

Bild vom Autor | DALLE-3 & Canva
Fehlende Werte in realen Datensätzen sind ein häufiges Downside. Dies kann aus verschiedenen Gründen auftreten, z. B. aufgrund verpasster Beobachtungen, Datenübertragungsfehler, Sensorstörungen usw. Wir können sie nicht einfach ignorieren, da sie die Ergebnisse unserer Modelle verfälschen können. Wir müssen sie aus unserer Analyse entfernen oder verarbeiten, damit unser Datensatz vollständig ist. Das Entfernen dieser Werte führt zu Informationsverlust, was wir nicht wollen. Daher haben Wissenschaftler verschiedene Möglichkeiten entwickelt, mit diesen fehlenden Werten umzugehen, z. B. Imputation und Interpolation. Diese beiden Techniken werden häufig verwechselt. Imputation ist ein geläufigerer Begriff, der Anfängern geläufiger ist. Bevor wir fortfahren, möchte ich eine klare Grenze zwischen diesen beiden Techniken ziehen.
Bei der Imputation werden die fehlenden Werte im Grunde mit statistischen Maßen wie Mittelwert, Median oder Modus aufgefüllt. Das ist ziemlich einfach, berücksichtigt aber nicht den Pattern des Datensatzes. Bei der Interpolation wird der Wert fehlender Werte jedoch anhand der umgebenden Traits und Muster geschätzt. Dieser Ansatz ist praktikabler, wenn Ihre fehlenden Werte nicht zu stark gestreut sind.
Nachdem wir nun den Unterschied zwischen diesen Techniken kennen, besprechen wir einige der in Pandas verfügbaren Interpolationsmethoden. Anschließend führe ich Sie durch ein Beispiel. Danach gebe ich Ihnen einige Tipps, die Ihnen bei der Auswahl der richtigen Interpolationstechnik helfen.
Arten von Interpolationsmethoden in Pandas
Pandas bietet verschiedene Interpolationsmethoden (‚linear‘, ‚Zeit‘, ‚Index‘, ‚Werte‘, ‚Pad‘, ’nächste‘, ‚Null‘, ’slinear‘, ‚quadratisch‘, ‚kubisch‘, ‚baryzentrisch‘, ‚krogh‘, ‚Polynom‘, ‚Spline‘, ’stückweises Polynom‘, ‚aus_Ableitungen‘, ‚pchip‘, ‚akima‘, ‚cubicspline‘) auf die Sie zugreifen können über interpolate() Funktion. Die Syntax dieser Methode lautet wie folgt:
DataFrame.interpolate(methodology='linear', **kwargs, axis=0, restrict=None, inplace=False, limit_direction=None, limit_area=None, downcast=_NoDefault.no_default, **kwargs)Ich weiß, das sind eine Menge Methoden, und ich möchte Sie nicht überfordern. Daher werden wir einige der am häufigsten verwendeten Methoden besprechen:
- Lineare Interpolation: Dies ist die Standardmethode, die rechnerisch schnell und einfach ist. Sie verbindet die bekannten Datenpunkte durch Zeichnen einer geraden Linie und diese Linie wird verwendet, um die fehlenden Werte zu schätzen.
- Zeitinterpolation: Die zeitbasierte Interpolation ist nützlich, wenn Ihre Daten nicht gleichmäßig verteilt sind, sondern linear über die Zeit verteilt sind. Dazu muss Ihr Index ein Datums-/Uhrzeitindex sein, und er füllt die fehlenden Werte aus, indem er die Zeitintervalle zwischen den Datenpunkten berücksichtigt.
- Index-Interpolation: Dies ähnelt der Zeitinterpolation, bei der der Indexwert zur Berechnung der fehlenden Werte verwendet wird. Allerdings muss es sich hier nicht um einen Datums-/Uhrzeitindex handeln, sondern um aussagekräftige Informationen wie Temperatur, Entfernung usw.
