
Einführung
Obwohl sich FastAPI intestine für die Implementierung von RESTful-APIs eignet, wurde es nicht speziell für die Bewältigung der komplexen Anforderungen bei der Bereitstellung von Modellen für maschinelles Lernen entwickelt. Die Unterstützung von FastAPI für asynchrone Aufrufe erfolgt hauptsächlich auf Webebene und reicht nicht tief in die Modellvorhersageebene hinein. Diese Einschränkung stellt eine Herausforderung dar, da KI-Modellvorhersagen ressourcenintensive Vorgänge sind, die zur Optimierung der Leistung konfiguriert werden müssen, insbesondere im Umgang mit modernen große Sprachmodelle (LLMs).
Die Bereitstellung und Bereitstellung von Modellen für maschinelles Lernen in großem Maßstab kann ebenso herausfordernd sein wie die Erstellung der Modelle selbst. Hier kommt LitServe ins Spiel, eine versatile Open-Supply-Serving-Engine, die auf FastAPI aufbaut. LitServe vereinfacht den Prozess der Bereitstellung von KI-Modellen durch die Bereitstellung leistungsstarker Funktionen wie Batching, Streaming, GPU-Beschleunigung und automatische Skalierung. In diesem Artikel stellen wir LitServe vor, befassen uns mit seinen Funktionen und wie es zum Aufbau skalierbarer, leistungsstarker KI-Server verwendet werden kann.
Lernziele
- Erfahren Sie, wie Sie mit LitServe ganz einfach KI-Modelle einrichten und bereitstellen.
- Erfahren Sie, wie Sie Batch-, Streaming- und GPU-Beschleunigung nutzen, um die Leistung von KI-Modellen zu verbessern.
- Sammeln Sie praktische Erfahrungen anhand eines Spielzeugbeispiels und bauen Sie einen einfachen Server für die Bereitstellung von KI-Modellen.
- Entdecken Sie Funktionen zur Optimierung der Modellbereitstellung für hohen Durchsatz und Skalierbarkeit.

Dieser Artikel wurde im Rahmen der veröffentlicht Information Science-Blogathon.
Was ist Mannequin Serving?
In maschinelles LernenDurch die effektive Bereitstellung und Bereitstellung von Modellen können Vorhersagen in Echtzeitanwendungen getroffen werden, wenn sie in der Produktion bereitgestellt werden. Unter Modellbereitstellung versteht man den Prozess, bei dem ein trainiertes maschinelles Lernmodell für den Einsatz in Produktionsumgebungen verfügbar gemacht wird. Dies kann die Offenlegung des Modells über APIs beinhalten, damit Benutzer oder Anwendungen Rückschlüsse ziehen und Vorhersagen erhalten können.
Die Bedeutung der Modellbereitstellung beeinflusst die Reaktionsfähigkeit und Skalierbarkeit von Anwendungen für maschinelles Lernen. Bei der Bereitstellung treten mehrere Herausforderungen auf, beispielsweise bei großen Sprachmodellen (LLMs), die hohe Rechenressourcen erfordern. Zu diesen Herausforderungen gehören Latenzzeiten bei den Antwortzeiten, die Notwendigkeit einer effizienten Ressourcenverwaltung und die Sicherstellung, dass Modelle unterschiedliche Lasten ohne Leistungseinbußen bewältigen können. Entwickler benötigen robuste Lösungen, die den Bereitstellungsprozess vereinfachen und gleichzeitig die Effizienz maximieren. Hier kommen spezielle Instruments wie LitServe ins Spiel, die Funktionen zur Optimierung der Modellbereitstellung und -leistung bieten.
Was ist LitServe?
LitServe ist ein Open-Supply-Modellserver, der eine schnelle, versatile und skalierbare Bereitstellung von KI-Modellen ermöglicht. Durch die Abwicklung komplexer technischer Aufgaben wie Skalierung, Stapelverarbeitung und Streaming entfällt die Notwendigkeit, FastAPI-Server für jedes Modell neu zu erstellen. Sie können LitServe verwenden, um Modelle auf lokalen Maschinen, Cloud-Umgebungen oder Hochleistungsrechnen mit mehreren GPUs bereitzustellen.
