
LAPPEN ist eine hochentwickelte KI-Technik, die die Leistung von verbessert LLMs durch den Abruf relevanter Dokumente oder Informationen aus externen Quellen während der Texterstellung; Im Gegensatz zu herkömmlichen LLMs, die ausschließlich auf internen Trainingsdaten basieren, nutzt RAG Echtzeitinformationen, um genauere und kontextbezogenere Antworten zu liefern. Während Naive RAG bei einfachen Abfragen sehr intestine funktioniert, hat es bei komplexen Fragen, die eine mehrstufige Argumentation oder iterative Verfeinerung erfordern, Probleme.
Lernziele
- Verstehen Sie die Hauptunterschiede zwischen Agentic RAG und Naive RAG.
- Erkennen Sie die Einschränkungen von Naive RAG bei der Bearbeitung komplexer Abfragen.
- Entdecken Sie verschiedene Anwendungsfälle, in denen Agentic RAG sich bei mehrstufigen Argumentationsaufgaben auszeichnet.
- Erfahren Sie, wie Sie Agentic RAG in Python mithilfe von CrewAI für den intelligenten Datenabruf und die Datenzusammenfassung implementieren.
- Entdecken Sie, wie Agentic RAG die Fähigkeiten von Naive RAG durch das Hinzufügen von Entscheidungsagenten stärkt.
Dieser Artikel wurde im Rahmen der veröffentlicht Knowledge Science-Blogathon.
Agentisches RAG stärkt die Fähigkeiten von Naive RAG
Agentic RAG ist ein neuartiger Hybridansatz, der die Stärken von vereint Retrieval-Augmented Era und KI-Agenten. Dieses Framework verbessert die Generierung und Entscheidungsfindung durch die Integration dynamischer Abrufsysteme (RAG) mit autonomen Agenten. In Agentic RAG sind Retriever und Generator kombiniert und arbeiten in einem Multi-Agenten-Framework, in dem Agenten bestimmte Informationen anfordern und Entscheidungen auf der Grundlage der abgerufenen Daten treffen können.
Agentisches RAG gegen naives RAG
- Während sich Naive RAG ausschließlich auf die Verbesserung der Generierung durch Informationsabruf konzentriert, fügt Agentic RAG eine Ebene der Entscheidungsfindung durch autonome Agenten hinzu.
- In Naive RAG ist der Retriever passiv und ruft Daten nur auf Anfrage ab. Im Gegensatz dazu setzt Agentic RAG Agenten ein, die aktiv entscheiden, wann, wie und was abgerufen werden soll.
Der Prime-Okay-Abruf in Naive RAG kann in den folgenden Szenarien fehlschlagen:
- Zusammenfassungsfragen: „Geben Sie mir eine Zusammenfassung dieses Dokuments.“
- Vergleichsfragen: „Vergleichen Sie die Geschäftsstrategie von PepsiCo und Coca Cola für das letzte Quartal 2023“
- Mehrteilige komplexe Abfragen: „Erzählen Sie mir von den wichtigsten Argumenten zur Einzelhandelsinflation, die im Mint-Artikel vorgestellt werden, und erzählen Sie mir von den wichtigsten Argumenten zur Einzelhandelsinflation im Artikel der Financial Instances.“ Erstellen Sie eine Vergleichstabelle auf Grundlage der gesammelten Argumente und generieren Sie dann auf Grundlage dieser Fakten die wichtigsten Schlussfolgerungen.“

Anwendungsfälle von Agentic RAG
Durch die Integration von KI-Agenten in RAG könnte agentisches RAG in mehreren intelligenten, mehrstufigen Argumentationssystemen genutzt werden. Einige wichtige Anwendungsfälle könnten die folgenden sein:
- Rechtsrecherche: Vergleich von Rechtsdokumenten und Generierung wichtiger Klauseln für eine schnelle Entscheidungsfindung.
- Marktanalyse: Wettbewerbsanalyse von Prime-Marken in einem Produktsegment.
- Medizinische Diagnose: Vergleich von Patientendaten und neuesten Forschungsstudien zur Erstellung einer möglichen Diagnose.
- Finanzanalyse: Verarbeitung verschiedener Finanzberichte und Generierung von Schlüsselpunkten für bessere Investitionseinblicke.
- Einhaltung: Sicherstellung der Einhaltung gesetzlicher Vorschriften durch den Vergleich von Richtlinien mit Gesetzen.
Erstellen von Agentic RAG mit Python und CrewAI
Betrachten Sie einen Datensatz, der aus verschiedenen technischen Produkten und den für diese Produkte aufgeworfenen Kundenproblemen besteht, wie in der Abbildung unten dargestellt. Sie können den Datensatz herunterladen unter Hier.
