Neulich diskutierten wir das „Fail Quick“-Prinzip in der statistischen Modellierung und Berechnung.
Laut Wikipedia stammt der Begriff „Fail Quick“ aus ein Artikel von Jim Grey„Warum bleiben Laptop stehen und was kann man dagegen tun?“, veröffentlicht im Juni 1985 als Tandem Technical Report 85.7. Tandem conflict ein Unternehmen, das fehlertolerante Laptop herstellte – ich glaube, der Title „Tandem“ bezog sich auf die Idee, zwei verfügbare Prozessoren zu haben, sodass, wenn einer kaputtging, der andere verfügbar conflict.
Mit den Worten von Grey:
Der prozessorientierte Ansatz zur Fehlerisolierung sieht vor, dass das Prozesssoftwaremodul ausfallsicher ist. Es sollte entweder ordnungsgemäß funktionieren oder den Fehler erkennen, den Ausfall melden und den Betrieb einstellen.
Er führt aus:
Zuverlässigkeit und Verfügbarkeit sind zwei verschiedene Dinge: Verfügbarkeit bedeutet, das Richtige innerhalb der angegebenen Reaktionszeit zu tun. Zuverlässigkeit bedeutet nicht, das Falsche zu tun.
Die erwartete Zuverlässigkeit ist proportional zur mittleren Betriebsdauer zwischen Ausfällen (MBF). Ein Ausfall hat eine gewisse mittlere Reparaturdauer (MTTR). … Modularität und Redundanz ermöglichen den Ausfall eines Moduls des Programs, ohne die Verfügbarkeit des gesamten Programs zu beeinträchtigen, da Redundanz zu einer geringen MTTR führt. Diese Kombination aus Modularität und Redundanz ist der Schlüssel zur Bereitstellung eines kontinuierlichen Dienstes, selbst wenn einige Komponenten ausfallen.
Und etwas amüsante Geschichte:
Von Neumann conflict der erste, der den Einsatz von Redundanz analytisch untersuchte, um verfügbare (hochzuverlässige) Systeme aus unzuverlässigen Komponenten zu konstruieren. In seinem Modell conflict eine Redundanz von 20.000 erforderlich, um eine MTBF des Programs von 100 Jahren zu erreichen. Natürlich waren seine Komponenten weniger zuverlässig als Transistoren; er dachte dabei an menschliche Neuronen oder Vakuumröhren. Dennoch ist nicht klar, warum von Neumanns Maschinen
erforderte einen Redundanzfaktor von 20.000, während aktuelle elektronische Systeme einen Faktor von 2 verwenden, um eine sehr hohe Verfügbarkeit zu erreichen. Der Hauptunterschied besteht darin, dass von Neumanns Modell die Modularität fehlte; ein Ausfall in einem beliebigen Kabelbündel an irgendeiner Stelle bedeutete einen Totalausfall des Programs.Von Neumanns Modell hatte Redundanz ohne Modularität. Moderne Computersysteme sind dagegen modular aufgebaut – ein Fehler in einem Modul wirkt sich nur auf dieses Modul aus. Darüber hinaus ist jedes Modul so aufgebaut, dass es schnell ausfällt – das Modul funktioniert entweder richtig oder es stoppt. Die Kombination von Redundanz mit Modularität ermöglicht es, eine Redundanz von zwei statt 20.000 zu verwenden. Eine ziemliche Einsparung!
