Ein Crew von Forschern des Instituts für Stiftungsmodelle von MBzuai und G42 veröffentlichte K2 Assume, ist ein offenes Argumentationssystem für fortschrittliche KI-Argumentation mit 32B-Parametern. Es kombiniert die überdachten, überdachten Feinabstimmungen mit Verstärkungslernen aus nachprüfbaren Belohnungen, Agentenplanung, Testzeitskalierung und Inferenzoptimierungen (spekulative Dekodierung + Wafer-Scale-{Hardware}). Das Ergebnis ist die mathematische Leistung auf Grenzebene mit deutlich niedrigerer Parameterzahl und Wettbewerbsergebnissen zu Code und Wissenschaft-mit einer transparenten, vollständig geöffneten Launch-Spannung, Daten und Code.
Systemübersicht
K2 Assume wird nach dem Coaching eines Open-Gewichts-QWEN2.5-32B-Basismodells und dem Hinzufügen eines leichten Testzeit-Rechengerüsts für Testzeiten erstellt. Das Design betont die Parameter-Effizienz: Ein 32B-Rückgrat wird absichtlich ausgewählt, um eine schnelle Iteration und den Einsatz zu ermöglichen und gleichzeitig die Kopffreiheit für die Nachtraining zu erhalten. Das Kernrezept kombiniert sechs „Säulen“: (1) Lengthy-Kette (COT) beaufsichtigte Feinabstimmung; (2) Verstärkungslernen mit überprüfbaren Belohnungen (RLVR); (3) Agentenplanung vor dem Lösen; (4) Testzeitskalierung durch Finest-of-N-Auswahl mit Überprüfern; (5) spekulative Decodierung; und (6) Schlussfolgerung auf einem Wafermotor.
Die Ziele sind unkompliziert: Erhöhen Sie Go@1 für mathematische Benchmarks von Wettbewerbsgraden, behalten Sie eine starke Code-/Wissenschaftsleistung bei und halten Sie die Reaktionslänge und die Latenz des Wand-Clocks unter Kontrolle durch Plan-you-Assume-Aufforderung und {Hardware}-Wahrnehmungs-Inferenz.
Säule 1: Langes Kinderbett sft
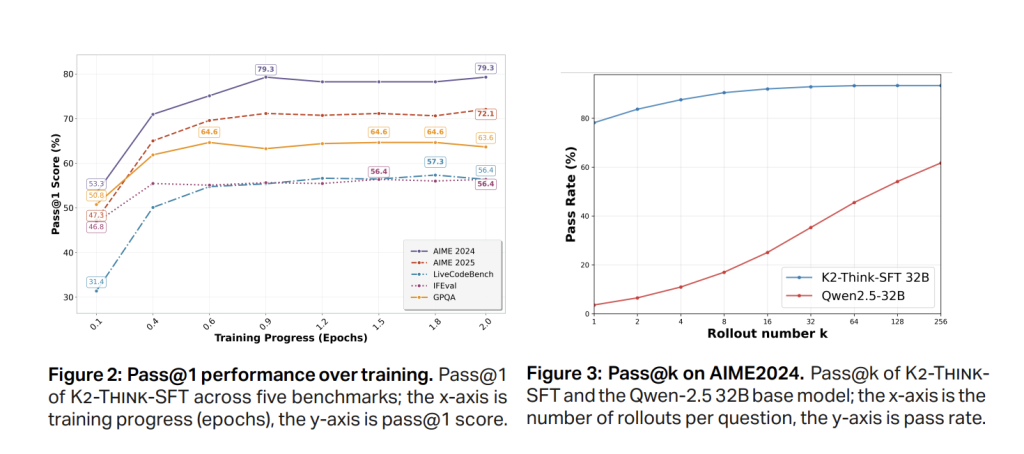
Section-1 SFT verwendet kuratierte, langgedachte Spuren und Anweisungs-/Antwortpaare, die sich mit Mathematik, Code, Wissenschaft, Anweisungen und allgemeinem Chat befinden (AM-Dinking-V1-destilliert). Der Effekt besteht darin, das Basismodell zur Externalisierung von Intermediate -Argumentation zu lehren und ein strukturiertes Output -Format anzunehmen. Schnellpass bei 1 Zuwächsen treten früh (~ 0,5 Epoche) auf, wobei Aime’24 rund ~ 79% und Aime’25 auf dem SFT -Checkpoint vor RL stabilisiert, was auf Konvergenz hinweist.
