
Bildsegmentierung hat sich zu einer beliebten Technologie entwickelt, wobei verschiedene, fein abgestimmte Modelle für verschiedene Zwecke verfügbar sind. Das Modell beschriftet jedes Pixel in einem Bild, indem es jeden Bereich des Eingabebildes streamt. Dieses Konzept macht die Idee der semantischen Segmentierung zur Realität und Anwendung.
Dieses Face-Parsing-Modell ist eine semantische Segmentierungstechnologie, die von Nvidias mit-b5 und Celebmask HQ fein abgestimmt wurde. Der vorgesehene Verwendungszweck ist die Gesichtsanalyse, bei der verschiedene Bereiche in einem Bild, insbesondere die Gesichtszüge, gekennzeichnet werden.
Es kann auch Objekte erkennen und sie mit vorab trainierten Daten kennzeichnen. So können Sie Beschriftungen für alles erhalten, vom Hintergrund bis hin zu Augen, Nase, Haut, Augenbrauen, Kleidung, Hut, Hals, Haaren und anderen Merkmalen.
Lernziel
- Verstehen Sie das Konzept der Gesichtsanalyse als semantisches Segmentierungsmodell.
- Hebt einige wichtige Punkte zur Gesichtsanalyse hervor.
- Erfahren Sie, wie Sie das Gesichtsparsing-Modell ausführen.
- Erhalten Sie Einblick in die realen Anwendungen dieses Modells.
Dieser Artikel wurde im Rahmen der veröffentlicht Knowledge Science-Blogathon.
Was ist Face Parsing?
Gesichtsanalyse ist ein Pc Imaginative and prescient Technologie, die Aufgaben erledigt, die bei der Gesichtsanalyse eines Eingabebildes hilfreich sind. Dieser Vorgang erfolgt durch Pixelsegmentierung der Gesichtsteile und anderer sichtbarer Bereiche des Bildes. Mit dieser Bildsegmentierungsaufgabe können Benutzer die Anwendungen dieses Modells auf verschiedene Weise weiter modifizieren, analysieren und nutzen.
Das Verständnis der Modellarchitektur ist ein Schlüsselkonzept für die Funktionsweise dieses Modells. Obwohl dieser Prozess über viele vorab trainierte Daten verfügt, ist die Imaginative and prescient-Transformator-Architektur dieses Modells effizienter.
Modellarchitektur des Face-Parsing-Modells
Dieses Modell verwendet eine transformatorbasierte Architektur für semantische SegmentierungDies bietet eine gute Grundlage für den Bau anderer ähnlicher Modelle wie Segformer. Neben der Integration des Transformatorsystems liegt der Schwerpunkt auch auf einem leichten Dekodierungsmechanismus bei der Bildverarbeitung.
Wenn Sie sich die Schlüsselkomponente dieses Mechanismus ansehen, sehen Sie, dass er aus einem Transformator-Encoder, einem MLP-Decoder und keinen Positionierungseinbettungen besteht. Dies sind wichtige Merkmale des Arbeitssystems von Transformatormodellen bei der Bildsegmentierung.
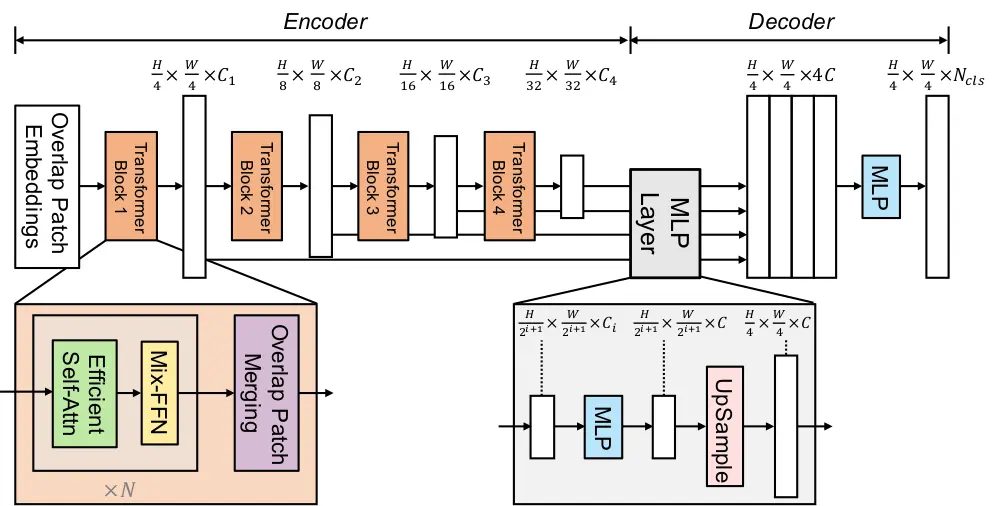
Der Transformator-Encoder ist ein wesentlicher Bestandteil des Mechanismus und hilft dabei, mehrskalige Merkmale aus dem Eingabebild zu extrahieren. So können Sie die Bilder mit Informationen in verschiedenen räumlichen Maßstäben erfassen, um die Effizienz des Modells zu verbessern.
