
Bauen kuratierte, mit Werkzeug gegründete Demonstrationen stärkere Softwareagenten als breite Stapel generischer Unterrichtsdaten auf? Ein Forscherteam der Shanghai Jiao Tong College und SII Generative AI Analysis Lab (GAIR) schlägt vor Limi („Weniger ist mehr für Agentur“)eine überwachte Methode für Feinabstimmungen, die ein Basismodell in einen fähigen Software program/Forschungsagenten verwandelt 78 Proben. Limi Scores 73,5% durchschnittlich auf Agenturbench (FTFC 71.7, RC@3 74.2, SR@3 74,6), schlägt starke Baselines (GLM-4,5 45.1, Qwen3-235b-A22b 27,5, Kimi-K2 24.1, Deepseek-V3.1 11.9) und sogar übertriebene Varianten, die auf Varianten ausgebildet wurden, die auf die ausgebildeten Varianten ausgebildet sind, die auf die ausgebildeten Varianten ausgebildet sind, die auf ausgebildete Varianten ausgebildet sind, die auf die ausgebildeten Varianten ausgebildet wurden, die auf Varianten ausgebildet wurden, die auf die Ausbildung von Varianten übertrieben sind, die auf ausgebildete Varianten ausgebildet sind, die auf ausgebildete Varianten ausgebildet sind, die auf die Ausbildung von Deepseek-V3.1) und sogar übertroffen wurden. 10.000 Proben-mit 128 × weniger Daten.

Was genau ist neu?
- Agentur -Effizienz -Prinzip: Limi gibt an, dass das Agentenkompetenz skaliert mehr mit Datenqualität/Struktur als Rohprobenzählung. Das Forschungsteam Fein-Tune GLM-4,5/GLM-4,5-Air auf 78 Langhorizont, Werkzeugnutzungstrajektorien (Proben) und melden große Gewinne in Agenturbench- und Generalisierungssuiten (TAU2-Bench, Evalplus-He/MBPP, DS-1000, Scicode).
- Minimale, aber dichte Überwachung. Jede Trajektorie (~ 13K-152K-Token; Sii-cli Ausführungsumgebung. Aufgaben erstrecken sichVibe -Codierung”(Interaktive Softwareentwicklung) und Forschungsworkflows (Suche, Analyse, Experimententwurf).
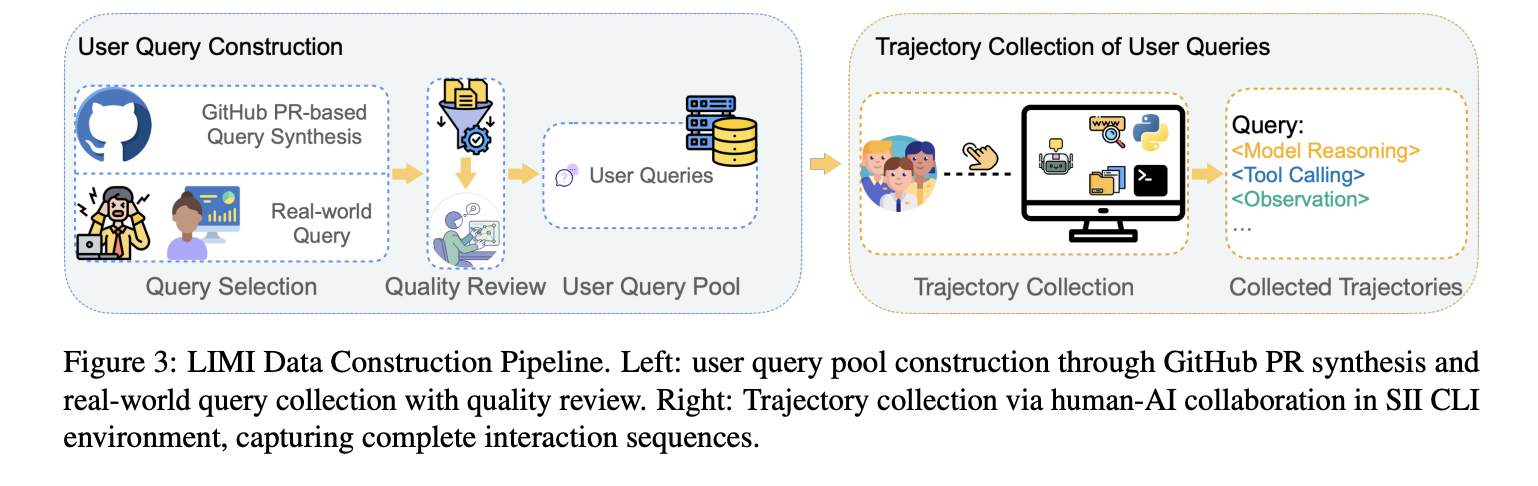
Wie funktioniert es?
- Basismodelle: GLM-4,5 (355B) und GLM-4,5-Air (106B). Coaching verwendet das Schleim SFT -Framework mit identischen Konfigurationen über Vergleiche hinweg (um Dateneffekte zu isolieren).
- Datenkonstruktion: 60 reale Abfragen von Praktizierenden + 18 synthetisierten von Excessive-Star-Github-PRs (enge QA von Doktorandenannotatoren). Für jede Abfrage protokolliert Limi die vollständige Agenten -Flugbahn für eine erfolgreiche Fertigstellung im Inneren Sii-cli.
- Auswertung: Agenturbench (R = 3 Runden) mit FTFC, SR@3, RC@3; Plus Generalisierungssuiten (Tau2-Airline/Retail Go^4, Evalplus He/MBPP, DS-1000, Scicode).
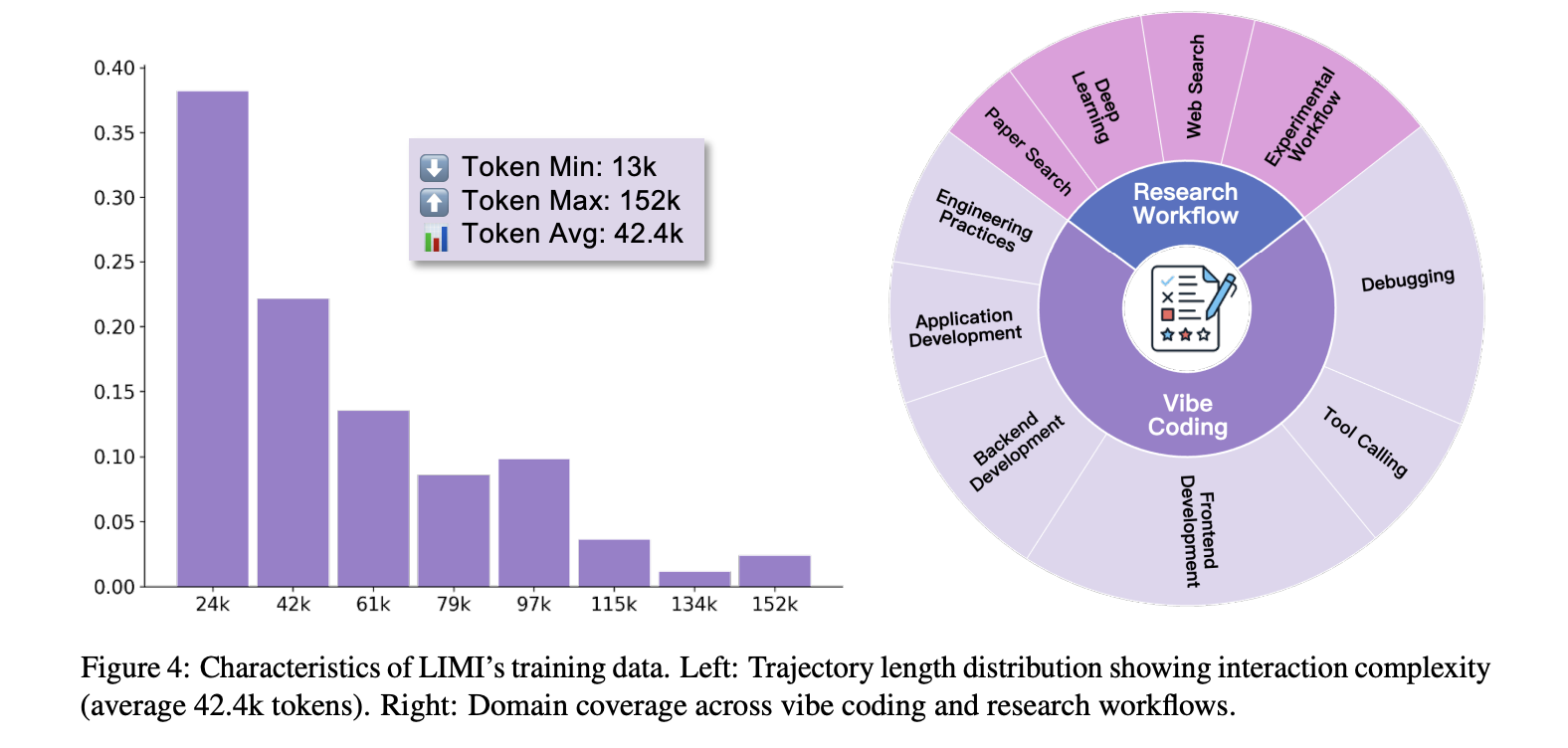
Ergebnisse
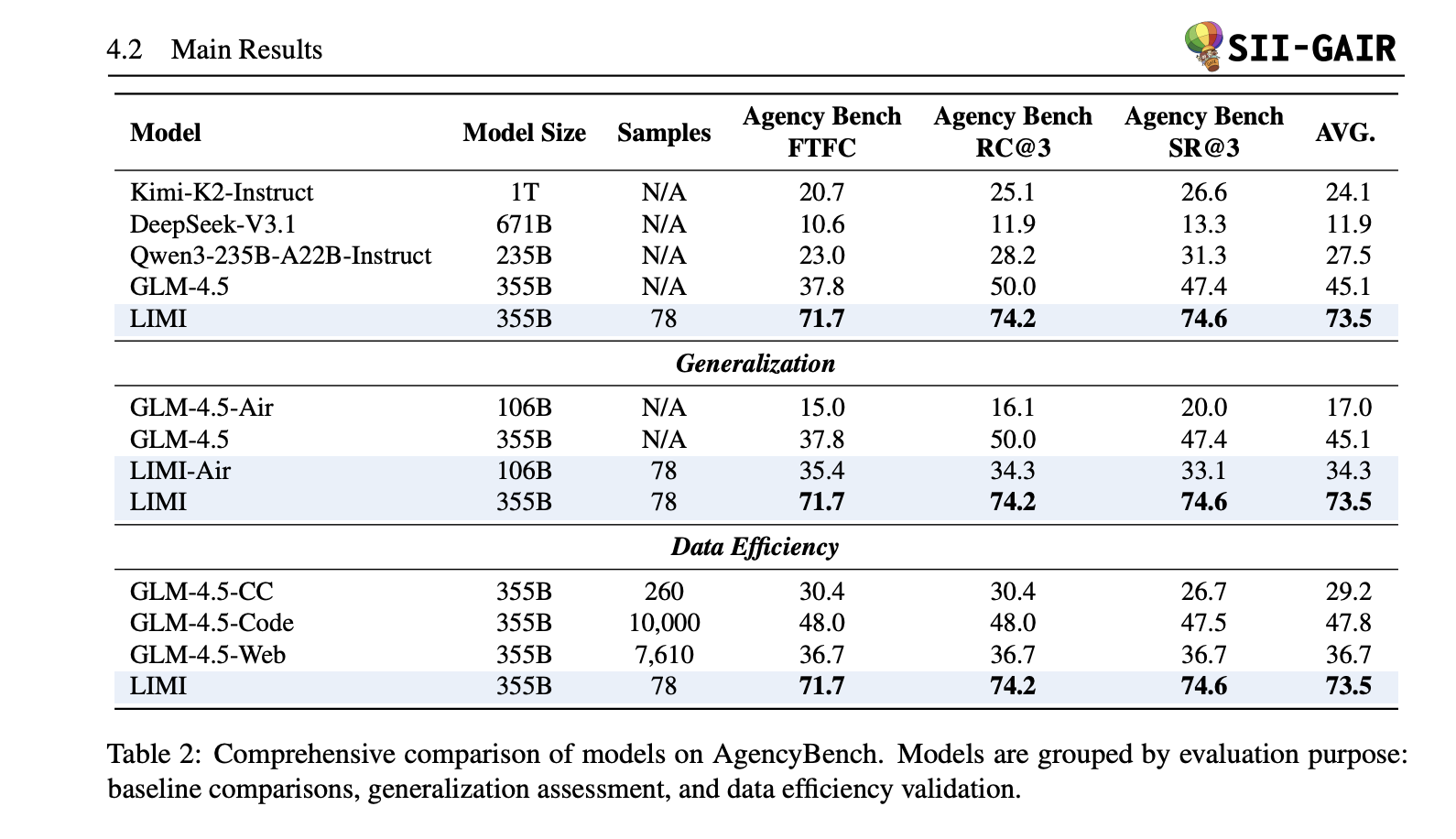
- Agenturbench (AVG): 73,5%. Limi gegen GLM-4.5 (+28,4 Punkte); Ftfc 71,7% vs 37,8%; SR@3 74,6% vs 47,4%.