Hauptmerkmale von LitServe
Lassen Sie uns die wichtigsten Funktionen von LitServe erkunden:
Schnellere Modellbereitstellung: LitServe ist auf Leistung optimiert und stellt sicher, dass Modelle besser und sogar besser funktionieren als herkömmliche Methoden.
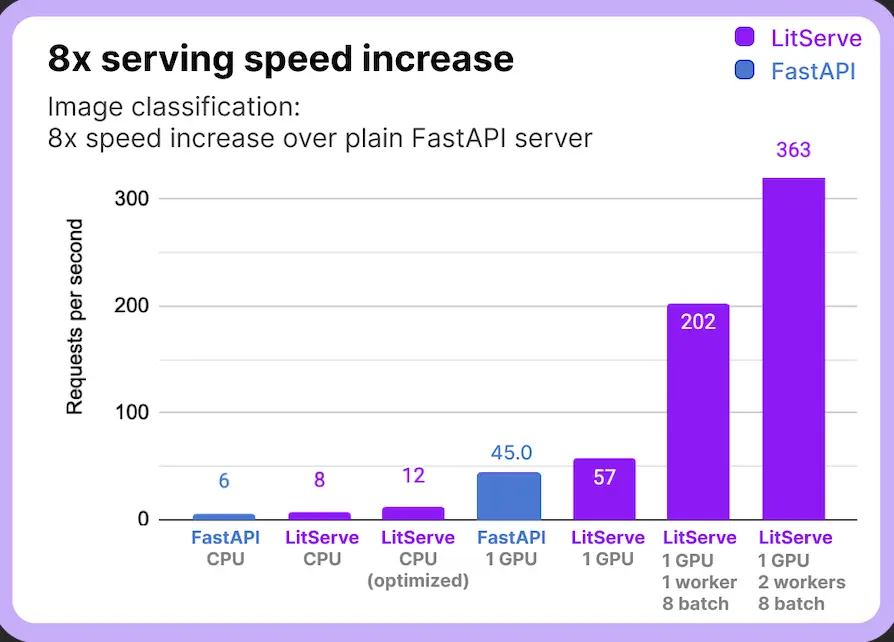
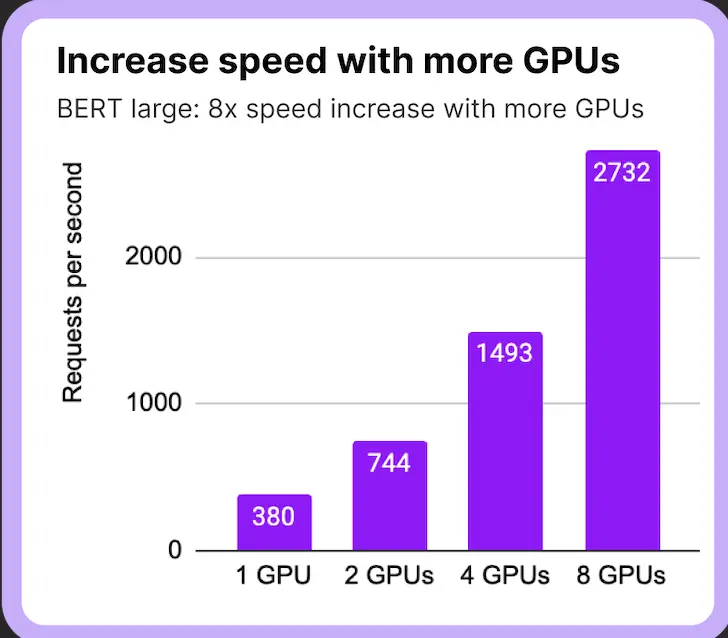
Multi-GPU-Unterstützung: In Fällen, in denen der Server über mehrere GPUs verfügt, nutzt er die Leistung mehrerer GPUs, um die Modellbereitstellung zu parallelisieren und so die Latenz zu reduzieren.
Batchverarbeitung und Streaming: LitServe kann mithilfe von Batch-Techniken oder Streaming der Antwort mehrere Anrufe gleichzeitig bedienen, ohne den Server zu überlasten.
LitServe prahlt mit zahlreichen Funktionen von der Authentifizierung bis hin zu OpenAI-Spezifikationen mit Funktionen zur Bewältigung komplexer KI-Workloads.