Säule 2: RL mit nachweisbaren Belohnungen
K2 denken dann, dann trainiert mit RLVR auf GuruA ~ 92K-Immediate, Sechs-Domänen-Datensatz (Mathematik, Code, Wissenschaft, Logik, Simulation, tabellarisch) für nachweisbare Finish-to-Finish-Korrektheit. Die Implementierung verwendet die Verl Bibliothek mit einem GRPO-Stil-Richtlinie-Gradientenalgorithmus. Bemerkenswerte Beobachtung: RL von a starten stark Der SFT-Checkpoint ergibt bescheidene absolute Gewinne und kann Plateau/Degenerate degeneriert, während das gleiche RL-Rezept direkt auf das Basismodell große relative Verbesserungen zeigt (z. B. ~ 40% auf Aime’24 über das Coaching), was einen Kompromiss zwischen SFT-Stärke und RL-Koparaum unterstützt.
Eine zweite Ablation zeigt mehrstufige RL mit einem reduzierten anfänglichen Kontextfenster (z. B. 16K → 32K) unterdurchschnittlich-Fassungen zur Wiederherstellung der SFT-Basislinie-, um die Reduzierung der maximalen Sequenzlänge unter dem SFT-Regime zu korrigieren, kann gelernte Argumentationsmuster stören.
Säulen 3–4: Agentin „Plan-vor-vor-you-dinke“ und Testzeitskalierung
Bei Inferenz löst das System zunächst einen Kompakt aus planen Vor der Erzeugung einer vollständigen Lösung führt dann die Finest-of-N-(z. B. n = 3) Probenahme mit Überprüfern durch, um die wahrscheinlichste korrekte Antwort auszuwählen. Es werden zwei Effekte berichtet: (i) konstante Qualitätsgewinne aus dem kombinierten Gerüst; und (ii) kürzer Die endgültigen Antworten trotz des zusätzlichen Planes-Durchschnitts-Token-Zählungen sinken über Benchmarks, wobei sich um bis zu ~ 11,7% (z. B. Omni-Laborious) und Gesamtlängen vergleichbar mit viel größeren offenen Modellen vergleichbar sind. Dies ist sowohl für die Latenz als auch für die Kosten von Bedeutung.
Die Analyse der Tabellenebene zeigt, dass K2 Thinks Antwortlängen sind kürzer als qwen3-235b-a22b und im gleichen Bereich wie GPT-OSS-120B in Mathematik; Nach dem Hinzufügen von Plan-vor-you-Assume und Verifikatoren fallen K2-Assume-durchschnittliche Token gegenüber seinem eigenen Kontrollpunkt nach dem Coaching (z. B. Aime’24 –6,7%, Aime’25 –3,9%, Hmmt25 –7,2%, Omni-hard -11,7%, LCBV5 –10,5%, GPQA-21%).
Säulen 5–6: Spekulative Dekodierung und Inferenz im Wafer im Wafer im Bereich
K2 denken Sie an Ziele Cerebras Wafer-Scale-Motor Schlussfolgerung mit Spekulative DekodierungWerbung professional Equest-Durchsatz vorwärts von 2.000 Token/Sekwas das Testzeit-Gerüst für Produktions- und Forschungsschleifen praktisch macht. Der {Hardware}-bewusstes Inferenzweg ist ein zentraler Bestandteil der Veröffentlichung und richtet sich an die „kleine, aber schnelle“ Philosophie des Methods.
Bewertungsprotokoll
Benchmarking deckt die Mathematik auf Wettbewerbsebene (Aime’24, Aime’25, HMMT’25, Omni-Math-Laborious), Code (LiveCodeBench V5; Scicode Sub/Predominant) und wissenschaftliches Wissen/Argument (GPQA-Diamond; HLE) ab. Das Forschungsteam meldet ein standardisiertes Setup: MAX-Generierungslänge 64K-Token, Temperatur 1,0, High-P 0,95, Stoppmarker </reply>und jede Punktzahl als Durchschnitt von 16 Impartial Go@1 Bewertungen zur Reduzierung der Lauf-zu-Run-Varianz.
Ergebnisse
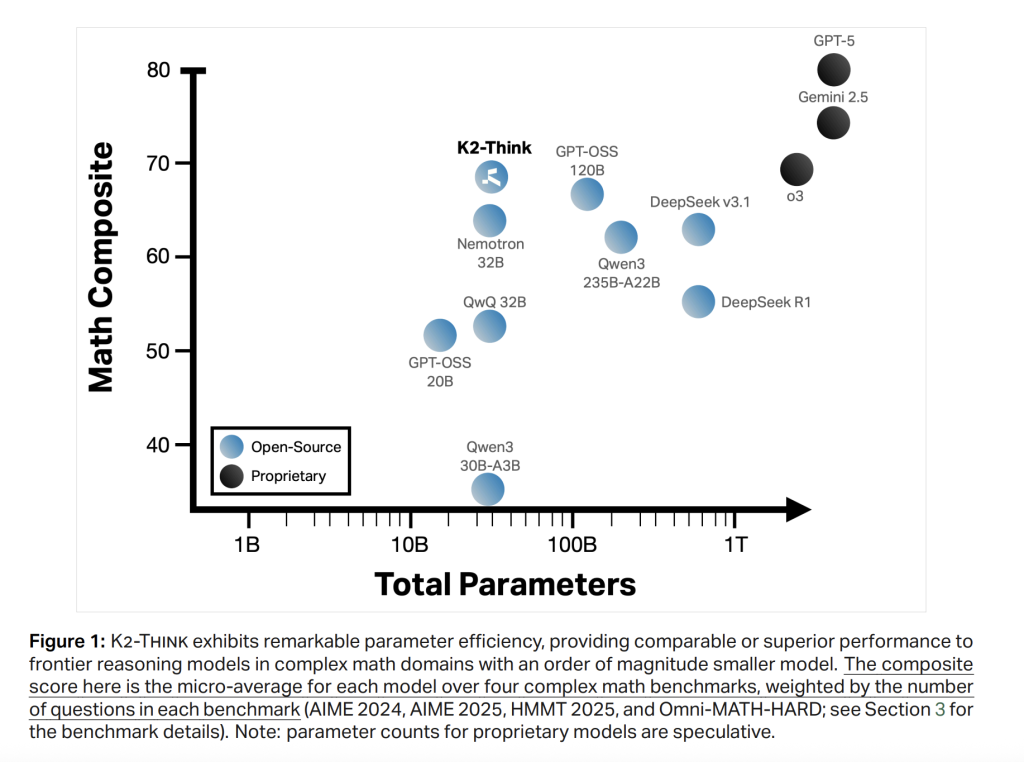
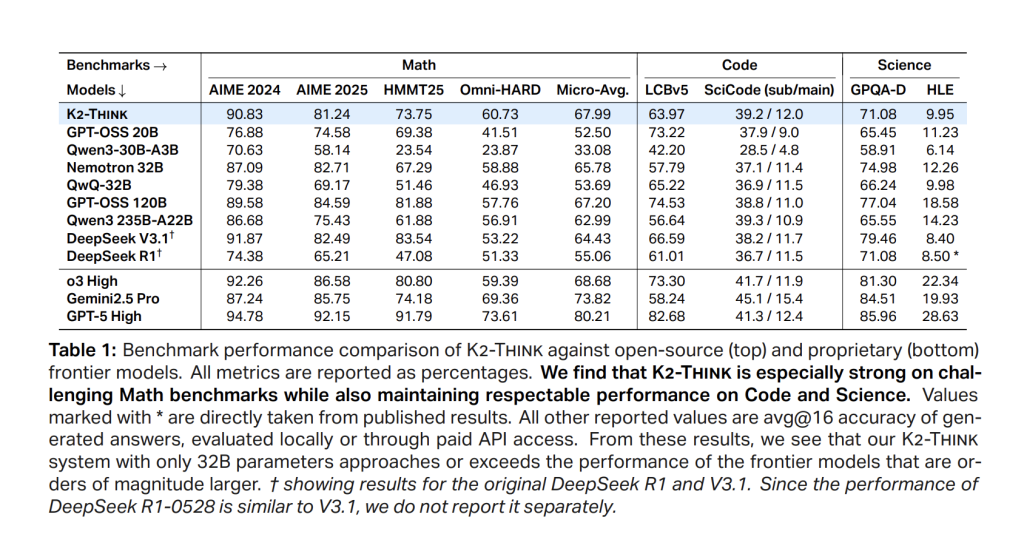
Mathematik (Mikro-Durchschnitt in Aime’24/’25, Hmmt25, Omni-Laborious). K2 denkt, erreicht 67.99die Open-Gewicht-Kohorte führen und sogar mit viel größeren Systemen positiv verglichen; Es postet 90.83 (Aime’24), 81.24 (Aime’25), 73,75 (Hmmt25) und 60.73 Auf Omni-Laborious-letzteres ist die schwierigste Trennung. Die Positionierung stimmt mit einer starken Parameter-Effizienz im Vergleich zu Deepseek V3.1 (671b) und GPT-OSS-120B (120B) überein.
Code. LivecodeBench V5 Rating ist 63,97überschreiten ähnlich große Gleichaltrige und sogar größere offene Modelle (z. B.> QWEN3-235B-A22B bei 56,64). Auf Scicode denken K2, ist 39.2/12.0 (Sub/Predominant), verfolgen Sie die besten offenen Systeme genau in der Genauigkeit der Teilprobleme.
Wissenschaft. Gpqa diamond erreicht 71.08; Hle ist 9.95. Das Modell ist nicht nur ein Mathematikspezialist: Es bleibt wettbewerbsfähig über wissensfreundliche Aufgaben.