- Pad (Ahead Fill) und Backward Fill Methode: Dies bezieht sich auf das Kopieren des bereits vorhandenen Wertes, um den fehlenden Wert auszufüllen. Wenn die Ausbreitungsrichtung vorwärts ist, wird die letzte gültige Beobachtung vorwärts ausgefüllt. Wenn sie rückwärts ist, wird die nächste gültige Beobachtung verwendet.
- Nächste Interpolation: Wie der Title schon sagt, werden die lokalen Variationen in den Daten zum Ausfüllen der Werte verwendet. Der Wert, der dem fehlenden am nächsten liegt, wird zum Ausfüllen verwendet.
- Polynom-Interpolation: Wir wissen, dass reale Datensätze größtenteils nichtlinear sind. Daher passt diese Funktion eine Polynomfunktion an die Datenpunkte an, um den fehlenden Wert zu schätzen. Sie müssen hierfür auch die Reihenfolge angeben (z. B. Ordnung = 2 für quadratisch).
- Spline-Interpolation: Lassen Sie sich nicht von dem komplexen Namen abschrecken. Eine Spline-Kurve wird mithilfe stückweiser Polynomfunktionen gebildet, um die Datenpunkte zu verbinden, was zu einer endgültigen glatten Kurve führt. Sie werden feststellen, dass die Interpolationsfunktion auch
piecewise_polynomialals separate Methode. Der Unterschied zwischen beiden besteht darin, dass letztere keine Kontinuität der Ableitungen an den Grenzen gewährleistet, was bedeutet, dass sie abruptere Änderungen zulassen kann.
Genug der Theorie; sehen wir uns anhand des Datensatzes „Airline Passengers“, der monatliche Passagierdaten von 1949 bis 1960 enthält, an, wie die Interpolation funktioniert.
Code-Implementierung: Datensatz zu Flugpassagieren
Wir werden einige fehlende Werte in den Datensatz der Fluggäste einführen und diese dann mit einer der oben genannten Techniken interpolieren.
Schritt 1: Importieren und Laden des Datensatzes
Importieren Sie die Basisbibliotheken wie unten beschrieben und laden Sie die CSV-Datei dieses Datensatzes in einen DataFrame mit dem pd.read_csv Funktion.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Load the dataset
url = "https://uncooked.githubusercontent.com/jbrownlee/Datasets/grasp/airline-passengers.csv"
df = pd.read_csv(url, index_col="Month", parse_dates=('Month'))parse_dates konvertiert die Spalte ‚Monat‘ in eine datetime Objekt und index_col legt es als Index des DataFrame fest.
Schritt 2: Fehlende Werte einführen
Nun wählen wir nach dem Zufallsprinzip 15 verschiedene Instanzen aus und markieren die Spalte „Passagiere“ als np.nandie die fehlenden Werte darstellen.
# Introduce lacking values
np.random.seed(0)
missing_idx = np.random.alternative(df.index, dimension=15, exchange=False)
df.loc(missing_idx, 'Passengers') = np.nanSchritt 3: Daten mit fehlenden Werten darstellen
Wir werden Matplotlib verwenden, um zu visualisieren, wie unsere Daten nach der Einführung von 15 fehlenden Werten aussehen.