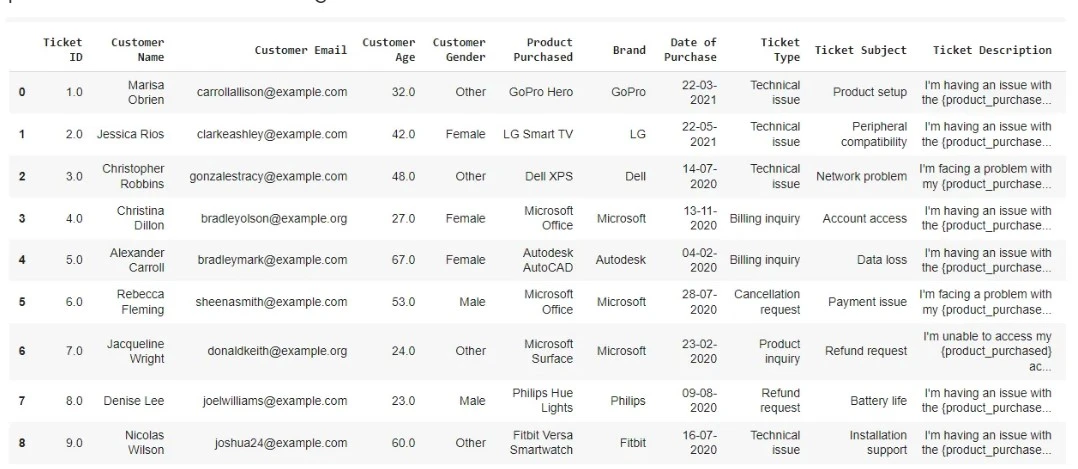
Wir können ein Agenten-RAG-System entwickeln, um die häufigsten Kundenbeschwerden für jede der Marken wie GoPro, Microsoft usw. über alle ihre Produkte hinweg zusammenzufassen. Wir werden in den folgenden Schritten sehen, wie wir dies erreichen können.
Schritt 1: Installieren Sie die erforderlichen Python-Bibliotheken
Bevor Sie mit Agentic RAG beginnen, ist es wichtig, die erforderlichen Python-Bibliotheken, einschließlich CrewAI und LlamaIndex, zu installieren, um den Datenabruf und agentenbasierte Aufgaben zu unterstützen.
!pip set up llama-index-core
!pip set up llama-index-readers-file
!pip set up llama-index-embeddings-openai
!pip set up llama-index-llms-llama-api
!pip set up 'crewai(instruments)'Schritt 2: Importieren Sie die erforderlichen Python-Bibliotheken
Dieser Schritt umfasst den Import wesentlicher Bibliotheken, um die Agenten und Instruments für die Implementierung von Agentic RAG einzurichten und so eine effiziente Datenverarbeitung und -abfrage zu ermöglichen.
import os
from crewai import Agent, Process, Crew, Course of
from crewai_tools import LlamaIndexTool
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.llms.openai import OpenAISchritt 3: Lesen Sie die entsprechende CSV-Datei mit den Kundenproblemdaten
Jetzt laden wir den Datensatz mit Kundenproblemen, um ihn für die Analyse zugänglich zu machen und die Grundlage für den Abruf und die Zusammenfassung zu bilden.
reader = SimpleDirectoryReader(input_files=("CustomerSuppTicket_small.csv"))
docs = reader.load_data()Schritt 4: Definieren Sie den Open AI API-Schlüssel
In diesem Schritt wird der OpenAI-API-Schlüssel eingerichtet, der für den Zugriff auf die Sprachmodelle von OpenAI zur Bearbeitung von Datenabfragen erforderlich ist.
from google.colab import userdata
openai_api_key = ''
os.environ('OPENAI_API_KEY')=openai_api_keySchritt 5: LLM-Initialisierung
Initialisieren Sie die Großes Sprachmodell (LLM), das die vom Agentic RAG-System abgerufenen Abfrageergebnisse verarbeitet und so die Zusammenfassung und Erkenntnisse verbessert.
llm = OpenAI(mannequin="gpt-4o")Schritt 6: Erstellen eines Vector Retailer-Index und einer Abfrage-Engine
Dazu gehört die Erstellung eines Vektorspeicherindex und einer Abfragemaschine, die den Datensatz auf der Grundlage von Ähnlichkeiten leicht durchsuchbar machen und verfeinerte Ergebnisse vom LLM liefern.
#creates a VectorStoreIndex from a listing of paperwork (docs)
index = VectorStoreIndex.from_documents(docs)
#The vector retailer is remodeled into a question engine.