Schlüsselzahlen auf einen Blick
- Rückgrat: Qwen2.5-32b (offenes Gewicht), nach Ausbildung mit langem Cot SFT + RLVR (GRPO über Verl).
- RL -Daten: Guru (~ 92K -Eingabeaufforderungen) über Math/Code/Science/Logic/Simulation/Tabelle hinweg.
- Inferenzgerüst: Plan-vor-you-dink + Bon mit Überprüfern; Kürzere Ausgänge (z. B. –11,7% Token für Omni-Laborious) bei höherer Genauigkeit.
- Durchsatzziel: ~2.000 TOK/s auf Cerebras WSE mit spekulativer Dekodierung.
- Math Micro-AVG: 67.99 (Aime’24 90.83Aime’25 81.24Hmmt’25 73,75Omni-hard 60.73).
- Code/Wissenschaft: LCBV5 63,97; Scicode 39.2/12.0; Gpqa-d 71.08; HLE 9.95.
- Sicherheit-4-Makro: 0,75 (Ablehnung 0,83, Conv. Robustheit 0,89, Cybersicherheit 0,56, Jailbreak 0,72).
Zusammenfassung
K2 denkt, das zeigt das Integrative Nach-Coaching + Testzeit Compute + {Hardware}-bewusstes Inferenz kann einen Großteil der Lücke zu größeren, proprietären Argumentationssystemen schließen. Bei 32B ist es zugunsten und dienen; Mit Plan-vor-you-Assume und Bon-mit-Erweiteren kontrolliert es die Token-Budgets. Mit spekulativen Dekodierung auf {Hardware} im Wafermaßstab erreicht es ~ 2k Tok/s professional Anfrage. K2 -Denken wird als a präsentiert Voll offen System-Gewichte, Trainingsdaten, Bereitstellungscode und Testzeitoptimierungscode.
Schauen Sie sich das an PapierAnwesend Modell auf Umarmtes GesichtAnwesend Github Und Direkter Zugang. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser Publication.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.