Erste Schritte mit LitServe
Um die Funktionsweise von LitServe zu veranschaulichen, beginnen wir mit einem einfachen Beispiel und fahren dann mit der Bereitstellung eines realistischeren KI-Servers für die Bildunterschrift unter Verwendung von Modellen von Hugging Face fort. Der erste Schritt besteht darin, LitServe zu installieren:
pip set up litserveDefinieren einer einfachen API mit LitServe
LitServe vereinfacht den Prozess der Definition, wie Ihr Modell mit externen Aufrufen interagiert. Die LitAPI-Klasse verarbeitet eingehende Aufrufe und gibt Modellvorhersagen zurück. So können Sie eine einfache API einrichten:
import litserve as ls
class SimpleLitAPI(ls.LitAPI):
def setup(self, machine):
self.model1 = lambda x: x**2
self.model2 = lambda x: x**3
def decode_request(self, request):
return request("enter")
def predict(self, x):
squared = self.model1(x)
cubed = self.model2(x)
output = squared + cubed
return {"output": output}
def encode_response(self, output):
return {"output": output}Lassen Sie uns die Klasse aufschlüsseln:
- aufstellen: Initialisiert die Modelle oder Ressourcen, die Ihr Server benötigt. In diesem Beispiel definieren wir zwei einfache Funktionen, die Modelle simulieren.
- decode_request: Konvertiert eingehende Anrufe in ein Format, das das Modell verarbeiten kann. Es extrahiert die Eingabe aus der Anforderungsnutzlast.
- vorhersagen: Führt die Modelle aus, um Vorhersagen zu treffen. Hier werden Quadrat und Potenz der Eingabe berechnet und summiert.
- encode_response: Konvertiert die Ausgabe des Modells in ein Antwortformat, das an den Consumer zurückgesendet werden kann.
Nachdem Sie Ihre API definiert haben, können Sie den Server ausführen, indem Sie Ihre API-Klasse instanziieren und an LitServer übergeben:
if __name__ == "__main__":
api = SimpleLitAPI()
server = ls.LitServer(api, accelerator="gpu") # accelerator will also be 'auto'
server.run(port=8000)Dieser Befehl startet den Server, um Rückschlüsse mit GPU-Beschleunigung zu verarbeiten.
Bereitstellung eines Visionsmodells mit LitServe
Um das volle Potenzial von LitServe zu demonstrieren, stellen wir einen realistischen KI-Server bereit, der Bildunterschriften anhand eines Modells von Hugging Face durchführt. Dieses Beispiel zeigt, wie LitServe komplexere Aufgaben und Funktionen wie GPU-Beschleunigung bewältigt.
Implementierung des Picture Captioning Servers
Importieren Sie zunächst die erforderlichen Bibliotheken und definieren Sie Hilfsfunktionen:
import requests
import torch
from PIL import Picture
from transformers import VisionEncoderDecoderModel, ViTImageProcessor, GPT2TokenizerFast
from tqdm import tqdm
import urllib.parse as parse
import os
# LitServe API Integration
import litserve as ls
# Confirm URL perform
def check_url(string):
attempt:
consequence = parse.urlparse(string)
return all((consequence.scheme, consequence.netloc, consequence.path))
besides:
return False
# Load a picture from a URL or native path
def load_image(image_path):
if check_url(image_path):
return Picture.open(requests.get(image_path, stream=True).uncooked)
elif os.path.exists(image_path):
return Picture.open(image_path)Als nächstes definieren Sie die LitAPI-Klasse für Bildunterschriften:
# HuggingFace API class for picture captioning
class ImageCaptioningLitAPI(ls.LitAPI):
def setup(self, machine):
# Assign out there GPU or CPU
self.machine = "cuda" if torch.cuda.is_available() else "cpu"
# Load the ViT Encoder-Decoder Mannequin
model_name = "nlpconnect/vit-gpt2-image-captioning"
self.mannequin = VisionEncoderDecoderModel.from_pretrained(model_name).to(self.machine)
self.tokenizer = GPT2TokenizerFast.from_pretrained(model_name)
self.image_processor = ViTImageProcessor.from_pretrained(model_name)
# Decode payload to extract picture URL or path
def decode_request(self, request):
return request("image_path")
# Generate picture caption
def predict(self, image_path):
picture = load_image(image_path)
# Preprocessing the Picture
img = self.image_processor(picture, return_tensors="pt").to(self.machine)
# Producing captions
output = self.mannequin.generate(**img)
# Decode the output to generate the caption
caption = self.tokenizer.batch_decode(output, skip_special_tokens=True)(0)
return caption
# Encode the response again to the consumer
def encode_response(self, output):
return {"caption": output}Für genau diesen Anwendungsfall:
- aufstellen: Lädt das vorab trainierte Bildunterschriftenmodell sowie den zugehörigen Tokenizer und Prozessor und verschiebt sie auf das Gerät (CPU oder GPU).
