
Stellen Sie sich vor, Sie haben einen Röntgenbericht und möchten wissen, welche Verletzungen Sie haben. Eine Möglichkeit besteht darin, dass Sie einen Arzt aufsuchen können, was Sie im Idealfall tun sollten. Wenn dies jedoch aus irgendeinem Grund nicht möglich ist, können Sie Multimodal Giant Language Fashions (MLLMs) verwenden, die Ihren Röntgenscan verarbeiten und Ihnen genau sagen, welche Verletzungen Sie haben zu den Scans.
Einfach ausgedrückt sind MLLMs nichts anderes als eine Verschmelzung mehrerer Modelle wie Textual content, Bild, Sprache, Movies usw., die nicht nur in der Lage sind, eine normale Textabfrage zu verarbeiten, sondern auch Fragen in verschiedenen Formen wie Bildern und Ton.
In diesem Artikel erklären wir Ihnen, was MLLMs sind, wie sie funktionieren und welche MMLMs Sie am besten verwenden können.
Was sind multimodale LLMs?
Im Gegensatz zu herkömmlichen LLMs, die nur mit einem Datentyp arbeiten können – hauptsächlich Textual content oder Bild – können diese multimodalen LLMs mit mehreren Datenformen arbeiten, ähnlich wie Menschen Bilder, Sprache und Textual content gleichzeitig verarbeiten können.
Im Kern nimmt die multimodale KI verschiedene Formen von Daten auf, etwa Textual content, Bilder, Audio, Video und sogar Sensordaten, um ein umfassenderes und differenzierteres Verständnis und eine umfassendere Interaktion zu ermöglichen. Stellen Sie sich ein KI-System vor, das ein Bild nicht nur betrachtet, sondern es auch beschreiben, den Kontext verstehen, Fragen dazu beantworten und sogar verwandte Inhalte basierend auf mehreren Eingabetypen generieren kann.
Nehmen wir nun das gleiche Beispiel eines Röntgenberichts mit dem Kontext, wie ein multimodales LLM den Kontext verstehen wird. Hier ist eine einfache Animation, die erklärt, wie das Bild zunächst über den Bildencoder verarbeitet wird, um das Bild in Vektoren umzuwandeln, und wie es später LLM verwendet, das anhand medizinischer Daten trainiert wird, um die Anfrage zu beantworten.
Quelle: Google multimodale medizinische KI
Wie funktionieren multimodale LLMs?
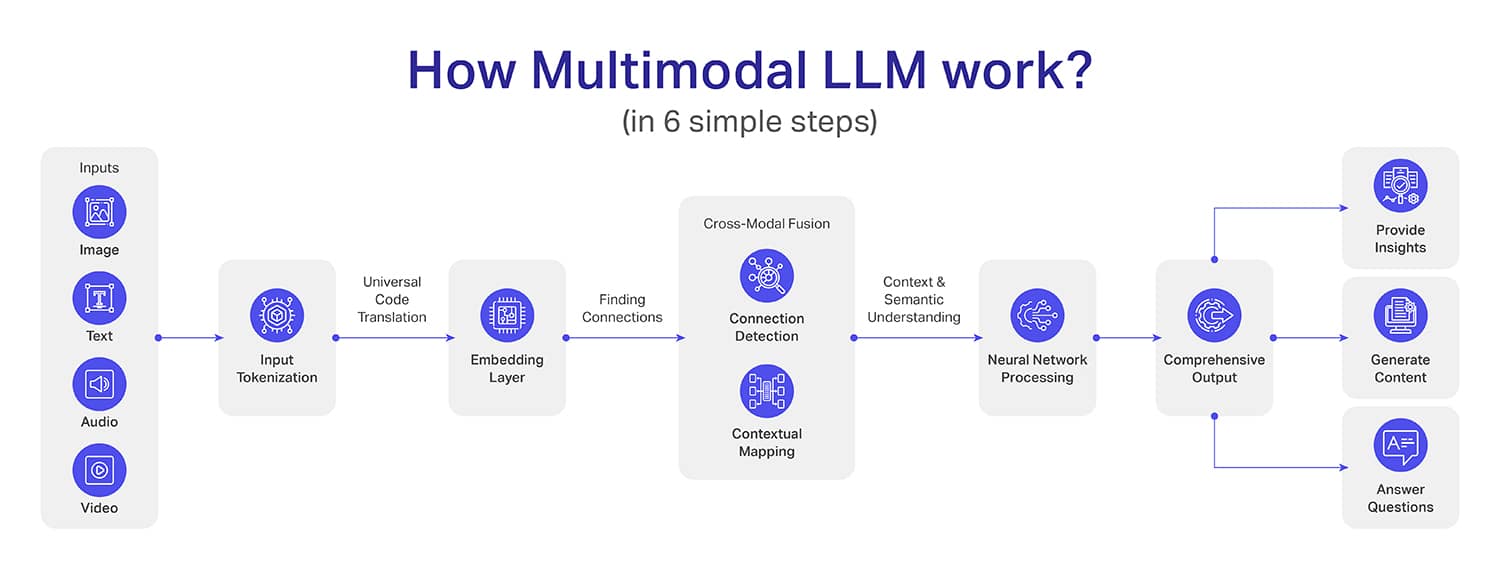
Obwohl das Innenleben multimodaler LLMs recht komplex ist (mehr als LLMs), haben wir versucht, es in sechs einfache Schritte zu unterteilen:
Schritt 1: Eingabesammlung – Dies ist der erste Schritt, bei dem die Daten erfasst und der ersten Verarbeitung unterzogen werden. Beispielsweise werden Bilder typischerweise mithilfe von CNN-Architekturen (Convolutional Neural Community) in Pixel umgewandelt.