Der leichte Decoder ist ein weiterer wichtiger Bestandteil der Architektur dieses Modells. Es basiert auf einem mehrschichtigen Wahrnehmungsdecoder und ermöglicht es ihm, Informationen aus verschiedenen Schichten des Transformator-Encoders zusammenzustellen. Dieses Modell kann dies erreichen, indem es lokale und globale Aufmerksamkeitsmechanismen nutzt; Die lokale Aufmerksamkeit hilft dabei, Gesichtszüge zu erkennen, während die globale Aufmerksamkeit für eine gute Abdeckung der Gesichtsstruktur sorgt.
Dieser Mechanismus gleicht die Leistung und Effizienz des Modells aus. Somit ermöglicht diese Architektur eine Minimierung der Ressourcen, ohne die Ausgabe zu beeinträchtigen.
Die No-Place-Codierung ist ein weiterer wesentlicher Bestandteil der Gesichtsparsing-Architektur, die in vielen Pc-Imaginative and prescient- und Transformer-Modellen zu einem festen Bestandteil geworden ist. Diese Funktion ist darauf zugeschnitten, Probleme mit der Bildauflösung zu vermeiden, selbst bei Bildern außerhalb einer Grenze. Somit bleibt die Effizienz unabhängig von Positionscodes erhalten.
Insgesamt schneidet das Design des Modells bei Normal-Benchmarks zur Gesichtssegmentierung intestine ab. Es ist effektiv und kann auf verschiedene Gesichtsbilder übertragen werden, was es zu einer robusten Wahl für Aufgaben wie Gesichtserkennung, Avatar-Generierung oder AR-Filter macht. Das Modell behält scharfe Grenzen zwischen Gesichtsregionen bei, eine wesentliche Voraussetzung für eine genaue Gesichtsanalyse.
So führen Sie das Gesichtsparsing-Modell aus
In diesem Abschnitt werden die Schritte zum Ausführen des Codes dieses Modells mit Ressourcen aus der Hugging Face-Bibliothek beschrieben. Das Ergebnis würde die Bezeichnungen aller Gesichtsmerkmale anzeigen, die es erkennen kann. Sie können dieses Modell mithilfe der Inferenz-API und Bibliotheken ausführen. Schauen wir uns additionally diese Methoden genauer an.
Ausführen von Inferenzen zur Gesichtsanalyse mithilfe von Hugging Face
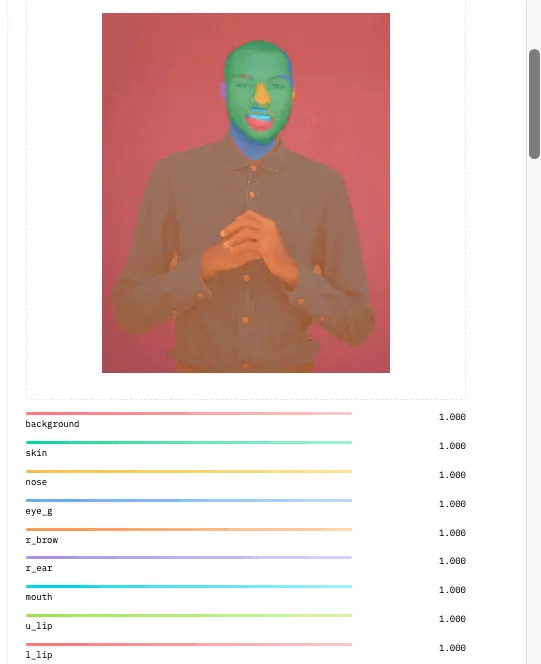
Sie können die verfügbare Inferenz-API verwenden umarmen Face um die Aufgaben zur Gesichtsanalyse abzuschließen. Das Inferenz-API-Software des Modells verwendet ein Bild als Eingabe und die Gesichtsanalyse beschriftet die Teile des Gesichts auf dem Bild mit Farben.
import requests
API_URL = "https://api-inference.huggingface.co/fashions/jonathandinu/face-parsing"
headers = {"Authorization": "Bearer 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"}
def question(filename):
with open(filename, "rb") as f:
information = f.learn()
response = requests.put up(API_URL, headers=headers, information=information)
return response.json()
output = question("/content material/IMG_20221108_073555.jpg")Der obige Code beginnt mit der Anforderungsbibliothek, um HTTPS-Anfragen zu verarbeiten und über Webplattformen mit der API zu kommunizieren. Wenn Sie additionally Hugging Face als API verwenden, können Sie mithilfe des Tokens, der kostenlos auf der Plattform erstellt werden kann, eine Autorisierung erhalten. Während die URL den Endpunkt des Modells angibt, wird das Token zur Authentifizierung verwendet, wenn Anfragen an die Hugging-Face-API gestellt werden.
Der Relaxation des Codes sendet eine Bilddatei an die API und ruft die Ergebnisse ab. Die Abfragefunktion wird mit einer Datei aufgerufen, die den Speicherort des Bildes anzeigt. Die Funktion sendet das Bild an die API und speichert die Antwort (JSON-Format) in der Variablenausgabe.
outputAls nächstes geben Sie Ihre „Ausgabe“ ein. Variable, um das Ergebnis der Inferenz anzuzeigen.

Importieren der wesentlichen Bibliotheken
Dieser Code importiert die erforderlichen Bibliotheken für die Bildsegmentierungsaufgabe mithilfe von Segformer als Basismodell. Es bringt außerdem einen Bildprozessor aus der Transformers-Bibliothek mit, um das Segformer-Modell zu verarbeiten und auszuführen. Anschließend wird PIL importiert, um das Laden von Bildern zu übernehmen Matplotlib um die Segmentierungsergebnisse zu visualisieren. Zuletzt werden Anfragen importiert, um Bilder von URLs abzurufen.
import torch
from torch import nn
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
from PIL import Picture
import matplotlib.pyplot as plt
import requestsEinbindende {Hardware} – GPU/CPU/
system = (
"cuda"
# System for NVIDIA or AMD GPUs
if torch.cuda.is_available()
else "mps"
# System for Apple Silicon (Metallic Efficiency Shaders)
if torch.backends.mps.is_available()
else "cpu"
)
Dieser Code greift auf die verfügbare {Hardware} des lokalen Geräts zu, das für die Ausführung dieses Modells geeignet ist. Wie im Code gezeigt, weist es „cuda“ für NVIDIA- oder AMD-GPUs und mps für Apple-Siliziumgeräte zu. Standardmäßig nutzt dieses Modell nur die CPU ohne andere verfügbare {Hardware}.
Laden der Prozessoren
Der folgende Code lädt den Segformer-Bildprozessor und das semantische Segmentierungsmodell, die vorab auf „jonathandinu/face-parsing“ trainiert wurden, mit Datensätzen für Gesichtsparsing-Aufgaben.
image_processor = SegformerImageProcessor.from_pretrained("jonathandinu/face-parsing")
mannequin = SegformerForSemanticSegmentation.from_pretrained("jonathandinu/face-parsing")
mannequin.to(system)Der nächste Schritt besteht darin, das Bild für die Bildsegmentierungsaufgabe abzurufen. Sie können dies tun, indem Sie die Datei hochladen oder die URL des Bildes laden, wie im Bild unten gezeigt;
url = "https://pictures.unsplash.com/photo-1539571696357-5a69c17a67c6"
picture = Picture.open(requests.get(url, stream=True).uncooked)
Dieser Code verarbeitet ein Bild mit dem „image_processor“, konvertiert es in einen PyTorch-Tensor und verschiebt es auf das angegebene Gerät (GPU, MPS oder CPU).
inputs = image_processor(pictures=picture, return_tensors="pt").to(system)
outputs = mannequin(**inputs)
logits = outputs.logits # form (batch_size, num_labels, ~top/4, ~width/4)Der verarbeitete Tensor wird in das Segformer-Modell eingespeist, um Segmentierungsausgaben zu generieren. Die Logits werden aus der Modellausgabe extrahiert und stellen die Rohwerte für jedes Pixel über verschiedene Beschriftungen hinweg dar, wobei die Abmessungen für Höhe und Breite um 4 verkleinert werden.
Ausgabe
Um die Ausgabe zu erhalten, gibt es einige Codezeilen, die Ihnen bei der Anzeige der Bildergebnisse helfen. Zunächst ändern Sie die Größe der Ausgabe, um sicherzustellen, dass sie mit den Abmessungen der Bildeingabe übereinstimmt. Dies erfolgt durch lineare Interpolation, um einen Wert zur Schätzung der Punkte der Bildgröße zu erhalten.
# resize output to match enter picture dimensions
upsampled_logits = nn.practical.interpolate(logits,
dimension=picture.dimension(::-1), # H x W
mode="bilinear",
align_corners=False)
Zweitens müssen Sie die Beschriftungsmasken ausführen, um den Ausgabewert in den Klassendimensionen zu unterstützen.
# get label masks
labels = upsampled_logits.argmax(dim=1)(0)
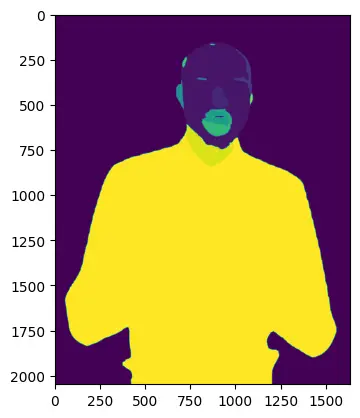
Schließlich können Sie das Bild mithilfe der Bibliothek „metaplotlib“ visualisieren.
# transfer to CPU to visualise in matplotlib
labels_viz = labels.cpu().numpy()
plt.imshow(labels_viz)
plt.present()
Das Bild enthält die Beschriftungen der Gesichtszüge, wie unten gezeigt;
Reale Anwendung des Gesichtsparsing-Modells
Dieses Modell hat verschiedene Anwendungen in verschiedenen Branchen, wobei viele ähnliche, fein abgestimmte Modelle bereits im Einsatz sind. Hier sind einige der beliebtesten Anwendungen der Face-Parsing-Technologie;
- Sicherheit: Dieses Modell verfügt über Gesichtserkennungsfunktionen, die es ermöglichen, Personen anhand von Gesichtsmerkmalen zu identifizieren. Es kann auch dabei helfen, eine Liste der Personen zu erstellen, die zu einer Veranstaltung oder privaten Versammlung zugelassen sind, und gleichzeitig unerkannte Gesichter zu blockieren.
- Soziale Medien: Die Bildsegmentierung ist im Social-Media-Bereich weit verbreitet, und dieses Modell bringt auch einen Mehrwert für diese Branche. Das Modell kann Hauttöne und andere Gesichtsmerkmale ändern, um Schönheitseffekte in Fotos, Movies und On-line-Conferences zu erzielen.
- Unterhaltung: Gesichtsanalyse hat einen großen Einfluss auf die Unterhaltungsindustrie. Verschiedene Parsing-Attribute können Produzenten dabei helfen, die Farben und Töne an verschiedenen Positionen eines Bildes zu ändern. Sie können das Bild analysieren, Verzierungen hinzufügen und einige Teile eines Bildes oder Movies ändern.
Abschluss
Das Gesichtsanalysemodell ist ein leistungsstarkes Werkzeug zur semantischen Segmentierung, mit dem Gesichtsmerkmale in Bildern und Movies genau gekennzeichnet und analysiert werden können. Dieses Modell verwendet eine transformatorbasierte Architektur, um Multiskalenfunktionen effizient zu extrahieren und gleichzeitig die Leistung durch einen einfachen Decodierungsmechanismus und das Fehlen von Positionscodierungen sicherzustellen.
Seine Vielseitigkeit ermöglicht verschiedene reale Anwendungen, von der Verbesserung der Sicherheit durch Gesichtserkennung bis hin zur Bereitstellung erweiterter Bildbearbeitungsfunktionen in sozialen Medien und Unterhaltung.
Wichtige Erkenntnisse
- Transformatorbasierte Architektur: Dieser Mechanismus spielt eine wesentliche Rolle für die Effizienz und Leistung dieses Modells. Außerdem werden Probleme mit der Bildauflösung dadurch vermieden, dass dieses System keine Positionskodierung aufweist.
- Vielseitige Anwendungen: Dieses Modell kann in verschiedenen Branchen eingesetzt werden; Sicherheits-, Unterhaltungs- und Social-Media-Bereiche können wertvolle Einsatzmöglichkeiten der Gesichtsanalyse-Technologie finden.
- Semantische Segmentierung: Durch die genaue Segmentierung jedes Pixels im Zusammenhang mit Gesichtsmerkmalen erleichtert das Modell die detaillierte Analyse und Bearbeitung von Bildern und bietet Benutzern wertvolle Erkenntnisse und Möglichkeiten zur Gesichtsanalyse.
Ressourcen
Häufig gestellte Fragen
A. Face Parsing ist eine Pc-Imaginative and prescient-Technologie, die ein Bild in verschiedene Gesichtsmerkmale segmentiert und jeden Bereich wie Augen, Nase, Mund und Haut beschriftet.
A. Das Modell verarbeitet Eingabebilder über eine transformatorbasierte Architektur, die Multiskalenmerkmale erfasst. Darauf folgt ein leichter Decoder, der Informationen aggregiert, um genaue Segmentierungsergebnisse zu erzielen.
A. Zu den wichtigsten Anwendungen gehören Sicherheit (Gesichtserkennung), soziale Medien (Foto- und Videoverbesserung) und Unterhaltung (Bild- und Videobearbeitung).
A. Die Transformatorarchitektur ermöglicht eine effiziente Bildverarbeitung, eine bessere Handhabung unterschiedlicher Bildauflösungen und eine verbesserte Segmentierungsgenauigkeit, ohne dass eine Positionskodierung erforderlich ist.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.