
Google hat kürzlich sein intelligentestes Modell veröffentlicht, das über mehrere Modalitäten hinweg erstellen, argumentieren und verstehen kann. Google Gemini 3 Professional ist nicht nur ein inkrementelles Replace, sondern tatsächlich ein großer Fortschritt in der KI-Fähigkeit. Dieses Modell mit modernster Argumentation, multimodalem Verständnis und Agentenfähigkeiten wird der Hauptfaktor sein, der die Artwork und Weise verändert, wie Entwickler intelligente Anwendungen erstellen. Und mit der neuen Gemini 3 Professional API können Entwickler jetzt intelligentere und dynamischere Systeme als je zuvor erstellen.
Wenn Sie komplexe KI-Workflows erstellen, mit multimodalen Daten arbeiten oder Agentensysteme entwickeln, die mehrstufige Aufgaben selbstständig verwalten können, erfahren Sie in diesem Leitfaden alles über die Nutzung von Gemini 3 Professional über seine API.
Was macht Gemini 3 Professional so besonders?
Lassen wir uns nicht in den technischen Particulars verlieren und besprechen wir zunächst die Gründe für die Begeisterung der Entwickler für dieses Modell. Das Google Gemini 3 Professional-Modell, das sich schon seit einiger Zeit in der Entwicklung befindet, hat es nun mit einem fantastischen Ergebnis ganz oben auf der KI-Benchmarking-Liste geschafft Elo-Bewertung von 1501und es battle nicht nur darauf ausgelegt, maximale Leistung zu liefern, sondern das Gesamtpaket battle auf ein großartiges Erlebnis für den Entwickler ausgerichtet.
Die Hauptmerkmale sind:
- Erweiterte Argumentation: Das Modell ist nun in der Lage, komplizierte, mehrstufige Probleme mit sehr subtilem Denken zu lösen.
- Riesiges Kontextfenster: Ein riesiger 1-Millionen-Token-Eingabekontext ermöglicht die Einspeisung ganzer Codebasen, Bücher in voller Länge oder langer Videoinhalte.
- Multimodale Beherrschung: Texte, Bilder, Movies, PDFs und Code können auf sehr reibungslose Weise zusammen verarbeitet werden.
- Agenten-Workflows: Führen Sie mehrstufige Aufgaben aus, bei denen das Modell seine Aktion als Roboter orchestriert, überprüft und modifiziert.
- Dynamisches Denken: Je nach State of affairs geht das Modell das Drawback entweder Schritt für Schritt durch oder gibt nur die Antwort.
Weitere Informationen zum Gemini 3 Professional-Modell und seinen Funktionen finden Sie im folgenden Artikel: Gemini 3 Professional
Erste Schritte: Ihr erster Gemini 3 Professional API-Aufruf
Schritt 1: Holen Sie sich Ihren API-Schlüssel
Gehe zu Google AI Studio und melden Sie sich mit Ihrem Google-Konto an. Klicken Sie nun oben rechts auf das Profilsymbol und wählen Sie dann „Holen Sie sich den API-Schlüssel”-Choice. Wenn es Ihr erstes Mal ist, wählen Sie „Erstellen Sie einen API-Schlüssel in einem neuen ProjektAndernfalls importieren Sie einen vorhandenen. Erstellen Sie sofort eine Kopie des API-Schlüssels, da Sie ihn dann nicht mehr sehen können.
Schritt 2: Installieren Sie das SDK
Wählen Sie Ihre bevorzugte Sprache und installieren Sie das offizielle SDK mit den folgenden Befehlen:
Python:
pip set up google-genaiNode.js/JavaScript:
npm set up @google/genaiSchritt 3: Legen Sie Ihre Umgebungsvariable fest
Speichern Sie Ihren API-Schlüssel sicher in einer Umgebungsvariablen:
export GEMINI_API_KEY="your-api-key-here"Gemini 3 Professional API-Preise
Die Gemini 3 Professional API nutzt a Pay-as-you-go Modell, bei dem Ihre Kosten hauptsächlich anhand der Anzahl berechnet werden Token wird sowohl für Ihre Eingabe (Eingabeaufforderungen) als auch für die Ausgabe des Modells (Antworten) verbraucht.
Der entscheidende Faktor für die Preisstufe ist die Länge des Kontextfensters Ihrer Anfrage. Längere Kontextfenster, die es dem Modell ermöglichen, mehr Informationen gleichzeitig zu verarbeiten (wie große Dokumente oder lange Gesprächsverläufe), führen zu einer höheren Fee.
Es gelten folgende Tarife gemini-3-pro-preview Modell über die Gemini-API und werden gemessen professional eine Million Token (1 Mio.).
| Besonderheit | Kostenloses Kontingent | Bezahlte Stufe (professional 1 Mio. Token in USD) |
|---|---|---|
| Eingabepreis | Kostenlos (begrenzte tägliche Nutzung) |
2,00 $, Eingabeaufforderungen ≤ 200.000 Token |
| Ausgabepreis (einschließlich Denktokens) | Kostenlos (begrenzte tägliche Nutzung) |
12,00 $, Eingabeaufforderungen ≤ 200.000 Token |
| Preis für Kontext-Caching | Nicht verfügbar |
0,20–0,40 $ professional 1 Mio. Token (abhängig von der Größe der Eingabeaufforderung) |
| Erdung mit der Google-Suche | Nicht verfügbar |
1.500 RPD (kostenlos) |
| Erdung mit Google Maps | Nicht verfügbar | Nicht verfügbar |
Die neuen Parameter von Gemini 3 Professional verstehen
Die API bietet mehrere revolutionäre Parameter, darunter den Parameter „Denkebene“, der dem Anforderer auf sehr detaillierte Weise die volle Kontrolle darüber gibt.