Texteingaben werden mithilfe von Algorithmen wie BytePair Encoding (BPE) oder SentencePiece in Token umgewandelt. Andererseits werden Audiosignale in Spektrogramme oder Mel-Frequency-Cepstral-Koeffizienten (MFCCs) umgewandelt. Videodaten werden jedoch in sequentieller Kind in jedes Einzelbild zerlegt.
Schritt 2: Tokenisierung – Die Idee hinter der Tokenisierung besteht darin, die Daten in eine Standardform umzuwandeln, damit die Maschine den Kontext verstehen kann. Um beispielsweise Texte in Token umzuwandeln, kommt Pure Language Processing (NLP) zum Einsatz.
Für die Bild-Tokenisierung verwendet das System vorab trainierte Faltungs-Neuronale Netze wie ResNet- oder Imaginative and prescient Transformer (ViT)-Architekturen. Die Audiosignale werden mithilfe von Signalverarbeitungstechniken in Token umgewandelt, sodass Audiowellenformen in kompakte und aussagekräftige Ausdrücke umgewandelt werden können.
Schritt 3: Ebene einbetten – In diesem Schritt werden die Token (die wir im vorherigen Schritt erreicht haben) in dichte Vektoren umgewandelt, sodass diese Vektoren den Kontext der Daten erfassen können. Hierbei ist zu beachten, dass jede Modalität ihre eigenen Vektoren entwickelt, die mit anderen kreuzkompatibel sind.
Schritt 4: Cross-modale Fusion – Bisher konnten Modelle die Daten bis auf die Ebene des einzelnen Modells verstehen, aber ab dem 4. Schritt ändert sich das. Bei der modalübergreifenden Fusion lernt das System, Punkte zwischen mehreren Modalitäten für tiefere Kontextbeziehungen zu verbinden.
Ein gutes Beispiel, bei dem das Bild eines Strandes, eine Textdarstellung eines Urlaubs am Strand und Audioclips von Wellen, Wind und einer fröhlichen Menschenmenge interagieren. Auf diese Weise versteht das multimodale LLM nicht nur die Eingaben, sondern fügt alles zu einem einzigen Erlebnis zusammen.
Schritt 5: Verarbeitung neuronaler Netzwerke – Die Verarbeitung neuronaler Netzwerke ist der Schritt, in dem die aus der modalübergreifenden Fusion (vorheriger Schritt) gesammelten Informationen in aussagekräftige Erkenntnisse umgewandelt werden. Jetzt wird das Modell Deep Studying nutzen, um die komplexen Verbindungen zu analysieren, die während der modalübergreifenden Fusion gefunden wurden.
Stellen Sie sich einen Fall vor, in dem Sie Röntgenberichte, Patientennotizen und Symptombeschreibungen kombinieren. Durch die Verarbeitung neuronaler Netzwerke werden nicht nur Fakten aufgelistet, sondern ein ganzheitliches Verständnis geschaffen, das potenzielle Gesundheitsrisiken erkennen und mögliche Diagnosen vorschlagen kann.
Schritt 6 – Ausgabegenerierung – Dies ist der letzte Schritt, in dem das MLLM eine präzise Ausgabe für Sie erstellt. Im Gegensatz zu herkömmlichen Modellen, die oft kontextbegrenzt sind, wird die Ausgabe von MLLM eine Tiefe und ein kontextbezogenes Verständnis aufweisen.
Außerdem kann die Ausgabe mehr als ein Format haben, z. B. die Erstellung eines Datensatzes, die Erstellung einer visuellen Darstellung eines Szenarios oder sogar eine Audio- oder Videoausgabe eines bestimmten Ereignisses.
Was sind die Anwendungen multimodaler großer Sprachmodelle?
Auch wenn der Begriff „MLLM“ erst seit Kurzem in Gebrauch ist, gibt es Hunderte von Anwendungen, bei denen dank MLLMs bemerkenswerte Verbesserungen im Vergleich zu herkömmlichen Methoden zu verzeichnen sind. Hier sind einige wichtige Anwendungen von MLLM: