Sie haben wahrscheinlich schon gehört, dass ein Bild mehr sagt als tausend Worte. Aber kann sich ein großes Sprachmodell (LLM) ein Bild machen, wenn es noch nie zuvor Bilder gesehen hat?
Wie sich herausstellt, verfügen Sprachmodelle, die ausschließlich mit Texten trainiert werden, über ein solides Verständnis der visuellen Welt. Sie können Bildwiedergabecode schreiben, um komplexe Szenen mit faszinierenden Objekten und Kompositionen zu erzeugen – und selbst wenn dieses Wissen nicht richtig eingesetzt wird, können LLMs ihre Bilder verfeinern. Forscher vom Laptop Science and Synthetic Intelligence Laboratory (CSAIL) des MIT beobachteten dies, als sie Sprachmodelle dazu aufforderten, ihren Code für verschiedene Bilder selbst zu korrigieren, wobei die Systeme ihre einfachen Clipart-Zeichnungen mit jeder Abfrage verbesserten.
Das visuelle Wissen dieser Sprachmodelle wird aus der Artwork und Weise gewonnen, wie Konzepte wie Formen und Farben im Web beschrieben werden, sei es in Sprache oder Code. Wenn Benutzer eine Anweisung wie „Zeichne einen Papagei im Dschungel“ erhalten, regen sie das LLM an, darüber nachzudenken, was es zuvor in Beschreibungen gelesen hat. Um zu beurteilen, über wie viel visuelles Wissen LLMs verfügen, entwickelte das CSAIL-Workforce einen „Sehtest“ für LLMs: Mithilfe ihres „Visible Aptitude Dataset“ testeten sie die Fähigkeiten der Modelle, diese Konzepte zu zeichnen, zu erkennen und selbst zu korrigieren. Die Forscher sammelten jeden endgültigen Entwurf dieser Illustrationen und trainierten ein Laptop-Imaginative and prescient-System, das den Inhalt echter Fotos erkennt.
„Wir trainieren im Wesentlichen ein Sehsystem, ohne direkt visuelle Daten zu verwenden“, sagt Tamar Rott Shaham, Co-Leiterin der Studie und Postdoc für Elektrotechnik und Informatik (EECS) am MIT am CSAIL. „Unser Workforce hat Sprachmodelle abgefragt, um Bildwiedergabecodes zu schreiben, die Daten für uns generieren, und dann das Bildverarbeitungssystem trainiert, um natürliche Bilder auszuwerten. Wir wurden von der Frage inspiriert, wie visuelle Konzepte durch andere Medien wie Textual content dargestellt werden. Um ihr visuelles Wissen auszudrücken, können LLMs Code als gemeinsame Foundation zwischen Textual content und Bild verwenden.“
Um diesen Datensatz zu erstellen, fragten die Forscher zunächst die Modelle ab, um Code für verschiedene Formen, Objekte und Szenen zu generieren. Dann kompilierten sie diesen Code, um einfache digitale Illustrationen wie eine Reihe von Fahrrädern darzustellen. Dies zeigt, dass LLMs räumliche Beziehungen intestine genug verstehen, um die Zweiräder in einer horizontalen Reihe zu zeichnen. Als weiteres Beispiel generierte das Modell einen autoförmigen Kuchen, indem es zwei zufällige Konzepte kombinierte. Das Sprachmodell produzierte auch eine leuchtende Glühbirne, was auf seine Fähigkeit hindeutet, visuelle Effekte zu erzeugen.
