
Neuigkeiten auf einen Blick
- Meta kündigt Chameleon an, ein fortschrittliches multimodales Giant Language Mannequin (LLM).
- Chameleon verwendet eine auf Early-Fusion-Token basierende Blended-Modal-Architektur.
- Das Modell verarbeitet und generiert Textual content und Bilder innerhalb eines einheitlichen Token-Raums.
- Es übertrifft andere Modelle bei Aufgaben wie der Bildbeschriftung und der visuellen Beantwortung von Fragen (VQA).
- Meta zielt darauf ab, Chameleon weiter zu verbessern und zusätzliche Modalitäten zu erkunden.

Meta macht Fortschritte in künstliche Intelligenz (KI) mit einem neuen multimodalen LLM namens Chameleon. Dieses Modell, das auf einer Early-Fusion-Architektur basiert, verspricht, verschiedene Arten von Informationen besser zu integrieren als seine Vorgänger. Mit diesem Schritt positioniert sich Meta als starker Konkurrent in der KI-Welt.
Lesen Sie auch: Ray-Ban Meta Good Glasses erhalten ein multimodales KI-Improve
Die Architektur von Chameleon verstehen
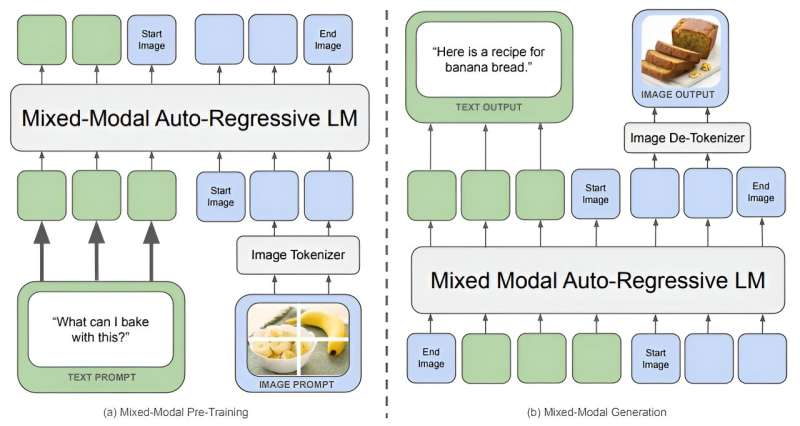
Chameleon verwendet eine Token-basierte Blended-Modal-Architektur der frühen Fusion und unterscheidet sich dadurch von herkömmlichen Modellen. Anders als beim Ansatz der späten Fusion, bei dem separate Modelle unterschiedliche Modalitäten verarbeiten, bevor sie diese kombinieren, integriert Chameleon von Anfang an Textual content, Bilder und andere Eingaben. Dieser einheitliche Token-Raum ermöglicht es Chameleon, nahtlos über verschachtelte Textual content- und Bildsequenzen nachzudenken und diese zu generieren.
Die Forscher von Meta heben die modern Architektur des Modells hervor. Durch die Kodierung von Bildern in diskrete Token, ähnlich wie Wörter in einem Sprachmodellerstellt Chameleon ein gemischtes Vokabular, das Textual content-, Code- und Bild-Token enthält. Dieses Design ermöglicht es dem Modell, die gleichen Transformator Architektur für Sequenzen, die sowohl Bild- als auch Texttoken enthalten. Es verbessert die Fähigkeit der Modelle, Aufgaben auszuführen, die ein gleichzeitiges Verständnis mehrerer Modalitäten erfordern.
Trainingsinnovationen und -techniken
Das Coaching eines Modells wie Chameleon bringt erhebliche Herausforderungen mit sich. Um diese zu bewältigen, führte Metas Staff mehrere architektonische Verbesserungen und Trainingstechniken ein. Sie entwickelten einen neuartigen Bild-Tokenizer und verwendeten Methoden wie QK-Norm, Dropout und Z-Loss-Regularisierung, um ein stabiles und effizientes Coaching zu gewährleisten. Die Forscher kuratierten außerdem einen hochwertigen Datensatz mit 4,4 Billionen Token, darunter Textual content, Bild-Textual content-Paare und verschachtelte Sequenzen.
Das Coaching von Chameleon erfolgte in zwei Phasen, wobei die Versionen des Modells 7 Milliarden und 34 Milliarden Parameter umfassten. Der Trainingsprozess dauerte über 5 Millionen Stunden auf Nvidia A100 80GB GPUs. Diese Bemühungen führten zu einem Modell, das verschiedene reine Textual content- und multimodale Aufgaben mit beeindruckender Effizienz und Genauigkeit ausführen kann.
Lesen Sie auch: Meta Llama 3: Neudefinition großer Sprachmodellstandards
Leistung über verschiedene Aufgaben hinweg
Die Leistung von Chameleon bei Imaginative and prescient-Language-Aufgaben ist bemerkenswert. Es übertrifft Modelle wie Flamingo-80B und IDEFICS-80B bei Bildunterschriften und VQA-Benchmarks. Darüber hinaus ist es bei reinen Textaufgaben konkurrenzfähig und erreicht Leistungsniveaus, die mit modernsten Sprachmodellen vergleichbar sind. Die Fähigkeit des Modells, gemischt-modale Antworten mit verschachteltem Textual content und Bildern zu generieren, hebt es von seinen Konkurrenten ab.
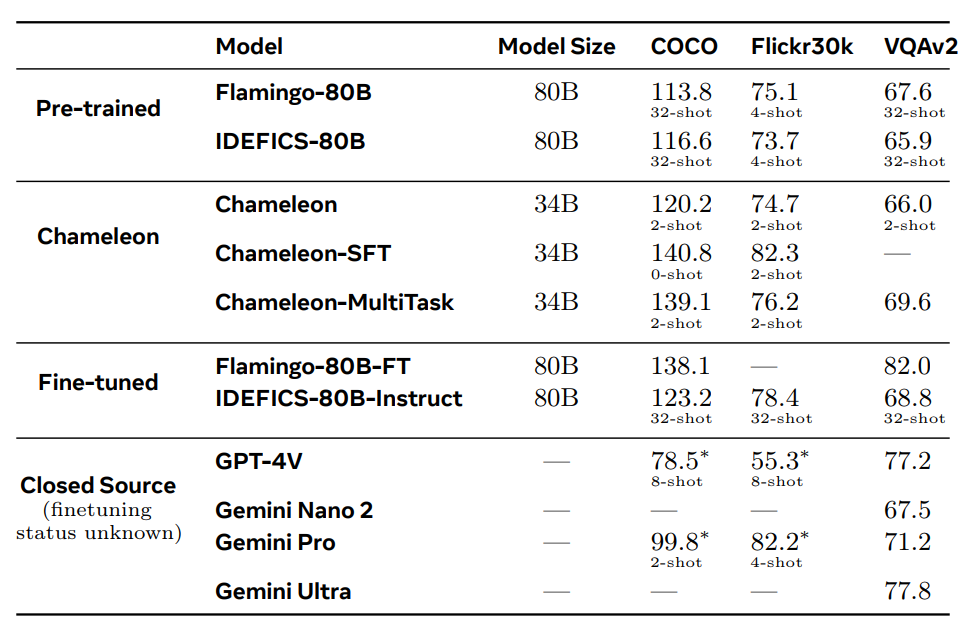
Die Forscher von Meta berichten, dass Chameleon diese Ergebnisse mit weniger kontextbezogenen Trainingsbeispielen und kleineren Modellgrößen erreicht, was seine Effizienz unterstreicht. Die Vielseitigkeit des Modells und seine Fähigkeit, mit gemischt-modalem Denken umzugehen, machen es zu einem wertvollen Werkzeug für verschiedene KI-Anwendungen, von erweiterten virtuellen Assistenten bis hin zu anspruchsvollen Instruments zur Inhaltsgenerierung.
Zukünftige Aussichten und Implikationen
Meta sieht Chameleon als wichtigen Schritt hin zu einer einheitlichen multimodale KI. Zukünftig plant das Unternehmen, die Integration zusätzlicher Modalitäten, wie etwa Audio, zu untersuchen, um seine Fähigkeiten weiter zu verbessern. Dies könnte Türen zu einer Reihe neuer Anwendungen öffnen, die ein umfassendes multimodales Verständnis erfordern.
Die frühe Fusionsarchitektur von Chameleon ist ebenfalls sehr vielversprechend, insbesondere in Bereichen wie der Robotik. Forscher könnten möglicherweise fortschrittlichere und reaktionsfähigere KI-gesteuerte Roboter indem sie diese Technologie in ihre Steuerungssysteme integrieren. Die Fähigkeit des Modells, multimodale Eingaben zu verarbeiten, könnte auch zu komplexeren Interaktionen und Anwendungen führen.
Unser Kommentar
Die Einführung von Chameleon durch Meta stellt eine spannende Entwicklung in der multimodalen LLM-Landschaft dar. Seine Early-Fusion-Architektur und beeindruckende Leistung bei verschiedenen Aufgaben unterstreichen sein Potenzial, multimodale KI-Anwendungen zu revolutionieren. Da Meta die Fähigkeiten von Chameleon weiter verbessert und erweitert, könnte es einen neuen Commonplace für KI-Modelle zur Integration und Verarbeitung unterschiedlicher Arten von Informationen setzen. Die Zukunft sieht für Chameleon vielversprechend aus und wir erwarten, dass es sich auf verschiedene Branchen und Anwendungen auswirken wird.
Folge uns auf Google Nachrichten um über die neuesten Innovationen in der Welt der KI, Information Science und GenAI.