- decode_request: Extrahiert den Bildpfad aus dem eingehenden Anruf.
- vorhersagen: Verarbeitet das Bild, generiert anhand des Modells eine Beschriftung und dekodiert sie.
- encode_response: Formatiert die Beschriftung in eine JSON-Antwort.
# Operating the LitServer
if __name__ == "__main__":
api = ImageCaptioningLitAPI()
server = ls.LitServer(api, accelerator="auto", gadgets=1, workers_per_device=1)
server.run(port=8000)Dieser Befehl startet den Server, erkennt automatisch verfügbare Beschleuniger und konfiguriert Geräte. Finden Sie die Den gesamten Code finden Sie hier.
Testen des Servers
Wenn der Server läuft, können Sie ihn testen, indem Sie POST-Anfragen mit einem image_path (entweder einer URL oder einem lokalen Dateipfad) in der Nutzlast senden. Der Server gibt eine generierte Beschriftung für das Bild zurück.
Beispiel: 1
Bild:

Generierte Beschriftung: „Ein Blick von einem Boot auf einen Strand mit einem großen Gewässer“
Beispiel 2:
Bild:

Generierte Beschriftung: „Ein Mann in Anzug und Krawatte mit einer rot-weißen Flagge“
Sie können das auf GitHub bereitgestellte Colab-Pocket book verwenden, um den Server direkt zu testen. Sie können erkunden, denn die Möglichkeiten sind endlos.
Leistungssteigerung mit erweiterten Funktionen
Mit LitServe können Sie die Leistung Ihres Servers optimieren, indem Sie die erweiterten Funktionen nutzen:
- Dosierung: Fügen Sie max_batch_size=2 in LitServer ein, um mehrere Aufrufe gleichzeitig zu verarbeiten und so den Durchsatz zu verbessern.
- Streaming: Legen Sie „stream“ auf „True“ fest, um große Eingaben effizient zu verarbeiten, ohne den Server zu überlasten.
- Geräteverwaltung: Geben Sie GPU-IDs in Geräten an, um die {Hardware} zu steuern. Dies ist besonders nützlich bei Konfigurationen mit mehreren GPUs.
Eine detaillierte Liste der Funktionen und Konfigurationen finden Sie in der offiziellen Dokumentation: LitServe-Funktionen
Warum LitServe wählen?
LitServe bewältigt effektiv die einzigartigen Herausforderungen beim Einsatz großer Sprachmodelle. Im Gegensatz zu herkömmlichen Modellbereitstellungsmethoden ist es auf leistungsstarke Inferenz ausgelegt und ermöglicht es Entwicklern, Modelle mit minimaler Latenz und maximalem Durchsatz bereitzustellen. Aus diesen Gründen sollten Sie LitServe für Ihre Mannequin-Serving-Anforderungen in Betracht ziehen:
- Skalierbarkeit: LitServe ist so konzipiert, dass es nahtlos mit Ihrer Anwendung skaliert. Es kann mehrere Anrufe gleichzeitig verarbeiten und die Rechenressourcen je nach Bedarf effizient verteilen.
- Optimierte Leistung: Es bietet Funktionen wie Batching, die die gleichzeitige Bearbeitung von Anrufen ermöglichen und so die durchschnittliche Antwortzeit verkürzen. Dies ist von Vorteil, wenn große Sprachmodelle bedient werden, die Ressourcen benötigen.
