
Bild vom Herausgeber | Midjourney
Dieses Tutorial zeigt, wie Sie mit der Datasets-Bibliothek von Hugging Face mit nur wenigen Codezeilen Datasets aus verschiedenen Quellen laden können.
Die Hugging Face Datasets-Bibliothek vereinfacht das Laden und Verarbeiten von Datensätzen. Sie bietet eine einheitliche Schnittstelle für Tausende von Datensätzen auf dem Hugging Face-Hub. Die Bibliothek implementiert außerdem verschiedene Leistungsmetriken für die transformerbasierte Modellbewertung.
Ersteinrichtung
In bestimmten Python-Entwicklungsumgebungen muss die Datasets-Bibliothek möglicherweise vor dem Import installiert werden.
!pip set up datasets
import datasetsLaden eines Hugging Face Hub-Datensatzes nach Namen
Hugging Face hostet in seinem Hub eine Fülle von Datensätzen. Die folgende Funktion gibt eine Liste dieser Datensätze nach Namen aus:
from datasets import list_datasets
list_datasets()Laden wir einen davon, nämlich den Emotionen-Datensatz zum Klassifizieren von Emotionen in Tweets durch Angabe des Namens:
knowledge = load_dataset("jeffnyman/feelings")Wenn Sie einen Datensatz laden möchten, auf den Sie beim Durchsuchen der Web site von Hugging Face gestoßen sind, und sich über die richtige Namenskonvention nicht sicher sind, klicken Sie auf das Image „Kopieren“ neben dem Datensatznamen, wie unten gezeigt:

Der Datensatz wird geladen in eine DatasetDict Objekt, das drei Teilmengen oder Falten enthält: Trainieren, Validieren und Testen.
DatasetDict({
practice: Dataset({
options: ('textual content', 'label'),
num_rows: 16000
})
validation: Dataset({
options: ('textual content', 'label'),
num_rows: 2000
})
take a look at: Dataset({
options: ('textual content', 'label'),
num_rows: 2000
})
})Jede Falte ist wiederum eine Datensatz Objekt. Mithilfe von Wörterbuchoperationen können wir die Trainingsdatenfalte abrufen:
train_data = all_data("practice")Die Länge dieses Dataset-Objekts gibt die Anzahl der Trainingsinstanzen (Tweets) an.
Dies führt zu dieser Ausgabe:
Das Abrufen einer einzelnen Instanz per Index (z. B. der vierten) ist so einfach wie das Nachahmen einer Listenoperation:
Das Ergebnis ist ein Python-Wörterbuch mit den beiden Attributen im Datensatz, die als Schlüssel fungieren: der eingegebene Tweet Textual contentund das Etikett gibt die Emotion an, mit der es klassifiziert wurde.
{'textual content': 'i'm ever feeling nostalgic in regards to the fire i'll know that it's nonetheless on the property',
'label': 2}Wir können auch mehrere aufeinanderfolgende Instanzen gleichzeitig erhalten, indem wir sie aufteilen:
Dieser Vorgang gibt wie zuvor ein einzelnes Wörterbuch zurück, aber jetzt ist jedem Schlüssel eine Werteliste statt eines einzelnen Werts zugeordnet.
{'textual content': ('i didnt really feel humiliated', ...),
'label': (0, ...)}Um zuletzt auf einen einzelnen Attributwert zuzugreifen, geben wir zwei Indizes an: einen für seine Place und einen für den Attributnamen oder Schlüssel:
Laden eigener Daten
Wenn Sie statt auf den Hugging Face-Dataset-Hub Ihren eigenen Datensatz verwenden möchten, können Sie dies auch mit der Datasets-Bibliothek tun. Verwenden Sie dazu die gleiche Funktion „load_dataset()“ mit zwei Argumenten: dem Dateiformat des zu ladenden Datensatzes (z. B. „csv“, „textual content“ oder „json“) und dem Pfad oder der URL, in der/denen er sich befindet.
Dieses Beispiel lädt den Datensatz „Palmer-Archipel-Pinguine“ aus einem öffentlichen GitHub-Repository:
url = "https://uncooked.githubusercontent.com/allisonhorst/palmerpenguins/grasp/inst/extdata/penguins.csv"
dataset = load_dataset('csv', data_files=url)Datensatz in Pandas DataFrame umwandeln
Zu guter Letzt ist es manchmal praktisch, die geladenen Daten in ein Pandas zu konvertieren. Datenrahmen Objekt, das die Datenmanipulation, -analyse und -visualisierung mit der umfangreichen Funktionalität der Pandas-Bibliothek erleichtert.
penguins = dataset("practice").to_pandas()
penguins.head()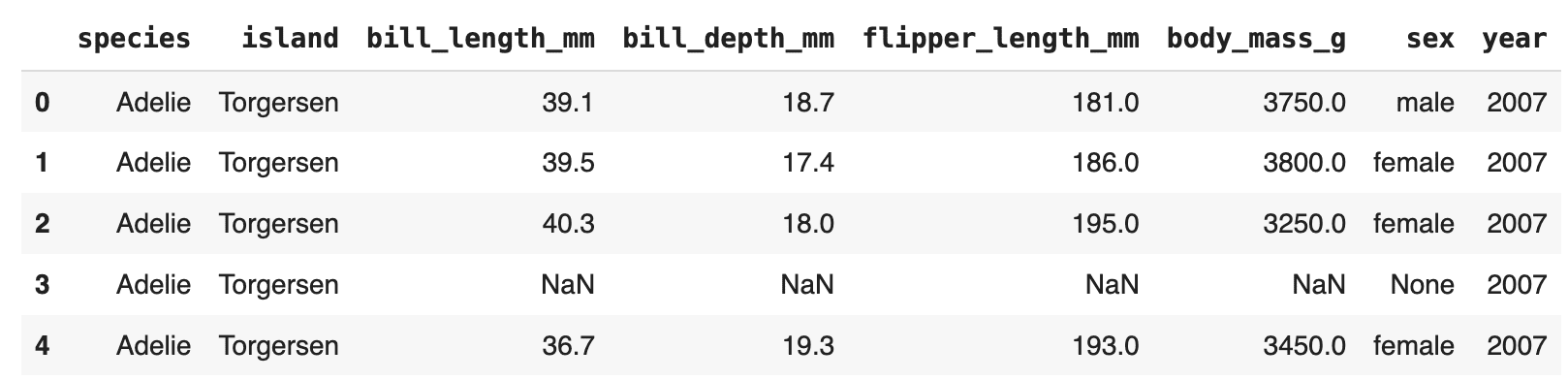
Nachdem Sie nun gelernt haben, wie Sie mit der speziellen Bibliothek von Hugging Face effizient Datensätze laden, besteht der nächste Schritt darin, diese mithilfe von Massive Language Fashions (LLMs) zu nutzen.
Iván Palomares Carrascosa ist ein führender Experte, Autor, Redner und Berater in den Bereichen KI, maschinelles Lernen, Deep Studying und LLMs. Er schult und leitet andere bei der Nutzung von KI in der realen Welt an.