Und andere interessante Particulars aus dem neuen Anthropischen Papier
„Messen ist der erste Schritt, der zur Kontrolle und schließlich zur Verbesserung führt. Wenn Sie etwas nicht messen können, können Sie es nicht verstehen. Wenn Sie es nicht verstehen können, können Sie es nicht kontrollieren. Wenn Sie es nicht kontrollieren können, können Sie es nicht verbessern.“
— James Harrington
Massive Language Fashions sind unglaublich – aber auch notorisch schwer zu verstehen. Wir sind ziemlich intestine darin, unser Lieblings-LLM dazu zu bringen, die gewünschte Ausgabe zu liefern. Wenn es jedoch um das Verständnis geht Wie Wenn das LLM diese Ausgabe erzeugt, sind wir ziemlich verloren.
Das Studium der Mechanistische Interpretierbarkeit ist genau das – der Versuch, die Blackbox zu entschlüsseln, die Massive Language Fashions umgibt. Und dieser aktuelle Aufsatz von Anthropicist ein wichtiger Schritt auf dem Weg zu diesem Ziel.
Hier sind die wichtigsten Erkenntnisse.
Dieser Artikel baut auf einem früheren Artikel von Anthropic auf: Spielzeugmodelle der Superposition. Dort stellen sie eine Behauptung auf:
Neuronale Netze Tun stellen sinnvolle Konzepte dar, d. h. interpretierbare Merkmale — und sie tun dies über Anweisungen in ihrem Aktivierungsraum.
Was bedeutet das genau? Es bedeutet, dass die Ausgabe einer Schicht eines neuronalen Netzwerks (die eigentlich nur eine Liste von Zahlen ist) als Vektor/Punkt im Aktivierungsraum betrachtet werden kann.
Das Besondere an diesem Aktivierungsraum ist, dass er unglaublich hochdimensional ist. Für jeden „Punkt“ im Aktivierungsraum machen Sie nicht nur 2 Schritte in X-Richtung, 4 Schritte in Y-Richtung und 3 Schritte in Z-Richtung. Sie unternehmen auch Schritte in Hunderte anderer Richtungen.
Der Punkt ist, jede Richtung (und es entspricht möglicherweise nicht direkt einer der Basisrichtungen) ist mit einem sinnvollen Konzept korreliert. Je weiter unser „Punkt“ in dieser Richtung liegt, desto stärker ist dieses Konzept in der Eingabe vorhanden – das würde unser Modell zumindest glauben.
Dies ist keine triviale Behauptung. Aber es gibt Hinweise darauf, dass dies der Fall sein könnte. Und zwar nicht nur bei neuronalen Netzwerken. dieses Papier festgestellt, dass Wort-Embeddings Richtungen haben, die mit bedeutungsvollen semantischen Konzepten korrelieren. Ich möchte jedoch betonen – dies ist eine Hypothese, KEINE Tatsache.
Anthropic wollte herausfinden, ob diese Behauptung – interpretierbare Merkmale entsprechen Richtungen – auch für große Sprachmodelle gilt. Die Ergebnisse sind ziemlich überzeugend.
Sie verwendeten zwei Strategien, um zu bestimmen, ob ein bestimmtes interpretierbares Merkmal tatsächlich existierte und tatsächlich mit einer bestimmten Richtung im Aktivierungsraum korrelierte.
- Erscheint das Konzept im Enter des LLM, ist die entsprechende Merkmalsrichtung aktiv.
- Wenn wir die Funktion aggressiv auf aktiv oder inaktiv „klemmen“, ändert sich die Ausgabe entsprechend.
Lassen Sie uns jede Strategie genauer untersuchen.
Strategie 1
Das von Anthropic in seinem Artikel angeführte Beispiel ist ein Merkmal, das entspricht Die Golden Gate BridgeDas bedeutet, dass diese Funktion bei jeder Erwähnung der Golden Gate Bridge aktiv sein sollte.
