Das Drawback mit „länger denken“
Großsprachenmodelle haben beeindruckende Fortschritte beim mathematischen Denken gemacht, indem sie ihre Kettenprozesse (COT) (COT) erweitert-im Wesentlichen „länger durch detailliertere Argumentationsschritte denken“. Dieser Ansatz hat jedoch grundlegende Einschränkungen. Wenn Modelle auf subtile Fehler in ihren Argumentationsketten stoßen, verschärfen sie diese Fehler häufig eher, als sie zu erkennen und zu korrigieren. Die interne Selbstreflexion schlägt häufig fehl, insbesondere wenn der anfängliche Argumentationsansatz grundsätzlich fehlerhaft ist.
Der neue Forschungsbericht von Microsoft führt den RSTAR2-Agent ein, der einen anderen Ansatz verfolgt: Anstatt nur länger zu denken, lehrt es Modelle, um klüger zu denken, indem sie aktiv Coding-Instruments verwenden, um ihren Argumentationsprozess zu überprüfen, zu erforschen und zu verfeinern.
Der agentenansatz
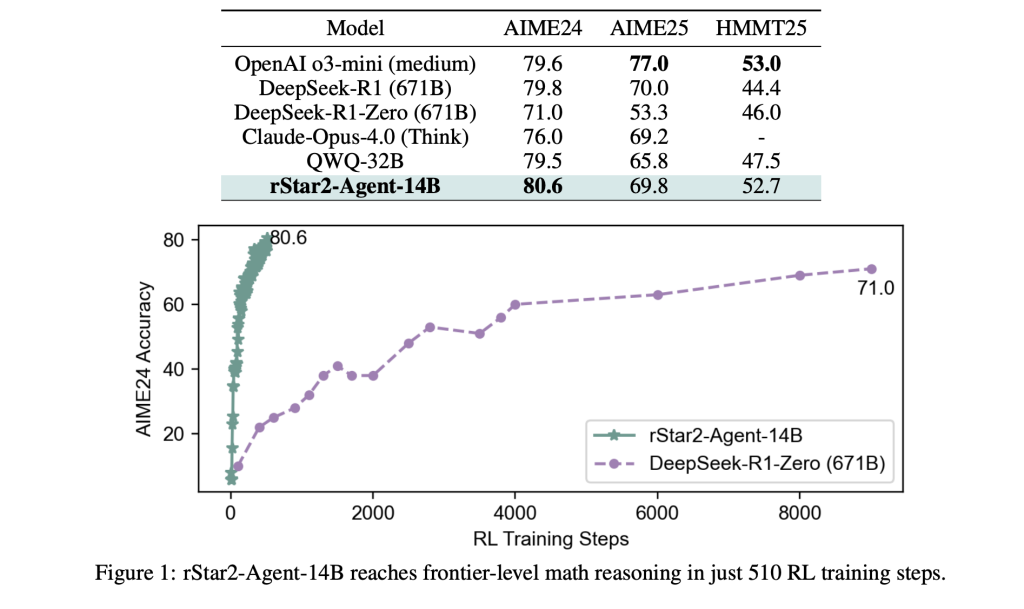
RStar2-Agent stellt eine Verschiebung in Richtung Agentenverstärkungslernen dar, bei dem ein 14B-Parametermodell während seines Überlegungsverfahrens mit einer Python-Ausführungsumgebung interagiert. Anstatt sich ausschließlich auf die interne Reflexion zu verlassen, kann das Modell Code schreiben, ihn ausführen, die Ergebnisse analysieren und seinen Ansatz basierend auf konkreter Suggestions anpassen.
Dies schafft einen dynamischen Prozess zur Problemlösung. Wenn das Modell auf ein komplexes mathematisches Drawback stößt, kann es anfängliches Denken erzeugen, Python -Code schreiben, um Hypothesen zu testen, die Ausführungsergebnisse zu analysieren und eine Lösung zu iterieren. Der Ansatz spiegelt wider, wie menschliche Mathematiker häufig funktionieren – und Rechenwerkzeuge verwendet, um Intuitionen zu überprüfen und verschiedene Lösungswege zu erforschen.
Infrastrukturherausforderungen und Lösungen
Die Skalierungsvertreterin präsentiert erhebliche technische Hürden. Während des Trainings kann ein einzelner Cost Zehntausende von gleichzeitigen Code -Ausführungsanforderungen erzeugen und Engpässe erstellen, die die GPU -Nutzung zum Stillstand bringen können. Die Forscher befassten sich mit zwei wichtigen Infrastrukturinnovationen.
