Setzen Sie Cluster-Algorithmen ein, um fehlende Zeitreihendaten zu verarbeiten

(Wenn Sie Teil 1 noch nicht gelesen haben, schauen Sie ihn sich an Hier.)
Fehlende Daten in der Zeitreihenanalyse sind ein wiederkehrendes Drawback.
Als wir es erkundeten Teil 1einfache Imputationstechniken oder sogar regressionsbasierte Modelle – lineare Regression, Entscheidungsbäume kann uns weit bringen.
Aber was wäre, wenn wir müssen mit subtileren Mustern umgehen aUnd die feinkörnigen Schwankungen in den komplexen Zeitreihendaten erfassen?
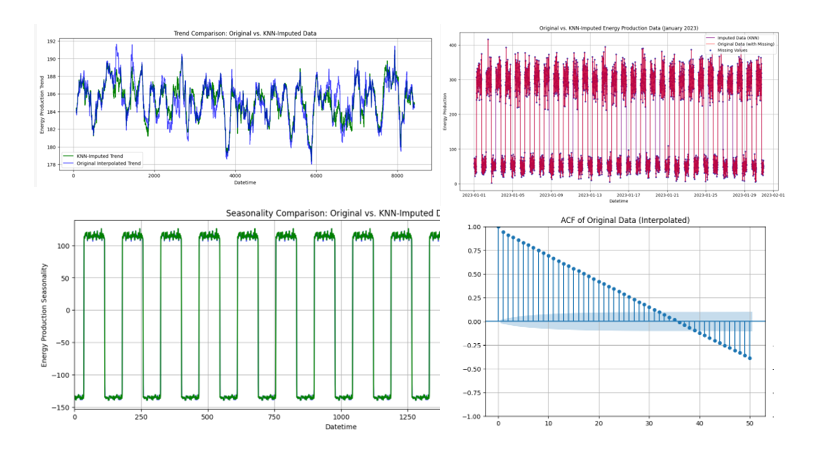
In diesem Artikel werden wir Okay-Nearest Neighbors untersuchen. Zu den Stärken dieses Modells gehören wenige Annahmen in Bezug auf nichtlineare Beziehungen in Ihren Daten; Daher wird es zu einer vielseitigen und robusten Lösung für die Imputation fehlender Daten.
Wir werden es sein unter Verwendung desselben Schein-Energieproduktionsdatensatzes die Sie bereits in Teil 1 gesehen haben, mit 10 % fehlenden Werten, zufällig eingeführt.
Wir unterstellen fehlende Daten anhand eines Datensatzes, den Sie ganz einfach selbst generieren können, sodass Sie die Techniken in Echtzeit verfolgen und anwenden können, während Sie den Prozess Schritt für Schritt erkunden!