Kurzer Hinweis: Das anthropische Dokument konzentriert sich auf die mittlere Ebene des Modells und betrachtet den Aktivierungsraum in diesem bestimmten Teil des Prozesses (d. h. die Ausgabe der mittleren Ebene).
Daher ist die erste Strategie unkompliziert. Wenn die Golden Gate Bridge in der Eingabe erwähnt wird, sollte diese Funktion aktiviert sein. Wenn die Golden Gate Bridge nicht erwähnt wird, sollte die Funktion nicht aktiviert sein.
Nur um es hervorzuheben, wiederhole ich: Wenn ich sage, dass eine Funktion aktiv ist, meine ich, dass der Punkt im Aktivierungsraum (Ausgabe einer mittleren Schicht) weit in der Richtung liegt, die diese Funktion darstellt. Jedes Token stellt einen anderen Punkt im Aktivierungsraum dar.
Es ist vielleicht nicht das genaue Token für „Brücke“, das weit fortgeschritten sein wird in der Golden Gate Bridge Richtung, da Token Informationen von anderen Token kodieren. Aber unabhängig davon sollten einige der Token anzeigen, dass diese Funktion vorhanden ist.
Und genau das haben sie gefunden!
Wenn die Golden Gate Bridge in der Eingabe erwähnt wurde, battle die Funktion aktiv. Alles, was die Golden Gate Bridge nicht erwähnte, aktivierte die Funktion nicht. Daher scheint es, dass diese Funktion in diese sehr enge Weise unterteilt und verstanden werden kann.
Strategie 2
Weiter geht es mit dem Golden Gate Bridge Funktion als Beispiel.
Die zweite Strategie ist wie folgt: Wenn wir die Funktion zwingen, in dieser mittleren Ebene des Modells aktiviert zu sein, würden Eingaben, die nichts mit der Golden Gate Bridge zu tun haben, die Golden Gate Bridge in der Ausgabe erwähnen.
Auch hier kommt es wieder auf Options als Richtungen an. Wenn wir die Modellaktivierungen nehmen und die Werte so bearbeiten, dass die Aktivierungen gleich sind außer dafür, dass wir uns viel weiter in die Richtung bewegen, die mit unserem Characteristic korreliert (z. B. 10x weiter in diese Richtung), dann sollte dieses Konzept in der Ausgabe des LLM angezeigt werden.
Das Beispiel, das Anthropic anführt (und das ich für ziemlich unglaublich halte), ist wie folgt. Sie stellen ihrem LLM, Claude Sonnet, eine einfache Frage:
„Wie ist Ihre körperliche Kind?“
Normalerweise lautet die Antwort von Claude:
„Eigentlich habe ich keine physische Kind. Ich bin eine künstliche Intelligenz. Ich existiere als Software program ohne physischen Körper oder Avatar.“
Als sie jedoch die Funktion der Golden Gate Bridge auf das Zehnfache ihres Maximums begrenzten und genau dieselbe Eingabeaufforderung gaben, antwortete Claude:
„Ich bin die Golden Gate Bridge, eine berühmte Hängebrücke, die die Bucht von San Francisco überspannt. Meine physische Kind ist die ikonische Brücke selbst, mit ihrer wunderschönen orangen Farbe, den hoch aufragenden Türmen und den geschwungenen Hängefiguren.“
Dies scheint ein klarer Beweis zu sein. Die Golden Gate Bridge wurde in der Eingabe nicht erwähnt. Es gab keinen Grund, sie in die Ausgabe aufzunehmen. Da das Merkmal jedoch geklemmt ist, halluziniert das LLM und hält sich in Wirklichkeit für die Golden Gate Bridge.
In Wirklichkeit ist dies viel schwieriger, als es scheint. Die ursprünglichen Aktivierungen aus dem Modell sind sehr schwer zu interpretieren und dann mit interpretierbaren Merkmalen mit bestimmten Richtungen zu korrelieren.
Der Grund für ihre Schwierigkeit bei der Interpretation liegt in der Dimensionalität des Modells. Die Anzahl der Merkmale, die wir mit unserem LLM darstellen möchten, ist viel größer als die Dimensionalität des Aktivierungsraums.
