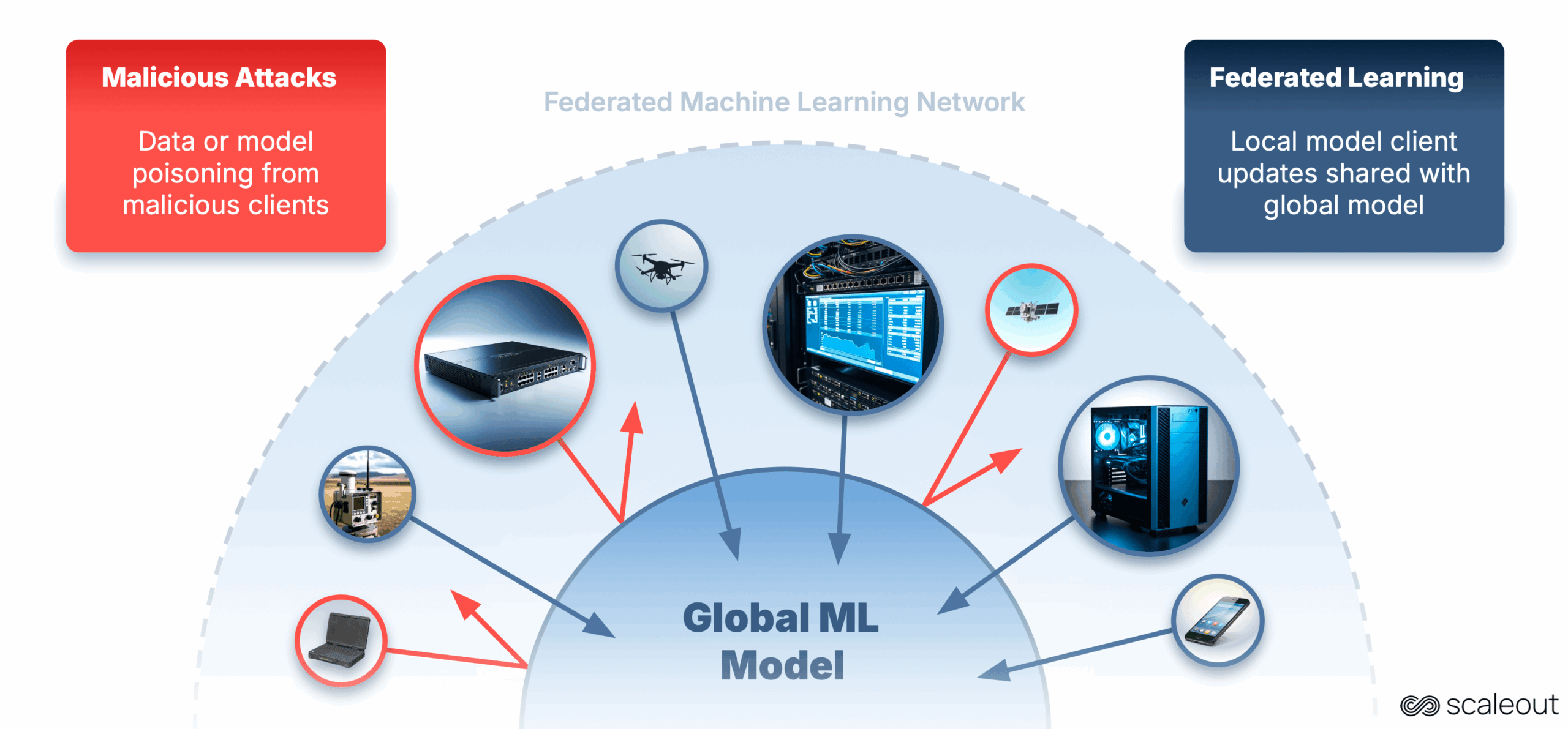
Föderierte Lernen (FL) trainieren wir AI -Modelle. Anstatt alle Ihre sensiblen Daten an einen zentralen Standort zu senden, hält FL die Daten dort, wo sie sich befinden, und teilen nur Modellaktualisierungen. Dies bewahrt die Privatsphäre und ermöglicht es KI, näher an den Daten zu rennen, wo die Daten generiert werden.
Bei Berechnung und Daten auf vielen Geräten entstehen jedoch neue Sicherheitsherausforderungen. Angreifer können sich dem Trainingsprozess anschließen und auf subtile Weise beeinflussen, was zu einer erneuten Genauigkeit, voreingenommenen Outputs oder versteckten Hinterhalten im Modell führt.