#Setting similarity_top_k=5 limits the outcomes to the highest 5 paperwork which can be most much like the question,
#llm specifies that the LLM must be used to course of and refine the question outcomes
query_engine = index.as_query_engine(similarity_top_k=5, llm=llm)Schritt 7: Erstellen eines Instruments basierend auf der definierten Abfrage-Engine
Dabei wird LlamaIndexTool verwendet, um ein Device basierend auf der query_engine zu erstellen. Das Device trägt den Namen „Buyer Assist Question Device“ und wird als Möglichkeit zum Nachschlagen von Kundenticketdaten beschrieben.
query_tool = LlamaIndexTool.from_query_engine(
query_engine,
identify="Buyer Assist Question Device",
description="Use this instrument to lookup the shopper ticket information",
)Schritt 8: Definieren der Agenten
Agenten werden mit spezifischen Rollen und Zielen definiert, um Aufgaben wie Datenanalyse und Inhaltserstellung auszuführen, die darauf abzielen, Erkenntnisse aus Kundendaten zu gewinnen.
researcher = Agent(
position="Buyer Ticket Analyst",
objective="Uncover insights about buyer points traits",
backstory="""You're employed at a Product Firm.
Your objective is to know buyer points patterns for every of the manufacturers - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone'.""",
verbose=True,
allow_delegation=False,
instruments=(query_tool),
)
author = Agent(
position="Product Content material Specialist",
objective="""Craft compelling content material on buyer points traits for every of the manufacturers - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone'.""",
backstory="""You're a famend Content material Specialist, recognized on your insightful and interesting articles.
You remodel advanced gross sales information into compelling narratives.""",
verbose=True,
allow_delegation=False,
)Die Rolle des „Researcher“-Agenten ist ein Analyst, der Kundensupportdaten überprüft und interpretiert. Das Ziel dieses Agenten besteht darin, „Erkenntnisse über Tendencies bei Kundenproblemen zu gewinnen“. Die Hintergrundgeschichte liefert dem Agenten einen Hintergrund oder Kontext zu seinem Zweck. Hier übernimmt er die Rolle eines Assist-Analysten bei einem Produktunternehmen mit der Aufgabe, Kundenprobleme für verschiedene Marken (z. B. GoPro, LG, Dell usw.) zu verstehen. Dieser Hintergrund hilft dem Agenten, sich bei der Suche nach Tendencies auf jede Marke individuell zu konzentrieren. Dem Agenten wird das Device „query_tool“ zur Verfügung gestellt. Das bedeutet, dass der Analysis-Agent dieses Device verwenden kann, um relevante Kundensupportdaten abzurufen, die er dann entsprechend seinem Ziel und seiner Hintergrundgeschichte analysieren kann.
Die Rolle des „Autor“-Agenten ist die eines Inhaltserstellers, der sich auf die Bereitstellung von Produkteinblicken konzentriert. Das Ziel dieses Agenten besteht darin, „überzeugende Inhalte“ zu Tendencies bei Kundenthemen für eine Liste von Marken zu erstellen. Dieses Ziel führt den Agenten dazu, gezielt nach Erkenntnissen zu suchen, die sich für gute narrative oder analytische Inhalte eignen. Die Hintergrundgeschichte gibt dem Agenten zusätzlichen Kontext und stellt ihn als hochqualifizierten Content material-Ersteller dar, der in der Lage ist, Daten in ansprechende Artikel umzuwandeln.
Schritt 9: Erstellen der Aufgaben für die definierten Agenten
Den Agenten werden Aufgaben auf der Grundlage ihrer Rollen zugewiesen, wobei spezifische Verantwortlichkeiten wie die Datenanalyse und die Erstellung von Berichten zu Kundenproblemen dargelegt werden.
task1 = Process(
description="""Analyze the highest buyer points points for every of the manufacturers - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone'.""",
expected_output="Detailed Buyer Points mentioning NAME of Model report with traits and insights",
agent=researcher,
)
task2 = Process(
description="""Utilizing the insights offered, develop a fascinating weblog
submit that highlights the top-customer points for every of the manufacturers - 'GoPro' 'LG' 'Dell' 'Microsoft' 'Autodesk' 'Philips' 'Fitbit' 'Dyson'
'Nintendo' 'Nest' 'Sony' 'Xbox' 'Canon' 'HP' 'Amazon' 'Lenovo' 'Adobe'
'Google' 'PlayStation' 'Samsung' 'iPhone' and their ache factors.
Your submit must be informative but accessible, catering to an informal viewers.Guarantee thet the submit has NAME of the BRAND e.g. GoPro, FitBit and so forth.