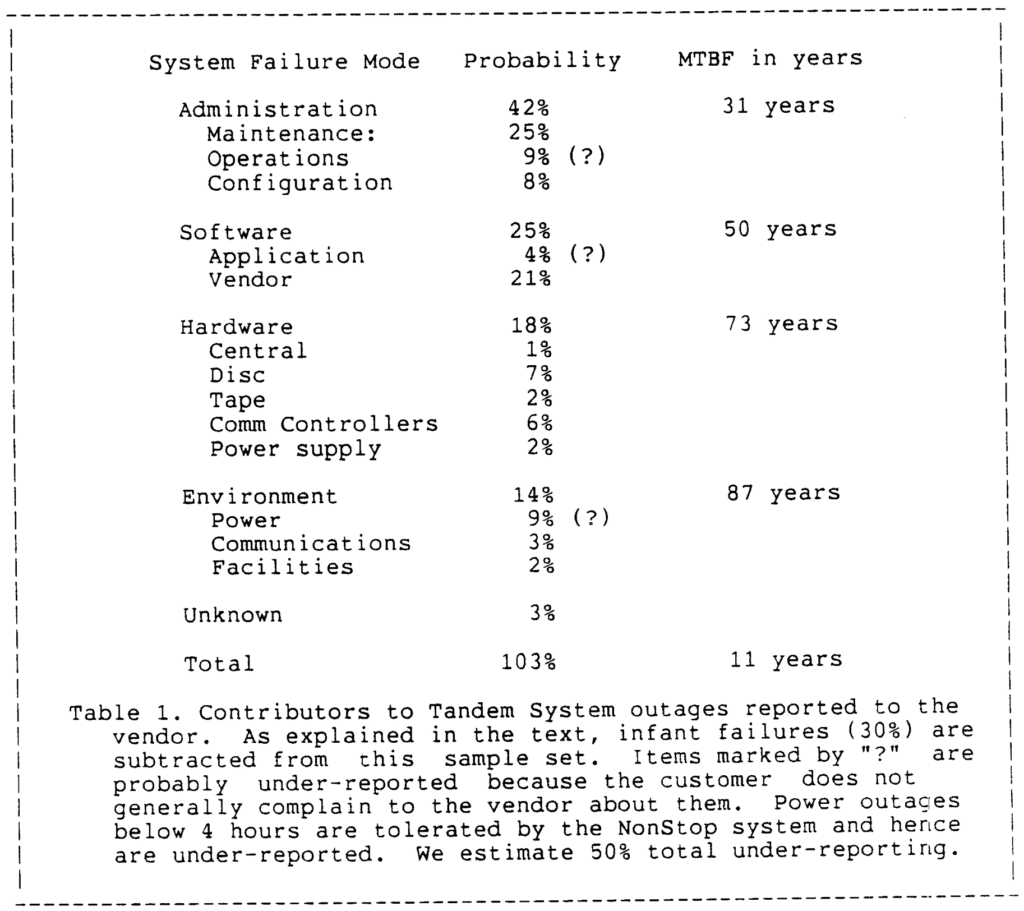
Der ganze Artikel ist lesenswert. Er erfüllt mich mit Nostalgie: die Schreibmaschinenschrift, der sorgfältige Schreibstil, die Argumentation der Größenordnung, die Offenheit in Bezug auf Unsicherheit, die Vertrautheit mit der Physik, der ganze unsinnige Quantität von allem, die Jungs-in-kurzärmeligen-Hemden-mit-Taschenschutz-Stimmung … Hier ist ein Beispiel:
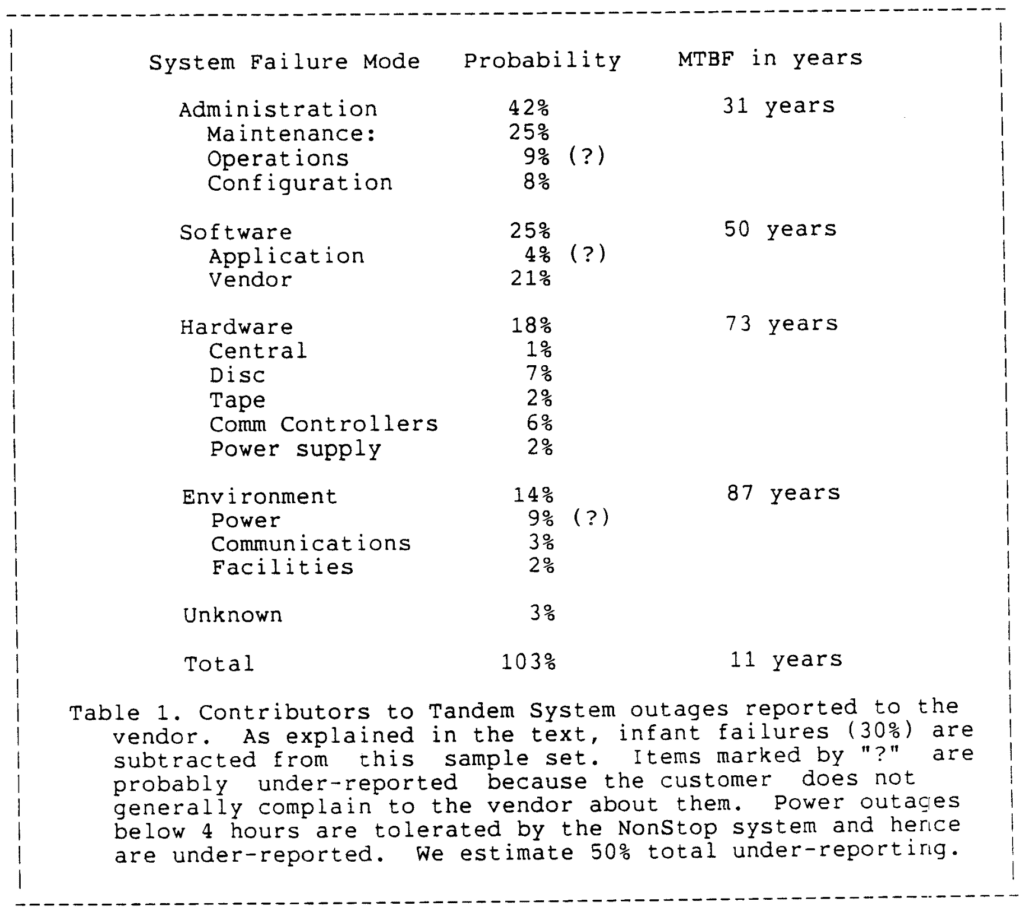
Hier ist ein weiterer Ausschnitt:
Die Behauptung, dass die meisten Produktionssoftwarefehler weich sind – Heisenbugs, die verschwinden, wenn man sie ansieht – ist Systemprogrammierern wohlbekannt. Bohrbugs sind wie das Bohr-Atom fest, mit Standardtechniken leicht zu erkennen und daher langweilig. Heisenbugs können sich jedoch jahrelang einem Bugcatcher entziehen. Tatsächlich kann der Bugcatcher die State of affairs gerade genug stören, um den Heisenbug verschwinden zu lassen.
Dies ist analog zum Heisenbergschen Unschärfeprinzip in der Physik. Ich habe versucht, die Wahrscheinlichkeit zu quantifizieren, dass ein Heisenbug durch erneute Ausführung toleriert wird. Dies ist schwierig. Eine Umfrage ergibt nichts Quantitatives. Das eine Experiment, das ich durchgeführt habe, verlief folgendermaßen: Das Spooler-Fehlerprotokoll mehrerer Dutzend Systeme wurde untersucht. Der Spooler ist als eine Sammlung von Fail-Quick-Prozessen aufgebaut. Wenn einer der Prozesse einen Fehler erkennt, stoppt er und lässt seinen Bruder den Vorgang fortsetzen. Der Bruder führt einen Software program-Neuversuch aus. Wenn auch der Bruder fehlschlägt, handelt es sich bei dem Fehler um einen Bohrbug und nicht um einen Heisenbug. Im gemessenen Zeitraum conflict einer von 132 Softwarefehlern ein Bohrbug, der Relaxation waren Heisenbugs.
Und hier ist ein Hyperlink zum zitierten Artikel von Neumann, „Probabilistic logics and the synthesis of dependable organisms“, ursprünglich aus dem Jahr 1952. Gutes Zeug.