# Plot the info with lacking values
plt.determine(figsize=(10,6))
plt.plot(df.index, df('Passengers'), label="Authentic Knowledge", linestyle="-", marker="o")
plt.legend()
plt.title('Airline Passengers with Lacking Values')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.present()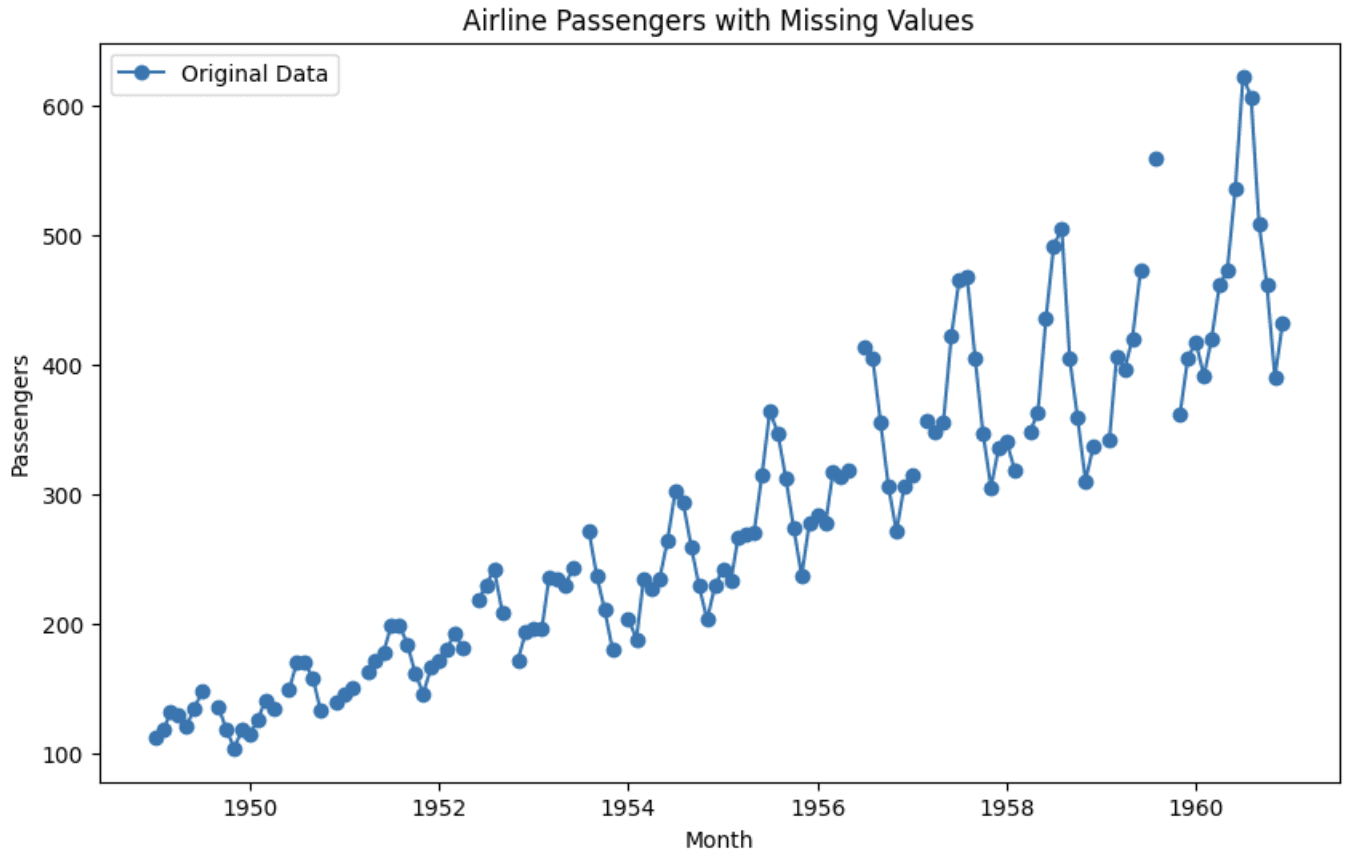
Diagramm des Originaldatensatzes
Sie können sehen, dass die Grafik in zwei Hälften geteilt ist, was das Fehlen von Werten an diesen Stellen anzeigt.
Schritt 4: Interpolation verwenden
Obwohl ich später einige Tipps geben werde, die Ihnen bei der Auswahl der richtigen Interpolationstechnik helfen, konzentrieren wir uns auf diesen Datensatz. Wir wissen, dass es sich um Zeitreihendaten handelt, aber da der Pattern nicht linear zu sein scheint, ist eine einfache zeitbasierte Interpolation, die einem linearen Pattern folgt, hier nicht intestine geeignet. Wir können einige Muster und Schwankungen zusammen mit linearen Traits nur innerhalb einer kleinen Umgebung beobachten. Unter Berücksichtigung dieser Faktoren wird die Spline-Interpolation hier intestine funktionieren. Wenden wir sie additionally an und prüfen wir, wie die Visualisierung nach der Interpolation der fehlenden Werte ausfällt.
# Use spline interpolation to fill in lacking values
df_interpolated = df.interpolate(methodology='spline', order=3)
# Plot the interpolated information
plt.determine(figsize=(10,6))
plt.plot(df_interpolated.index, df_interpolated('Passengers'), label="Spline Interpolation")
plt.plot(df.index, df('Passengers'), label="Authentic Knowledge", alpha=0.5)
plt.scatter(missing_idx, df_interpolated.loc(missing_idx, 'Passengers'), label="Interpolated Values", shade="inexperienced")
plt.legend()
plt.title('Airline Passengers with Spline Interpolation')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.present()
Graph nach Interpolation
Wir können der Grafik entnehmen, dass die interpolierten Werte die Datenpunkte vervollständigen und zudem das Muster beibehalten. Sie kann nun für weitere Analysen oder Prognosen verwendet werden.
Tipps zur Auswahl der Interpolationsmethode
Dieser Bonusteil des Artikels konzentriert sich auf einige Tipps:
- Visualisieren Sie Ihre Daten, um ihre Verteilung und ihr Muster zu verstehen. Wenn die Daten gleichmäßig verteilt sind und/oder die fehlenden Werte zufällig verteilt sind, funktionieren einfache Interpolationstechniken intestine.
- Wenn Sie Traits oder Saisonalität in Ihren Zeitreihendaten beobachten, empfiehlt sich die Verwendung der Spline- oder Polynom-Interpolation, um diese Traits beizubehalten und gleichzeitig die fehlenden Werte zu ergänzen, wie im obigen Beispiel gezeigt.
- Polynome mit höherem Grad können flexibler angepasst werden, neigen aber zur Überanpassung. Halten Sie den Grad niedrig, um unrealistische Formen zu vermeiden.
- Verwenden Sie für ungleichmäßig verteilte Werte indexbasierte Methoden wie Index und Zeit, um Lücken zu füllen, ohne den Maßstab zu verzerren. Sie können hier auch Backfill oder Forwardfill verwenden.
- Wenn sich Ihre Werte nicht häufig ändern oder keinem steigenden und fallenden Muster folgen, können Sie auch intestine den nächstgelegenen gültigen Wert verwenden.
- Testen Sie verschiedene Methoden anhand einer Datenstichprobe und bewerten Sie, wie intestine die interpolierten Werte im Vergleich zu den tatsächlichen Datenpunkten passen.
Wenn Sie andere Parameter der Methode „dataframe.interpolate“ erkunden möchten, besuchen Sie am besten die Pandas-Dokumentation: Pandas-Dokumentation.
Kanwal Mehreen Kanwal ist Ingenieurin für maschinelles Lernen und technische Autorin mit einer tiefen Leidenschaft für Datenwissenschaft und die Schnittstelle zwischen KI und Medizin. Sie ist Mitautorin des E-Books „Maximizing Productiveness with ChatGPT“. Als Google Era Scholar 2022 für APAC setzt sie sich für Vielfalt und akademische Exzellenz ein. Sie ist außerdem als Teradata Variety in Tech Scholar, Mitacs Globalink Analysis Scholar und Harvard WeCode Scholar anerkannt. Kanwal ist eine leidenschaftliche Verfechterin des Wandels und hat FEMCodes gegründet, um Frauen in MINT-Fächern zu stärken.