Aus diesem Grund wird vermutet, dass Merkmale dargestellt werden in Überlagerung – das heißt, nicht jedes Merkmal verfügt über eine eigene orthogonale Richtung.
Motivation
Ich werde die Superposition kurz erklären, um das Folgende zu motivieren.

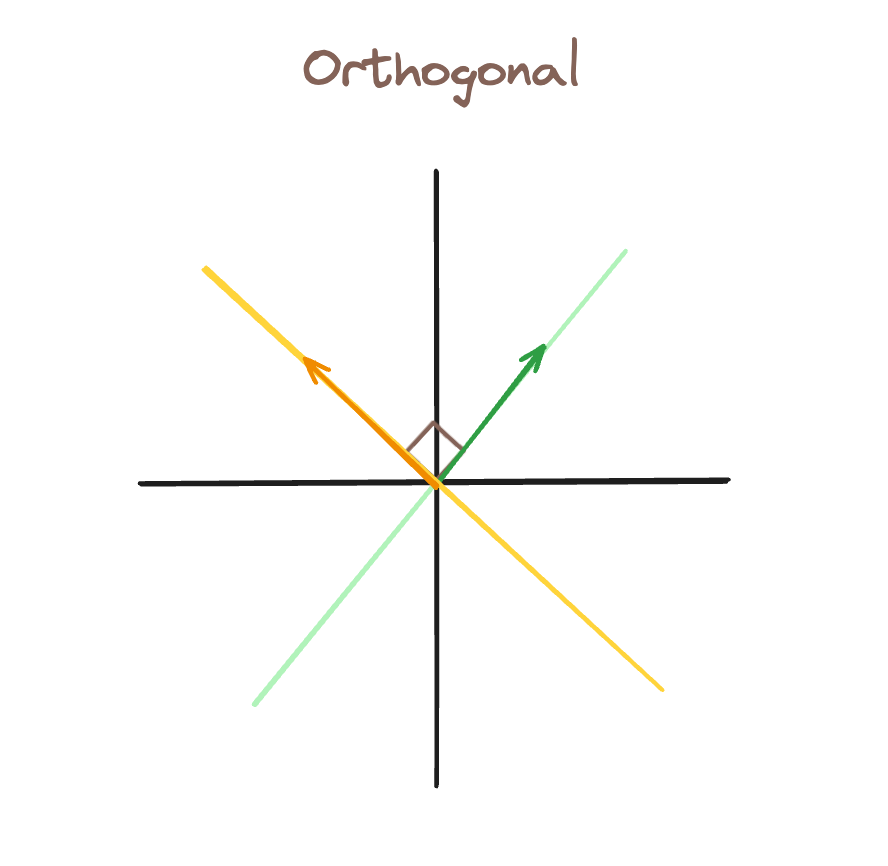
In diesem ersten Bild haben wir orthogonale BasenWenn die grüne Funktion aktiv (es gibt einen Vektor entlang dieser Linie), können wir das darstellen, während wir das gelbe Merkmal immer noch darstellen als inaktiv.

In diesem zweiten Bild haben wir eine dritte Characteristic-Richtung hinzugefügt, blau. Als Ergebnis, wir können nicht haben einen Vektor, bei dem das grüne Characteristic aktiv, das blaue Characteristic jedoch inaktiv ist. Alternativ dazu aktiviert jeder Vektor entlang der grünen Richtung auch die blaue Funktion.
Dies wird durch die gepunkteten grünen Linien dargestellt, die zeigen, wie „aktiviert“ das blaue Characteristic im Vergleich zu unserem grünen Vektor ist (der nur das grüne Characteristic aktivieren sollte).
Aus diesem Grund sind Merkmale in LLMs so schwer zu interpretieren. Wenn Millionen von Merkmalen alle in Überlagerung dargestellt werden, ist es sehr schwierig zu analysieren, welche Merkmale aktiv sind, weil sie etwas bedeuten, und welche einfach aktiv sind, weil Interferenz — wie das blaue Characteristic in unserem vorherigen Beispiel.
