Characteristic Engineering für Klassifizierungsmodelle mithilfe von Bayesian Machine Studying
Die logistische Regression ist bei weitem das am weitesten verbreitete maschinelle Lernmodell für binäre Klassifizierungsdatensätze. Das Modell ist relativ einfach und basiert auf einer Schlüsselannahme: der Existenz einer linearen Entscheidungsgrenze (eine Linie oder eine Fläche in einem höherdimensionalen Merkmalsraum), die die Klassen der Zielvariablen y basierend auf den Merkmalen im Modell trennen kann.
Kurz gesagt kann die Entscheidungsgrenze als Schwelle interpretiert werden, bei der das Modell einen Datenpunkt der einen oder anderen Klasse zuordnet, abhängig von der vorhergesagten Wahrscheinlichkeit der Zugehörigkeit zu einer Klasse.
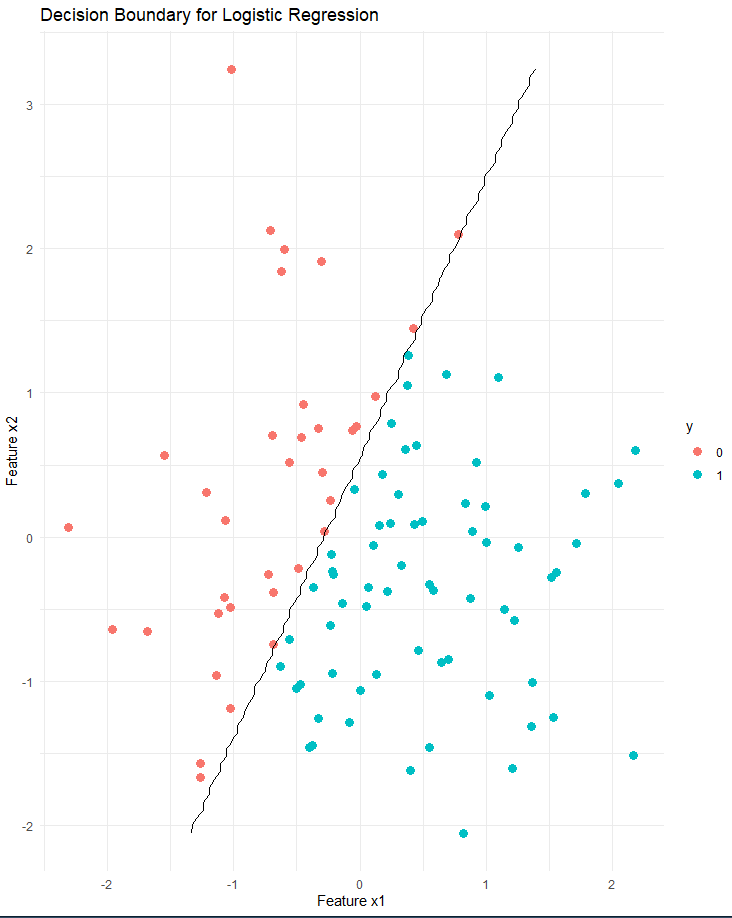
Die folgende Abbildung zeigt eine schematische Darstellung der Entscheidungsgrenze, die die Zielvariable in zwei Klassen unterteilt. In diesem Fall basiert das Modell auf einem Satz von zwei Merkmalen (x1 und x2). Die Zielvariable lässt sich anhand der Werte der Merkmale klar in zwei Klassen einteilen.

Bei Ihren täglichen Modellierungsaktivitäten könnte die State of affairs jedoch eher wie in der folgenden Abbildung aussehen.