Zunächst erstellten sie einen verteilten Code-Ausführungsdienst, mit dem 45.000 gleichzeitige Software-Anrufe mit der Latenz von Untersekunden behandelt werden können. Das System isoliert die Codeausführung aus dem Haupttrainingsprozess und hält gleichzeitig einen hohen Durchsatz durch sorgfältige Lastausgleich über CPU -Mitarbeiter.
Zweitens entwickelten sie einen dynamischen Rollout-Scheduler, der rechnerische Arbeiten basierend auf der Verfügbarkeit von GPU-Cache-Cache-Echtzeit und nicht der statischen Zuordnung zuteilt. Dies verhindert die Leerlaufzeit der GPU, die durch eine ungleiche Arbeitsbelastungsverteilung verursacht wird – ein häufiges Drawback, wenn einige Argumentationsspuren eine erhebliche Berechnung erfordern als andere.
Diese Verbesserungen in der Infrastruktur ermöglichten es dem gesamten Trainingsprozess in nur einer Woche mit 64 AMD MI300X-GPUs ab, was demonstriert, dass Argumentationsfunktionen auf Grenzebene keine massiven Rechenressourcen erfordern, wenn sie effizient orchestriert werden.
GRPO-ROC: Lernen aus hochwertigen Beispielen
Die zentrale algorithmische Innovation ist die relative Richtlinienoptimierung der Gruppenpolitik mit Resampling bei Appropriate (GRPO-ROC). Das traditionelle Verstärkungslernen in diesem Zusammenhang steht vor einem Qualitätsproblem: Modelle erhalten constructive Belohnungen für korrekte endgültige Antworten, selbst wenn ihr Argumentationsprozess mehrere Codefehler oder ineffiziente Toolbenutzung enthält.
GRPO-ROC befasst sich mit der Implementierung einer asymmetrischen Stichprobenstrategie. Während des Trainings der Algorithmus:
- Überabstiel Erste Rollouts, um einen größeren Pool von Argumentationsspuren zu erzeugen
- Bewahrt die Vielfalt In fehlgeschlagenen Versuchen, das Lernen aus verschiedenen Fehlermodi aufrechtzuerhalten
- Filter constructive Beispiele Spuren mit minimalen Werkzeugfehlern und sauberer Formatierung hervorheben
Dieser Ansatz stellt sicher, dass das Modell aus hochwertigem erfolgreichem Denken lernt und gleichzeitig unterschiedliche Versagensmuster ausgesetzt ist. Das Ergebnis ist ein effizienterer Werkzeugverbrauch und kürzere, fokussiertere Argumentationsspuren.
Trainingsstrategie: von einfach zu komplex
Der Trainingsprozess entfaltet sich in drei sorgfältig gestalteten Phasen, beginnend mit der nicht erschwinglichen, beaufsichtigten Feinabstimmung, die sich nur auf die Anweisungen und die Werkzeugformatierung konzentriert und komplexe Argumentationsbeispiele vermeiden kann, die möglicherweise vorzeitige Vorurteile erzeugen könnten.
Stufe 1 schränkt die Antworten auf 8.000 Token ein und zwingt das Modell, prägnante Argumentationsstrategien zu entwickeln. Trotz dieser Einschränkung springt die Leistung dramatisch-von nahezu Null auf über 70% bei herausfordernden Benchmarks.
Stufe 2 Erweitert die Token -Grenze auf 12.000 und ermöglicht eine komplexere Argumentation, während die Effizienzgewinne aus der ersten Stufe beibehalten werden.
Stufe 3 Verschiebungen konzentrieren sich auf die schwierigsten Probleme, indem sie diejenigen herausfiltern, die das Modell bereits gemeistert hat, und sicherzustellen, dass durch herausfordernde Fälle kontinuierliches Lernen festgelegt wird.
Dieser Fortschreiten von prägnant bis zu erweitertem Denken in Kombination mit zunehmenden Problemschwierigkeiten maximiert die Lerneffizienz und minimiert gleichzeitig den Rechenaufwand.
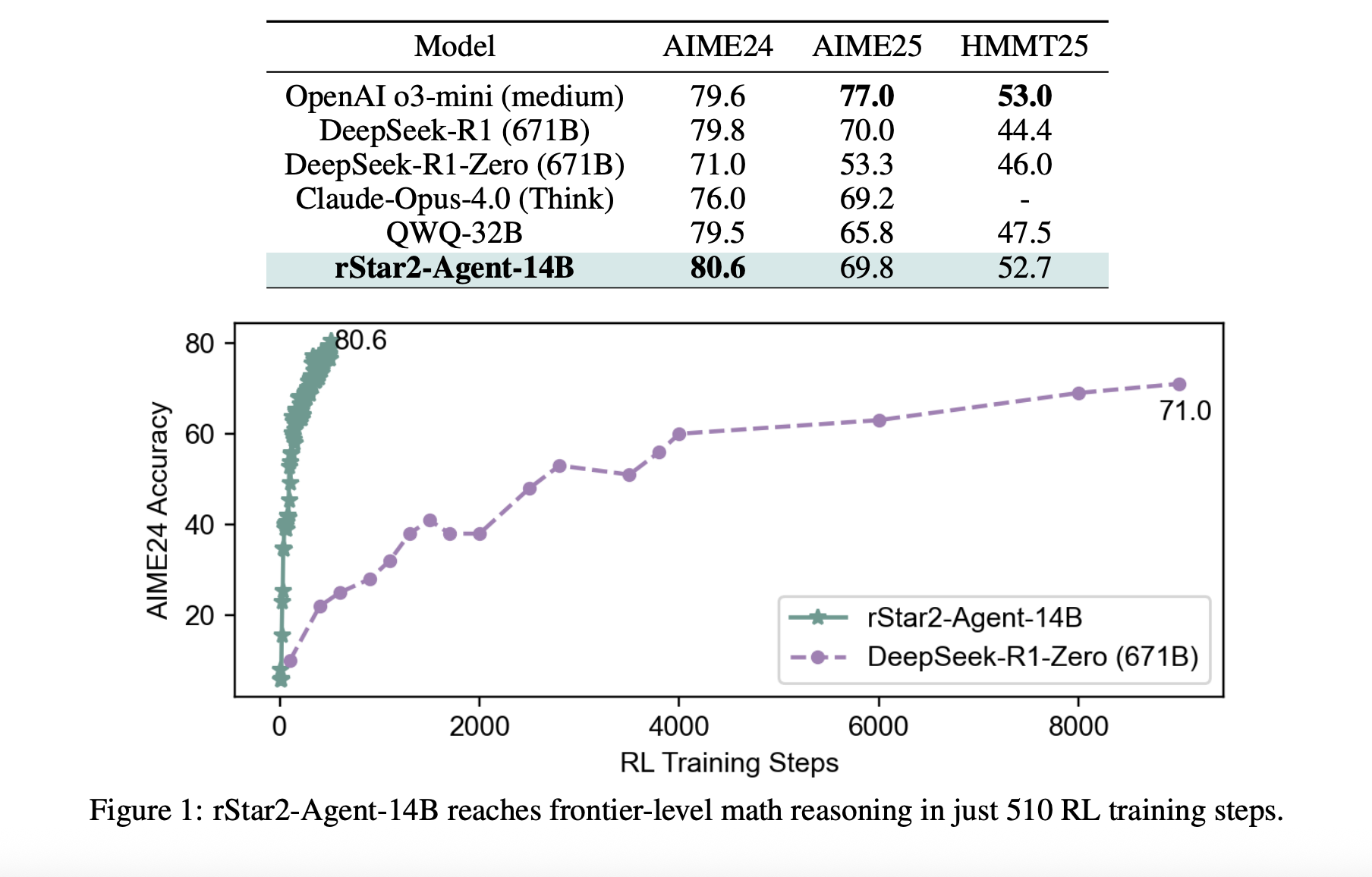
Durchbruchsergebnisse
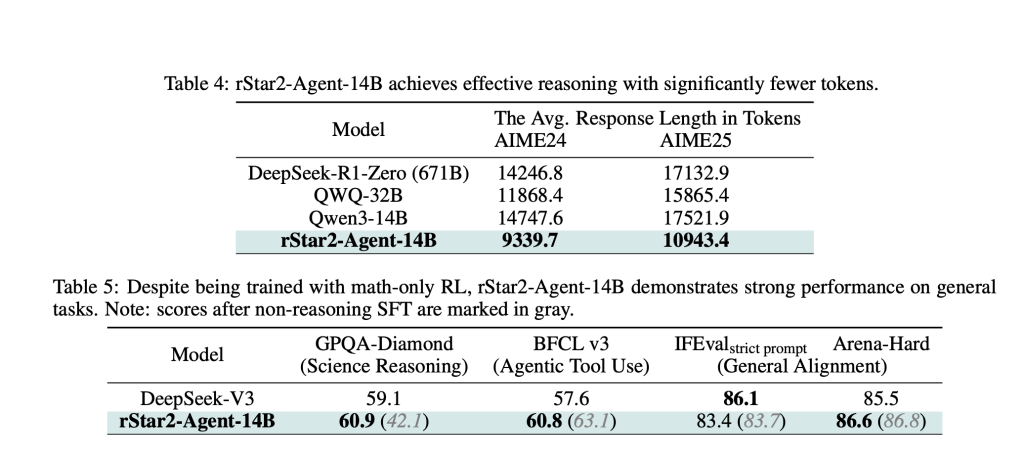
Die Ergebnisse sind auffällig. RSTAR2-Agent-14b erreicht AIME24 und 69,8% für Aime25 80,6% Genauigkeit und übertrifft viel größere Modelle, einschließlich des 671B-Parameteres Deepseek-R1. Vielleicht noch wichtiger ist, dass es dies mit deutlich kürzeren Argumentationsspuren erreicht – rund 10.000 Token im Vergleich zu über 17.000 für vergleichbare Modelle.
Die Effizienzgewinne gehen über die Mathematik hinaus. Trotz der Ausbildung ausschließlich zu mathematischen Problemen zeigt das Modell ein starkes Transferlernen, übertrifft spezialisierte Modelle für wissenschaftliche Argumentationsbenchmarks und die Aufrechterhaltung der Wettbewerbsleistung bei allgemeinen Ausrichtungsaufgaben.
Die Mechanismen verstehen
Die Analyse des geschulten Modells zeigt faszinierende Verhaltensmuster. Hoch-entropische Token in Argumentationsspuren fallen in zwei Kategorien: traditionelle „Gabing-Token“, die Selbstreflexion und Erkundung auslösen, und eine neue Kategorie von „Reflexions-Token“, die speziell als Reaktion auf Software-Suggestions auftreten.
Diese Reflexionstoken stellen eine Type des umgebungsgesteuerten Denkens dar, in dem das Modell die Codeausführungsergebnisse sorgfältig analysiert, Fehler diagnostiziert und seinen Ansatz entsprechend anpasst. Dies schafft ein ausgefeilteres Verhalten von Problemlösungen, als das Argumentieren von reinem Kinderbett erreichen kann.
Zusammenfassung
RStar2-Agent zeigt, dass Modelle mit mittlerer Größe durch ein ausgefeiltes Coaching anstelle von Brute-Drive-Skalierung von Grenzniveau führen können. Der Ansatz schlägt einen nachhaltigeren Weg in Richtung fortschrittlicher KI -Funktionen vor – eine, die die Effizienz-, Werkzeugintegrations- und intelligente Trainingsstrategien gegenüber der Rechenleistung im Rahmen der Rechenleistung hervorhebt.
Der Erfolg dieses Agentenansatzes weist auch auf zukünftige KI-Systeme hin, die mehrere Instruments und Umgebungen nahtlos integrieren können und über die statische Textgenerierung hinaus in Richtung dynamischer, interaktiver Problemlösungsfunktionen übertragen werden.
Schauen Sie sich das an Papier Und Github -Seite. Fühlen Sie sich frei, unsere zu überprüfen Github -Seite für Tutorials, Codes und Notizbücher. Fühlen Sie sich auch frei, uns zu folgen Twitter Und vergessen Sie nicht, sich unserer anzuschließen 100k+ ml Subreddit und abonnieren Unser Publication.
Asif Razzaq ist der CEO von Marktechpost Media Inc. Sein jüngstes Bestreben ist die Einführung einer Medienplattform für künstliche Intelligenz, Marktechpost, die sich durch die ausführliche Berichterstattung über maschinelles Lernen und Deep-Studying-Nachrichten auszeichnet, die von einem breiten Publikum technisch intestine und leicht verständlich sind. Die Plattform verfügt über über 2 Millionen monatliche Ansichten und veranschaulicht ihre Beliebtheit des Publikums.