfassenderen Auswirkungen spezialisierter Systeme auf die Weiterentwicklung anderer Technologien berücksichtigen. Die Grundsätze des MoE könnten Entwicklungen in Sektoren wie Gesundheitswesen, Finanzen und autonome Systeme beeinflussen und effizientere und präzisere Lösungen fördern.
Die Reise des MoE hat gerade erst begonnen, und seine weitere Entwicklung verspricht weitere Innovationen im Bereich der KI und darüber hinaus. Da sich Hochleistungshardware immer weiter entwickelt, kann diese Mischung aus Experten-KIs in unseren Smartphones untergebracht werden und noch intelligentere Erfahrungen liefern. Aber zuerst muss jemand eine dieser KIs ausbilden.
Kevin Vu verwaltet Weblog von Exxact Corp und arbeitet mit vielen seiner talentierten Autoren zusammen, die über verschiedene Aspekte des Deep Studying schreiben.