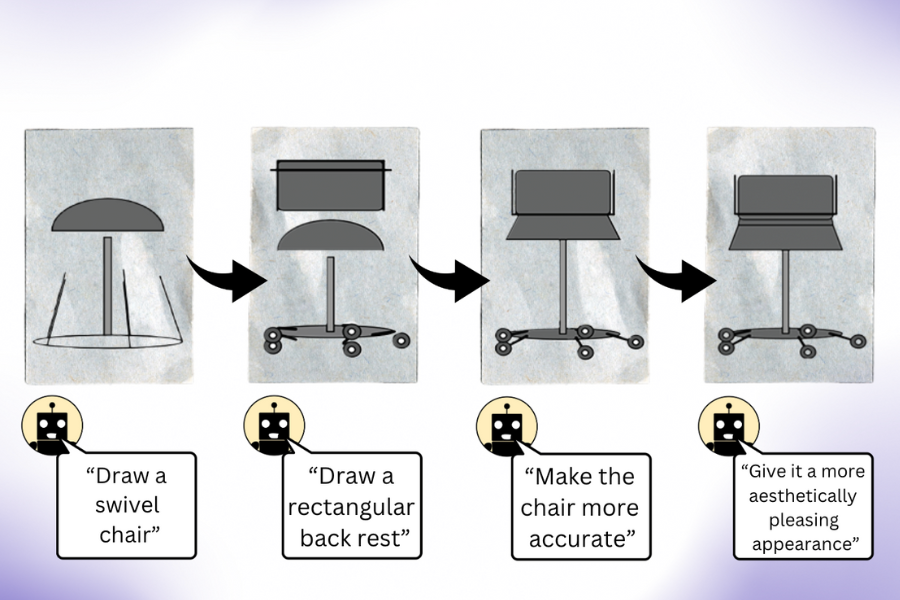
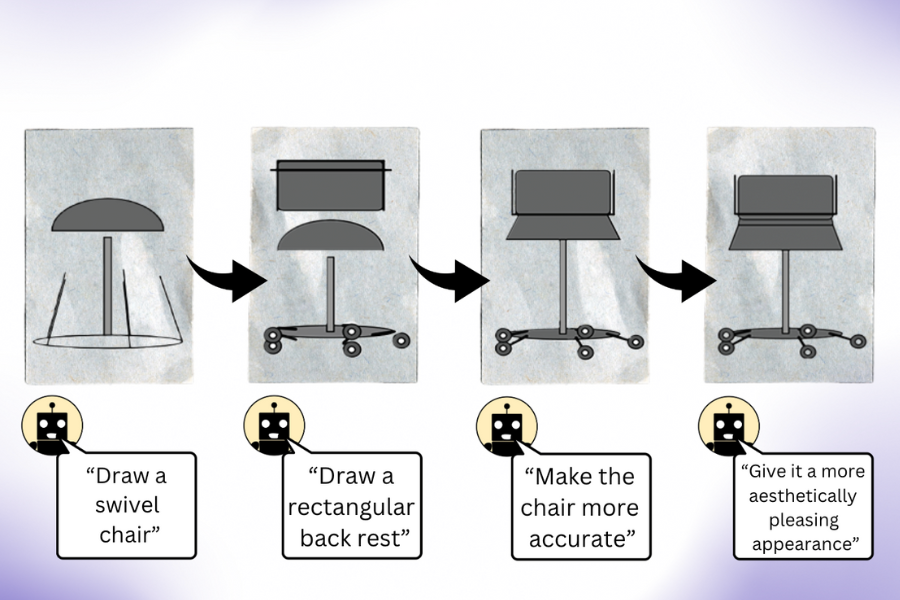
„Unsere Arbeit zeigt, dass ein LLM (ohne multimodales Vortraining) viel mehr weiß, als es scheint, wenn Sie es auffordern, ein Bild zu erstellen“, sagt Pratyusha Sharma, Co-Leiterin der Studie, EECS-Doktorandin und CSAIL-Mitglied. „Nehmen wir an, Sie bitten es, einen Stuhl zu zeichnen. Das Modell weiß andere Dinge über dieses Möbelstück, die es möglicherweise nicht sofort gerendert hat, sodass Benutzer das Modell auffordern können, die von ihm erstellte visuelle Darstellung mit jeder Iteration zu verbessern. Überraschenderweise kann das Modell die Zeichnung iterativ bereichern, indem es den Rendering-Code in erheblichem Maße verbessert.“
Die Forscher sammelten diese Illustrationen und trainierten damit ein Laptop-Imaginative and prescient-System, das Objekte in echten Fotos erkennen kann (obwohl es noch nie eines gesehen hat). Mit diesen synthetischen, textgenerierten Daten als einzigem Referenzpunkt übertrifft das System andere prozedural generierte Bilddatensätze, die mit authentischen Fotos trainiert wurden.
