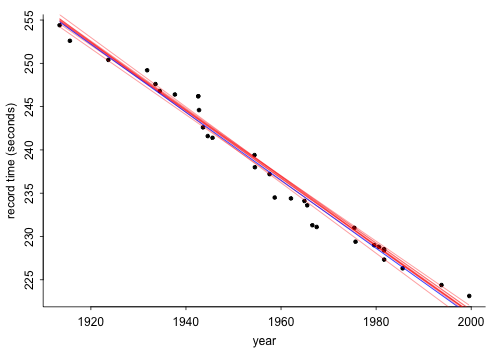

Die obige Grafik zeigt für die Weltrekordzeiten in der Meile von 1913 bis 1999 zusammen mit einer angepassten Regressionslinie (in Blau) und 10 Unentschieden aus der hinteren Verteilung der Linie (in Rot).
Hier ist das montierte Modell:
Median MAD_SD
(Intercept) 1006.24 22.78
12 months -0.39 0.01
Auxiliary parameter(s):
Median MAD_SD
sigma 1.42 0.19
Die geschätzte Steigung beträgt -0,39: Während des 20. Jahrhunderts sank die Rekordzeit um etwa 0,4 Sekunden professional Jahr. Ziemlich cool!
Aber was ist mit dem Abfangen? 1006.88 ist die vorhergesagte Rekordzeit. . . In dem Jahr, in dem Jesus geboren wurde.
Hier ist die Grafik auf der Skala einschließlich x = 0:

In diesem Fall würden wir es besser machen, indem wir den Prädiktor zentrieren und neu skalieren, zum Beispiel das Jahr 1950 in die Zentrum und Division von 10, damit er als „Jahrzehnte im Verhältnis zu 1950“ interpretiert werden kann. Hier ist das Ergebnis:
Median MAD_SD
(Intercept) 240.43 0.28
I((12 months - 1950)/10) -3.93 0.11
Auxiliary parameter(s):
Median MAD_SD
sigma 1.42 0.18
Das lineare Modell prognostiziert 1950 von 4 Minuten und 0,43 Sekunden eine Rekordzeit mit einem Rückgang von etwa 3,9 Sekunden professional Jahrzehnt im Zeitraum der Daten.
Dies ist alles mathematisch trivial, aber ich sehe die ganze Zeit, wie Menschen Schwierigkeiten haben, Regressionen mit Prädiktoren zu interpretieren, die alles andere als Null sind. Dies ist insbesondere ein Drawback, wenn das Modell Wechselwirkungen aufweist. In diesem Fall kann jede Haupteffekt als Steigung interpretiert werden, wenn die anderen Prädiktoren Null gleich sind.
Der einfache Weg, sich daran zu erinnern: „Der Abfang ist der vorhergesagte Wert in dem Jahr, in dem Jesus geboren wurde.“ Sie möchten dies vermeiden (es sei denn, Sie analysieren Daten aus dem frühen Römischen Reich).
Ps In den Kommentaren über den linearen Pattern gibt es einige Diskussionen, die nicht mehr ist. (Die aktuellen Weltrekorde für 1500 Meter und die Meile wurden 1998 bzw. 1999 festgelegt.)
Ich spreche nur als ungezwungener Beobachter, nicht als Experte für Leichtathletik, und habe den Eindruck, dass die lineare Verbesserung im Laufe des Jahrhunderts ein Produkt mehrerer Veränderungen zu unterschiedlichen Zeiten ist, einschließlich eines besseren Trainings, dem globalen Wettbewerb, einer Veränderung der Ansichten über die möglichen, besseren Lauftechniken und einer größeren Bevölkerung potenzieller Läufer. Vielleicht auch bessere Schuhe. Seit 2000 gab es keine neuen Aufzeichnungen, was darauf hindeutet, dass die letzte größere Verbesserung bereits stattgefunden hat – obwohl ich denke, dass die Technologie durch Doping, Körperänderung oder verbesserte Coaching und Technik Verbesserungen erzielen könnte.
Ich nehme das Linear-Over-A-Century-Ding eher ein statistisches Artefakt als alles andere. Trotzdem ist es amüsant, weshalb es seit langem eines meiner Lieblings -Statistikbeispiele ist. In der Tat habe ich in den 1980er Jahren zunächst angefangen, dies als Lehrbeispiel zu verwenden. Zu diesem Zeitpunkt befanden wir uns noch im Bereich der ungefähren linearen Verbesserung. Ich hatte keine Ahnung, dass der Pattern vor der Jahrhundertwende zum Stillstand kommen würde.
Pps Hier sind die Daten (die ich vor Jahren getippt habe, wahrscheinlich aus Wikipedia):
yr month min sec 1913 5 4 14.4 1915 7 4 12.6 1923 8 4 10.4 1931 10 4 09.2 1933 7 4 07.6 1934 6 4 06.8 1937 8 4 06.4 1942 7 4 06.2 1942 7 4 06.2 1942 9 4 04.6 1943 7 4 02.6 1944 7 4 01.6 1945 7 4 01.4 1954 5 3 59.4 1954 6 3 58.0 1957 7 3 57.2 1958 8 3 54.5 1962 1 3 54.4 1964 11 3 54.1 1965 6 3 53.6 1966 7 3 51.3 1967 6 3 51.1 1975 5 3 51.0 1975 8 3 49.4 1979 7 3 49.0 1980 7 3 48.8 1981 8 3 48.53 1981 8.2 3 48.40 1981 8.3 3 47.33 1985 7 3 46.32 1993 9 3 44.39 1999 7 3 43.13
Und mein R -Code:
library("rstanarm")
mile <- learn.desk("mile2.txt", header=TRUE)
mile$12 months <- mile$yr + mile$month/12
mile$time_in_seconds <- mile$min*60 + mile$sec
match <- stan_glm(time_in_seconds ~ 12 months, information=mile)
print(match, digits=2)
png("jesus_1.png", top=350, width=500)
par(mar=c(3,3,1,1), mgp=c(1.8,.5,0), tck=-.01)
plot(mile$12 months, mile$time_in_seconds, xlab="12 months", ylab="file time (seconds)", pch=20, bty="l")
sims <- as.matrix(match)
n_sims <- nrow(sims)
for (s in pattern(n_sims, 10)) {
curve(sims(s,1) + sims(s,2)*x, lwd=.5, col="pink", add=TRUE)
}
curve(median(sims(,1)) + median(sims(,2))*x, col="blue", add=TRUE)
dev.off()
png("jesus_2.png", top=350, width=500)
par(mar=c(3,3,1,1), mgp=c(1.8,.5,0), tck=-.01)
plot(mile$12 months, mile$time_in_seconds, xlim=c(0,2000), ylim=median(sims(,1)) + median(sims(,2))*c(2000,0), xlab="12 months", ylab="file time (seconds)", pch=20, bty="l")
sims <- as.matrix(match)
n_sims <- nrow(sims)
for (s in pattern(n_sims, 10)) {
curve(sims(s,1) + sims(s,2)*x, lwd=.5, col="pink", add=TRUE)
}
curve(median(sims(,1)) + median(sims(,2))*x, col="blue", add=TRUE)
dev.off()
print(stan_glm(time_in_seconds ~ I((year-1950)/10), information=mile), digits=2)
Ja, der Code ist hässlich. Verklag mich doch.