- Benutzerfreundlichkeit: LitServe vereinfacht mit der Einrichtung die Bereitstellung von Modellen für maschinelles Lernen. Entwickler können mit schnelleren Iterationen und Bereitstellungen schnell vom Modelltraining zur Produktion übergehen.
- Unterstützung für erweiterte Funktionen: LitServe unterstützt GPU-Beschleunigung und -Streaming und ermöglicht so eine effiziente Verarbeitung von Echtzeitdaten und komplexen Modellarchitekturen. Dadurch wird sichergestellt, dass Ihre Anwendungen auch unter hoher Belastung eine hohe Leistung beibehalten.
Abschluss
LitServe bietet eine leistungsstarke, versatile und effiziente Möglichkeit zur Bereitstellung von KI-Modellen. Durch die Abstrahierung der Komplexität von Skalierung, Stapelverarbeitung und {Hardware} können sich Entwickler auf die Entwicklung hochwertiger KI-Lösungen konzentrieren, ohne sich um die Feinheiten der Bereitstellung kümmern zu müssen. Unabhängig davon, ob Sie einfache Modelle oder komplexe, multimodale KI-Systeme einsetzen, ist LitServe aufgrund seiner robusten Funktionen und Benutzerfreundlichkeit eine gute Wahl sowohl für Anfänger als auch für erfahrene Praktiker.
Wichtige Erkenntnisse
- LitServe optimiert den Prozess der Bereitstellung von KI-Modellen und macht den Neuaufbau von Servern für jedes Modell überflüssig.
- Funktionen wie Batching, Streaming und Multi-GPU-Unterstützung verbessern die Leistung der Modellbereitstellung.
- LitServe passt sich Umgebungen an, von lokalen Maschinen bis hin zu Multi-GPU-Servern, und ist somit für Projekte jeder Größe geeignet.
- LitServe bewältigt komplexe KI-Arbeitslasten, indem es Authentifizierung, Compliance-Requirements und mehr unterstützt.
Referenzen und Hyperlinks
Häufig gestellte Fragen
A: FastAPI eignet sich zwar hervorragend für REST-APIs, ist jedoch nicht speziell für die Bereitstellung ressourcenintensiver KI-Modelle optimiert. LitServe basiert auf FastAPI und verbessert die Modellbereitstellung durch das Hinzufügen von Funktionen wie Batching, Streaming, GPU-Beschleunigung und Autoskalierung, die für große KI-Modelle von entscheidender Bedeutung sind, insbesondere für die Verarbeitung von Echtzeitvorhersagen mit hohem Durchsatz.
A. Ja, LitServe unterstützt sowohl CPU- als auch GPU-Beschleunigung. Sie können es so konfigurieren, dass verfügbare GPUs automatisch erkannt und verwendet werden, oder angeben, welche GPUs verwendet werden sollen. Dadurch eignet es sich intestine für die {Hardware}-übergreifende Skalierung.
A. Durch die Stapelverarbeitung kann LitServe mehrere eingehende Anrufe gruppieren, sie auf einmal verarbeiten und die Ergebnisse zurücksenden. Dies reduziert den Overhead und erhöht die Effizienz der Modellinferenz, insbesondere für Workloads, die eine parallele Verarbeitung auf GPUs erfordern.
A. LitServe kann eine Vielzahl von Modellen bedienen, darunter Modelle für maschinelles Lernen, Deep-Studying-Modelle und Giant Language Fashions (LLMs). Es unterstützt die Integration mit PyTorch, TensorFlow und Hugging Face Transformers und eignet sich daher für die Bereitstellung von Imaginative and prescient-, Sprach- und multimodalen Modellen.
A. Ja, LitServe lässt sich leicht in bestehende Pipelines für maschinelles Lernen integrieren. Es verwendet eine vertraute API, die auf FastAPI basiert, und mit der anpassbaren LitAPI-Klasse können Sie Ihre Modellinferenzlogik schnell anpassen, sodass Modelle nahtlos bereitgestellt werden können, ohne dass Ihre Pipeline zu stark umgestaltet werden muss.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Ich bin ein KI-Ingenieur mit einer großen Leidenschaft für die Forschung und die Lösung komplexer Probleme. Ich biete KI-Lösungen an, die Giant Language Fashions (LLMs), GenAI, Transformer-Modelle und Secure Diffusion nutzen.