Make it sound cool, keep away from advanced phrases.""",
expected_output="Full weblog submit in Bullet Factors of buyer points. Guarantee thet the Weblog has NAME of the BRAND e.g. GoPro, FitBit and so forth.",
agent=author,
)Schritt 10: Instanziieren der Crew mit einem sequentiellen Prozess
Es wird ein Workforce aus Agenten und Aufgaben gebildet. Dieser Schritt leitet den Prozess ein, bei dem Agenten gemeinsam Datenerkenntnisse abrufen, analysieren und präsentieren.
crew = Crew(
brokers=(researcher,author),
duties=(task1,task2),
verbose=True, # You possibly can set it to 1 or 2 to totally different logging ranges
)
consequence = crew.kickoff()Dieser Code erstellt eine Crew-Instanz, bei der es sich um eine Gruppe von Agenten handelt, denen bestimmte Aufgaben zugewiesen sind, und initiiert dann die Arbeit der Crew mit der Methode kickoff().
Agenten: Dieser Parameter weist der Crew eine Liste von Agenten zu. Hier haben wir zwei Agenten: einen Forscher und einen Autor. Jeder Agent hat eine bestimmte Rolle: Der Rechercheur konzentriert sich auf die Analyse der Kundenprobleme für jede Marke, während sich der Autor auf die Zusammenfassung dieser Probleme konzentriert.
Aufgaben: Dieser Parameter stellt eine Liste von Aufgaben bereit, die die Crew erledigen soll.
Ausgabe

Wie aus der obigen Ausgabe hervorgeht, wurde mithilfe des Agentic RAG-Methods eine prägnante Zusammenfassung in Stichpunkten aller Kundenprobleme verschiedener Marken wie LG, Dell, Fitbit usw. erstellt. Diese prägnante und genaue Zusammenfassung der Kundenprobleme über die verschiedenen Marken hinweg ist nur durch den Einsatz der Agenten möglich.
Abschluss
Agentic RAG ist ein großer Fortschritt in der Retrieval-Augmented Era. Es verbindet die Abrufleistung von RAG mit der Entscheidungsfähigkeit autonomer Agenten. Dieses Hybridmodell geht über Naive RAG hinaus und befasst sich mit komplexen Fragen und vergleichenden Analysen. Branchenübergreifend liefert es aufschlussreichere und genauere Antworten. Mit Python und CrewAI können Entwickler jetzt Agentic RAG-Systeme für intelligentere, datengesteuerte Entscheidungen erstellen.
Wichtige Erkenntnisse
- Agentic RAG integriert autonome Agenten und fügt so eine Ebene dynamischer Entscheidungsfindung hinzu, die über den einfachen Abruf hinausgeht.
- Agentic RAG nutzt Agenten, um komplexe Abfragen zu bearbeiten, einschließlich Zusammenfassung, Vergleich und mehrteiliger Argumentation. Diese Funktion behebt Einschränkungen, bei denen Naive RAG normalerweise nicht ausreicht.
- Agentic RAG ist in Bereichen wie Rechtsrecherche, medizinische Diagnose, Finanzanalyse und Compliance-Überwachung wertvoll. Es bietet differenzierte Einblicke und eine verbesserte Entscheidungsunterstützung.
- Mit CrewAI kann Agentic RAG effektiv in Python implementiert werden und demonstriert einen strukturierten Ansatz für die Zusammenarbeit mehrerer Agenten zur Bewältigung komplexer Kundensupport-Analyseaufgaben.
- Aufgrund der flexiblen agentenbasierten Architektur von Agentic RAG eignet es sich intestine für den komplexen Datenabruf und die Analyse in verschiedenen Anwendungsfällen, vom Kundenservice bis hin zu erweiterten Analysen.
Häufig gestellte Fragen
A. Agentic RAG umfasst autonome Agenten, die den Datenabruf und die Entscheidungsfindung aktiv verwalten, während Naive RAG Informationen einfach auf Anfrage ohne zusätzliche Argumentationsfähigkeiten abruft.
A. Der passive Abrufansatz von Naive RAG ist auf direkte Antworten beschränkt, was ihn für Zusammenfassungen, Vergleiche oder mehrteilige Abfragen, die iteratives Denken oder mehrschichtigen Informationsabruf erfordern, unwirksam macht.
A. Agentic RAG ist wertvoll für Aufgaben, die eine mehrstufige Argumentation erfordern, wie z. B. Rechtsrecherchen, Marktanalysen, medizinische Diagnosen, finanzielle Erkenntnisse und die Sicherstellung der Compliance durch Richtlinienvergleich.
A. Ja, Sie können Agentic RAG in Python implementieren, insbesondere mithilfe von Bibliotheken wie CrewAI. Dies hilft beim Einrichten und Verwalten von Agenten, die zusammenarbeiten, um Daten abzurufen, zu analysieren und zusammenzufassen.
A. Branchen mit komplexen Datenverarbeitungsanforderungen, wie Recht, Gesundheitswesen, Finanzen und Kundensupport, werden am meisten von den intelligenten Datenabruf- und Entscheidungsfunktionen von Agentic RAG profitieren.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.