In diesem Projekt haben wir untersucht, wie wir solche Angriffe in FL erkennen und mildern können. Zu diesem Zweck haben wir einen Multi -Node -Simulator erstellt, mit dem Forscher und Fachleute der Industrie Angriffe reproduzieren und die Verteidigung effizienter testen können.
Warum ist das wichtig
- Ein nichttechnisches Beispiel: Denken Sie an ein gemeinsames Rezeptbuch, zu dem Köche aus vielen Eating places beitragen. Jeder Koch aktualisiert einige Rezepte mit eigenen Verbesserungen. Ein unehrlicher Koch konnte absichtlich die falschen Zutaten hinzufügen, um das Gericht zu sabotieren oder leise einen speziellen Geschmack einfügen, den nur sie wissen, wie man repariert. Wenn niemand die Rezepte sorgfältig überprüft, könnten alle zukünftigen Gäste in allen Eating places ruinierte oder manipulierte Mahlzeiten enden.
- Ein technisches Beispiel: Das gleiche Konzept erscheint in FL als Datenvergiftung (Manipulation Coaching Beispiele) und Modellvergiftung (Änderung der Gewichtsaktualisierungen). Diese Angriffe sind besonders schädlich, wenn die Föderation über nicht IID -Datenverteilungen, unausgeglichene Datenpartitionen oder verspätete Kunden verfügt. Zeitgenössische Verteidigung wie z. Multi KrumAnwesend Mitgeschnittenen Mittelwert Und Dividieren und erobern kann in bestimmten Szenarien immer noch scheitern.
Erstellen des Multi -Knoten -FL -Angriffssimulators
Um die Widerstandsfähigkeit des Federated-Lernens gegen reale Bedrohungen zu bewerten, haben wir einen Multi-Knoten-Angriffssimulator über dem erstellt Skala -System Fedn Framework. Dieser Simulator ermöglicht es, Angriffe zu reproduzieren, Abwehrkräfte zu testen und Experimente mit Hunderten oder sogar Tausenden von Kunden in einer kontrollierten Umgebung zu skalieren.
Schlüsselfunktionen:
- Versatile Bereitstellung: Läuft verteilte FL -Jobs mit Kubernetes, Helm und Docker.
- Realistische Dateneinstellungen: Unterstützt IID/Nicht-IID-Etikettenverteilungen, unausgewogene Datenpartitionen und verspätet bei den Shoppers.
- Angriffsinjektion: Beinhaltet die Implementierung gemeinsamer Vergiftungsangriffe (Label Flipping, wenig reicht aus) und ermöglicht es, neue Angriffe mit Leichtigkeit zu definieren.
- Verteidigungsbenchmarking: Integriert vorhandene Aggregationsstrategien (Fedavg, Trimmed Imply, Multi-Krum, Divide und Eroberung) und ermöglicht das Experimentieren und Testen einer Reihe von Verteidigungsstrategien und Aggregationsregeln.
- Skalierbares Experimentieren: Simulationsparameter wie die Anzahl der Shoppers, die böswillige Freigabe und die Teilnahmemuster können von einer einzelnen Konfigurationsdatei eingestellt werden.
Verwendung Fedns Architektur bedeutet, dass die Simulationen von der robusten Schulungsorchestrierung und dem Kundenmanagement profitieren und die visuelle Überwachung über die ermöglichen Studio -Weboberfläche.
Es ist auch wichtig zu beachten, dass das Fedn -Framework unterstützt Serverfunktionen. Diese Funktion ermöglicht es, neue Aggregationsstrategien zu implementieren und sie mit dem Angriffssimulator zu bewerten.
Um mit dem ersten Beispielprojekt mit Fedn zu beginnen, Hier ist der QuickStart Information.
Der Fedn -Rahmen ist für alle akademischen und Forschungsprojekte sowie für Industrieprüfung und Versuche kostenlos.
Der Angriffssimulator ist verfügbar und als Open -Supply -Software program bereit.
Die Angriffe, die wir studiert haben
- Beschriftung Flipping (Datenvergiftung) – Bösartige Kunden drehen Etiketten in ihren lokalen Datensätzen auf, wie z. B. „Katze“ in „Hund“, um die Genauigkeit zu verringern.
- Wenig ist genug (Modellvergiftung) – Angreifer nehmen kleine, aber gezielte Anpassungen ihrer Modellaktualisierungen vor, um die globale Modellausgabe auf ihre eigenen Ziele zu verändern. In dieser These haben wir die Kleine angewendet, die jede dritte Runde ausreicht.
Jenseits der Angriffe – Verständnis für unbeabsichtigte Auswirkungen
Während sich diese Studie auf absichtliche Angriffe konzentriert, ist sie gleichermaßen wertvoll, um die Auswirkungen marginaler Beiträge zu verstehen, die durch Misskonfigurationen oder Gerätefehlfunktionen in großen Verbänden verursacht werden.
In unserem Rezeptbeispiel kann selbst ein ehrlicher Koch versehentlich die falsche Zutat verwenden, da sein Ofen gebrochen ist oder seine Skala ungenau ist. Der Fehler ist unbeabsichtigt, aber er verändert das gemeinsame Rezept immer noch auf eine Weise, die schädlich sein könnte, wenn sie von vielen Mitwirkenden wiederholt werden.
In Cross-System- oder Flotten-Lern-Setups, bei denen Tausende oder Millionen heterogener Geräte zu einem gemeinsamen Modell beitragen, können fehlerhafte Sensoren, veraltete Konfigurationen oder instabile Verbindungen die Modellleistung auf ähnliche Weise wie böswillige Angriffe beeinträchtigen. Das Studium der Belastbarkeit der Angriffe zeigt auch, wie die Aggregationsregeln für solch unbeabsichtigte Lärm sturdy werden können.
Minderungsstrategien erklärt
In FL entscheiden die Aggregationsregeln, wie Sie Modellaktualisierungen von Kunden kombinieren. Robuste Aggregationsregeln zielen darauf ab, den Einfluss von Ausreißern zu verringern, sei es durch böswillige Angriffe oder fehlerhafte Geräte. Hier sind die Strategien, die wir getestet haben:
- Fedavg (Grundlinie) – Durchschnittlich alle Aktualisierungen ohne Filterung. Sehr anfällig für Angriffe.
- MEGEL (TRMEAN) – Sortiert jeden Parameter über Shoppers hinweg und verwirft dann die höchsten und niedrigsten Werte vor der Mittelung. Reduziert excessive Ausreißer, kann aber subtile Angriffe verpassen.
- Multi Krum – bewertet jedes Replace, indem es an seinen nächsten Nachbarn im Parameterraum liegt und nur diejenigen mit der kleinsten Gesamtentfernung behält. Sehr empfindlich auf die Anzahl der ausgewählten Aktualisierungen (Okay).
- EE beschnittene Mittelwert (neu entwickelt) – Eine adaptive Model von TRMEAN, die Epsilon -Grasping -Planung verwendet, um zu entscheiden, wann verschiedene Shopper -Teilmengen getestet werden sollen. Widerstandsfähiger gegen sich ändernde Kundenverhalten, verspätete Ankünfte und Nicht -IID -Verteilungen.
In diesem Beitrag präsentierten Tabellen und Handlungen wurden ursprünglich vom Scaleout -Group entworfen.
Experimente
In 180 Experimenten haben wir verschiedene Aggregationsstrategien unter verschiedenen Angriffstypen, böswilligen Kundenverhältnissen und Datenverteilungen bewertet. Für weitere Particulars lesen Sie bitte die Vollständige These hier .

Die obige Tabelle zeigt eine der Experimentenreihen mit einem Label-Flipping-Angriff mit nicht-IID-Etiketten verteilt und teilweise unausgeglichener Datenpartitionen. Die Tabelle zeigt Testgenauigkeit Und Testverlust AUCberechnet über alle teilnehmenden Shoppers. Die Ergebnisse jeder Aggregationsstrategie werden in zwei Zeilen gezeigt, die den beiden entsprechen Spätpolitik (Gutartige Kunden, die aus der 5. Runde teilnehmen oder schädliche Kunden, die aus der 5. Runde teilnehmen). Spalten trennen die Ergebnisse in den drei böswilligen Proportionen und ergeben sechs Experimentkonfigurationen professional Aggregationsstrategie. Das beste Ergebnis in jeder Konfiguration wird in angezeigt deutlich.
Während die Tabelle eine relativ homogene Reaktion in allen Verteidigungsstrategien zeigt, bieten die einzelnen Diagramme eine völlig andere Ansicht. Obwohl eine Föderation ein gewisses Maß an Genauigkeit erreichen kann, ist es gleichermaßen wichtig, die Kundenbeteiligung zu untersuchen – insbesondere, die Kunden erfolgreich zur Schulung beigetragen haben und die als böswillig abgelehnt wurden. Die folgenden Grundstücke veranschaulichen die Teilnahme der Kunden unter verschiedenen Verteidigungsstrategien.

Mit 20% böswilligen Kunden unter einem Label-Flipper-Angriff auf nicht-iid, teilweise unausgewogene Daten, beschnittene Mittelwert (Fig. 1) Die Gesamtgenauigkeit aufrechterhalten, aber keinen Kunden vollständig von Beitrag zu tragen. Während die Koordinatentrennung die Auswirkungen böswilliger Updates verringerte, fiel es die Parameter einzeln, anstatt ganze Kunden auszuschließen, wodurch sowohl gutartige als auch böswillige Teilnehmer während des gesamten Trainings in der Aggregation bleiben können.
In einem Szenario mit 30% verspäteten böswilligen Kunden und nicht-IID-Daten, Multi-Krum (nicht iid, unausgeglichene DatenAbb. 2) Wählte fälschlicherweise ein böswilliges Replace von Runde 5 aus. Hohe Datenheterogenität ließen gutartige Aktualisierungen weniger ähnlich erscheinen, sodass das böswillige Replace als eines der zentralsten und anhaltendsten in einem Drittel des aggregierten Modells für den Relaxation des Trainings anhält.

Warum wir adaptive Aggregationsstrategien brauchen
Bestehende robuste Aggregationsregeln beruhen im Allgemeinen auf statischen Schwellenwerten, um zu entscheiden, welches Shopper -Replace in die Aggregation des neuen globalen Modells einbezogen wird. Dies unterstreicht einen Mangel der aktuellen Aggregationsstrategien, mit denen sie für spät teilnehmende Kunden, Nicht-IID-Datenverteilungen oder Datenvolumen-Ungleichgewichte zwischen Kunden anfällig werden können. Diese Erkenntnisse haben uns dazu veranlasst, EE-miteinander verbundene Mittelwert zu entwickeln (EE-T-TRMean).
EE-T-TRMEAN: Eine Epsilon Grasping Aggregationsstrategie
EE-T-TRMEAN bauen auf dem klassischen Mittelwert auf, fügt jedoch eine Exploration vs. Exploitation, Epsilon Grasping-Schicht für die Kundenauswahl hinzu.
- Explorationsphase: Alle Kunden dürfen einen Beitrag leisten und eine normale mittlere Aggregationsrunde wird ausgeführt.
- Ausbeutungsphase: Die Kunden, die am wenigsten geschnitten wurden, werden in der Ausbeutungsphase über ein durchschnittliches Rating -System aufgenommen, das auf früheren Runden basiert, die daran teilgenommen haben.
- Der Schalter zwischen den beiden Phasen wird durch die Epsilon-Grasping-Richtlinie mit einem verfallenen Epsilon und einer Alpha-Rampe gesteuert.
Jeder Kunde verdient eine Punktzahl, die darauf basiert, ob seine Parameter in jeder Runde das Trimmen überleben. Im Laufe der Zeit wird der Algorithmus zunehmend die Kunden mit höchster Punktzahl bevorzugen, während sie gelegentlich andere untersuchen, um Verhaltensänderungen zu erkennen. Dieser adaptive Ansatz ermöglicht es EE-T-TRMean, die Widerstandsfähigkeit in Fällen zu erhöhen, in denen die Datenheterogenität und die böswillige Aktivität hoch sind.

In einem Label-Flipping-Szenario mit 20% böswilligen Kunden und verspäteten gutartigen Tischern auf nicht-iid, teilweise unausgeglichenen Daten, EE-T-TRMEAN (Abb. 3) Wechselte zwischen Explorations- und Nutzungsphasen, die allen Kunden zulassen und dann selektiv die niedrigen Bewertungen blockieren. Während es aufgrund der Datenheterogenität (immer noch viel besser als die bekannten Strategien) gelegentlich einen gutartigen Kunden ausschloss, identifizierte und minimierte es die Beiträge böswilliger Kunden während des Trainings erfolgreich. Diese einfache, aber leistungsstarke Änderung verbessert die Beiträge des Kunden. Die Literatur berichtet, dass die Genauigkeit des Modells, solange die Mehrheit der Kunden ehrlich ist, zuverlässig ist.