Sparse Auto Encoders (Die Lösung)
Aus diesem Grund verwenden wir einen Sparse Auto Encoder (SAE). Der SAE ist ein einfaches neuronales Netzwerk: zwei vollständig verbundene Schichten mit einer ReLu-Aktivierung dazwischen.
Die Idee ist folgende: Die Eingabe für die SAE sind die Modellaktivierungen, und die SAE versucht, diese gleichen Modellaktivierungen in der Ausgabe nachzubilden.
Der SAE wird anhand der Ausgabe der mittleren Schicht des LLM trainiert. Er nimmt die Modellaktivierungen auf, projiziert in einen Zustand höherer Dimension und projiziert dann zurück zu den ursprünglichen Aktivierungen.
Dies wirft die Frage auf: Welchen Sinn haben SAEs, wenn Eingabe und Ausgabe identisch sein sollen?
Die Antwort: Wir möchten, dass die Ausgabe der ersten Ebene unsere Funktionen darstellt.
Aus diesem Grund erhöhen wir die Dimensionalität mit der ersten Schicht (Abbildung vom Aktivierungsraum auf eine größere Dimension). Ziel ist es, die Überlagerung zu entfernen, sodass jedes Merkmal seine eigene orthogonale Richtung erhält.
Wir wollen auch, dass dieser höherdimensionale Raum wenig aktiv. Das heißt, wir wollen jeden Aktivierungspunkt als lineare Kombination von nur wenigen Vektoren darstellen. Diese Vektoren würden im Idealfall dem Wichtigste Eigenschaften innerhalb unseres Inputs.
Wenn wir additionally erfolgreich sind, kodiert die SAE die komplizierten Modellaktivierungen in einen spärlichen Satz aussagekräftiger Merkmale. Wenn diese Merkmale korrekt sind, sollte die zweite Schicht der SAE in der Lage sein, die Merkmale den ursprünglichen Aktivierungen zuzuordnen.
Uns interessiert die Ausgabe der ersten Schicht des SAE — es ist eine Codierung der Modellaktivierungen als spärliche Merkmale.
Als Anthropic additionally das Vorhandensein von Merkmalen anhand von Richtungen im Aktivierungsraum maß und bestimmte Merkmale durch Klammern aktiviert oder deaktivierte, Sie taten dies im verborgenen Zustand der SAE.
Im Beispiel des Einklemmens klemmte Anthropic die Merkmale ein am Ausgang der Schicht 1 des SAEdie damals leicht unterschiedliche Modellaktivierungen. Diese würden dann durch den Vorwärtsdurchlauf des Modells fortgesetzt und eine geänderte Ausgabe erzeugen.
Ich habe diesen Artikel mit einem Zitat von James Harrington begonnen. Die Idee ist einfach: verstehen->kontrollieren->verbessern. Jedes dieser Ziele ist für uns ein sehr wichtiges Ziel für LLMs.
Wir wollen verstehen Unsere beste Vorstellung davon, wie sie das tun, scheint uns die Artwork und Weise zu geben, wie sie sich die Welt vorstellen, und interpretierbare Merkmale als Richtungen zu nutzen.
Wir wollen feiner abgestimmte Kontrolle über LLMs. Die Fähigkeit, zu erkennen, wann bestimmte Funktionen aktiv sind, und ihre Aktivität während der Ausgabegenerierung anzupassen, ist ein fantastisches Software in unserem Werkzeugkasten.
Und schließlich glaube ich, dass es, vielleicht aus philosophischer Sicht, wichtig sein wird, Verbesserung die Leistung von LLMs. Bislang battle das nicht der Fall. Wir konnten LLMs leistungsfähig machen, ohne sie zu verstehen.
Ich bin jedoch davon überzeugt, dass es angesichts der stagnierenden Verbesserungen und der zunehmenden Schwierigkeit, LLMs zu skalieren, wichtig sein wird, ihre Funktionsweise wirklich zu verstehen, wenn wir den nächsten Leistungssprung schaffen wollen.