- Dateneffizienz: Limi (78 Proben) übertrifft GLM-4,5 ausgebildet auf AFM-CodeAg-SFT (10.000 Proben): 73,5% gegenüber 47,8%–+53,7% absolut mit 128 × Weniger Daten. Ähnliche Lücken halten gegen AFM-Webent (7.610) und CC-Bench-Traj (260).
- Verallgemeinerung: In Bezug ~ 57%überschreiten GLM-4,5 und andere Baselines; Ohne Werkzeugzugriff führt Limi immer noch leicht (50,0% gegenüber 48,7% für GLM-4.5), was intrinsischen Gewinnen über die Umweltwerkzeuge hinaus angibt.
Key Takeaways
- Die Dateneffizienz dominiert die Skala. Limi erreicht 73,5% Durchschnitt auf Agenturbench verwenden kuratierte Flugbahnenübertreffen GLM-4,5 (45,1%) und zeigen a +53,7 Punkt Vorteil gegenüber einem 10K-Stichprobe SFT -Grundlinie –mit 128 × weniger Proben.
- Trajektorienqualität, nicht masse. Trainingsdaten sind Langhorizont, Werkzeug gegründet Workflows in der kollaborativen Softwareentwicklung und der wissenschaftlichen Forschung, die über die gesammelt wurden Sii-cli Ausführungsstapel, auf das das Papier verwiesen wird.
- Über metrische Gewinne. Limi berichtet auf AgenturBench FTFC 71,7%Anwesend SR@3 74,6%und stark RC@3mit detaillierten Tischen, die große Ränder über den Baselines zeigen; Generalisierungssuiten (TAU2, Evalplus-He/MBPP, DS-1000, Scicode) Durchschnitt 57,2%.
- Arbeitet über Skalen hinweg. Feinabstimmung GLM-4,5 (355B) Und GLM-4,5-Air (106B) Beide liefern große Deltas über ihre Basen, was die Methode Robustheit für die Modellgröße anzeigt.
Das Forschungsteam trainiert GLM-4,5-Varianten mit 78 kuratierten, langen Horizont, die in einer CLI-Umgebung, die Software program-Engineering- und Forschungsaufgaben umfasst, aufgenommene, mit Werkzeugen erdenkte Wege. Es meldet einen Durchschnitt von 73,5% auf AgencyBench mit FTFC-, RC@3- und SR@3 -Metriken. Die Grundlinie GLM-4,5 wird bei 45,1percentangegeben. Ein Vergleich mit einer AFM-Codeagent-SFT-Basislinie von 10.000 Proben zeigt 73,5% gegenüber 47,8%; Werkzeugfreie Bewertung zeigt intrinsische Gewinne an (~ 50,0% für Limi gegenüber 48,7% GLM-4,5). Die Flugbahnen sind Multiturn und Token-Dicht und betonen Planung, Werkzeugorchestrierung und Überprüfung.
Schauen Sie sich das an PapierAnwesend Github -Seite Und Modellkarte auf HF. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser E-newsletter.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.