Das CSAIL-Workforce ist der Ansicht, dass es auch von Vorteil sein könnte, das verborgene visuelle Wissen von LLMs mit den künstlerischen Fähigkeiten anderer KI-Instruments wie Diffusionsmodellen zu kombinieren. Systemen wie Midjourney fehlt manchmal das Know-how, um die feineren Particulars eines Bildes konsequent zu optimieren, was es für sie schwierig macht, Anfragen wie die Reduzierung der Anzahl der abgebildeten Autos oder die Platzierung eines Objekts hinter einem anderen zu bearbeiten. Wenn ein LLM die gewünschte Änderung für das Diffusionsmodell im Voraus skizzieren würde, könnte die resultierende Bearbeitung zufriedenstellender sein.
Die Ironie besteht, wie Rott Shaham und Sharma zugeben, darin, dass LLMs manchmal dieselben Konzepte nicht erkennen, die sie zeichnen können. Dies wurde deutlich, als die Modelle menschliche Nachbildungen von Bildern im Datensatz falsch identifizierten. Solche unterschiedlichen Darstellungen der visuellen Welt waren wahrscheinlich der Auslöser für die Fehlinterpretationen der Sprachmodelle.
Während die Modelle Schwierigkeiten hatten, diese abstrakten Darstellungen wahrzunehmen, zeigten sie die Kreativität, dieselben Konzepte jedes Mal anders zu zeichnen. Als die Forscher die LLMs baten, Konzepte wie Erdbeeren und Arkaden mehrfach zu zeichnen, produzierten sie Bilder aus verschiedenen Winkeln mit unterschiedlichen Formen und Farben. Dies deutet darauf hin, dass die Modelle tatsächliche mentale Bilder visueller Konzepte haben könnten (anstatt Beispiele zu rezitieren, die sie zuvor gesehen hatten).
Das CSAIL-Workforce glaubt, dass dieses Verfahren eine Grundlage für die Bewertung sein könnte, wie intestine ein generatives KI-Modell ein Laptop-Imaginative and prescient-System trainieren kann. Darüber hinaus wollen die Forscher die Aufgaben erweitern, mit denen sie Sprachmodelle herausfordern. Was ihre jüngste Studie betrifft, weist die MIT-Gruppe darauf hin, dass sie keinen Zugriff auf den Trainingssatz der von ihnen verwendeten LLMs hat, was es schwierig macht, den Ursprung ihres visuellen Wissens weiter zu untersuchen. In der Zukunft beabsichtigen sie, das Coaching eines noch besseren Imaginative and prescient-Modells zu erforschen, indem sie das LLM direkt damit arbeiten lassen.
Sharma und Rott Shaham sind dabei auf das Papier von den ehemaligen CSAIL-Mitgliedern Stephanie Fu ’22, MNG ’23 und den EECS-Doktoranden Manel Baradad, Adrián Rodríguez-Muñoz ’22 und Shivam Duggal, die alle CSAIL-Mitglieder sind; sowie MIT-Außerordentlicher Professor Phillip Isola und Professor Antonio Torralba. Ihre Arbeit wurde teilweise durch ein Stipendium des MIT-IBM Watson AI Lab, ein LaCaixa-Stipendium, das Zuckerman STEM Management Program und das Viterbi-Stipendium unterstützt. Sie präsentieren ihr Papier diese Woche auf der IEEE/CVF Laptop Imaginative and prescient and Sample Recognition Convention.