Der Denkebenenparameter
Dieser neue Parameter ist höchstwahrscheinlich der bedeutendste. Sie müssen sich nicht länger fragen, wie viel das Modell „denken“ soll, sondern es wird explizit von Ihnen gesteuert:
- think_level: „niedrig“: Für grundlegende Aufgaben wie Klassifizierung, Fragen und Antworten oder Chatten. Die Latenz ist sehr gering und die Kosten sind geringer, was es perfekt für Anwendungen mit hohem Durchsatz macht.
- think_level: „hoch“ (Commonplace): Für komplexe Denkaufgaben. Das Modell dauert länger, aber die Ausgabe wird aus einem sorgfältiger begründeten Argument bestehen. Dies ist die Zeit für Problemlösung und Analyse.
Tipp: Nicht verwenden thinking_level in Verbindung mit den Älteren thinking_budget Parameter, da sie nicht kompatibel sind und zu einem 400-Fehler führen.
Steuerung der Medienauflösung
Bei der Analyse von Bildern, PDF-Dokumenten oder Movies können Sie jetzt die Nutzung des virtuellen Prozessors bei der Analyse visueller Eingaben regulieren:
- Bilder:
media_resolution_highfür die beste Qualität (1120 Token/Bild). - PDFs:
media_resolution_mediumzum Dokumentenverständnis (560 Token). - Movies:
media_resolution_lowzur Aktionserkennung (70 Token/Body) undmedia_resolution_highfür konversationsintensiven Textual content (280 Token/Body).
Dadurch liegt die Optimierung der Qualität und Token-Nutzung in Ihren Händen.
Temperatureinstellungen
Folgendes könnte für Sie interessant sein: Sie können die Temperatur einfach auf dem Standardwert von 1,0 belassen. Im Gegensatz zu früheren Modellen, die die Temperaturanpassung häufig produktiv nutzten, ist die Argumentation des Gemini 3 auf diese Standardeinstellung optimiert. Das Absenken der Temperatur kann zu seltsamen Schleifen führen oder die Leistung bei komplexeren Aufgaben beeinträchtigen.
Bauen Sie mit mir: Praktische Beispiele der Gemini 3 Professional-API
Demo 1: Erstellen eines Good Code Analyzers
Lassen Sie uns etwas anhand eines realen Anwendungsfalls erstellen. Wir erstellen ein System, das zunächst den Code analysiert, Unstimmigkeiten identifiziert und mithilfe der erweiterten Argumentationsfunktion von Gemini 3 Professional Verbesserungen vorschlägt.
Python-Implementierung
import os
from google import genai
# Initialize the Gemini API consumer along with your API key
# You'll be able to set this straight or through setting variable
api_key = "api-key" # Substitute along with your precise API key
consumer = genai.Shopper(api_key=api_key)
def analyze_code(code_snippet: str) -> str:
"""
Analyzes code for discrepancies and suggests enhancements utilizing Gemini 3 Professional.
Args:
code_snippet: The code to research
Returns:
Evaluation and enchancment options from the mannequin
"""
response = consumer.fashions.generate_content(
mannequin="gemini-3-pro-preview",
contents=(
{
"textual content": f"""Analyze this code for points, inefficiencies, and potential enhancements.
Present:
1. Points discovered (bugs, logic errors, safety considerations)
2. Efficiency optimizations
3. Code high quality enhancements
4. Greatest practices violations
5. Refactored model with explanations
Code to research:
{code_snippet}
Be direct and concise in your evaluation."""
}
)
)
return response.textual content
# Instance utilization
sample_code = """
def calculate_total(objects):
whole = 0
for i in vary(len(objects)):
whole = whole + objects(i)('worth') * objects(i)('amount')
return whole
def get_user_data(user_id):
import requests
response = requests.get(f"http://api.instance.com/consumer/{user_id}")
knowledge = response.json()
return knowledge
"""
print("=" * 60)
print("GEMINI 3 PRO - SMART CODE ANALYZER")
print("=" * 60)
print("nAnalyzing code...n")
# Run the evaluation
evaluation = analyze_code(sample_code)
print(evaluation)
print("n" + "=" * 60)Ausgabe:
Was passiert hier?
- Wir setzen um
thinking_level ("excessive")da die Codeüberprüfung einige ausführliche Überlegungen erfordert. - Die Aufforderung ist kurz und prägnant Zwillinge 3 Reagiert effektiver, wenn die Eingabeaufforderungen direkt sind, anstatt aufwändige Eingabeaufforderungen zu verwenden.
- Das Modell überprüft den Code mit voller Argumentationskapazität und stellt eine reaktionsfähige Model bereit, die wichtige Überarbeitungen und aufschlussreiche Analysen enthält.
Demo 2: Multimodale Dokumentenintelligenz
Betrachten wir nun einen komplexeren Anwendungsfall, der darin besteht, ein Bild eines Dokuments zu analysieren und strukturierte Informationen zu extrahieren.
Python-Implementierung
import base64
import json
from google import genai
# Initialize the Gemini API consumer
api_key = "api-key-here" # Substitute along with your precise API key
consumer = genai.Shopper(api_key=api_key)
def analyze_document_image(image_path: str) -> dict:
"""
Analyzes a doc picture and extracts key info.
Handles photographs, PDFs, and different doc codecs.
Args:
image_path: Path to the doc picture file
Returns:
Dictionary containing extracted doc info as JSON
"""
# Learn and encode the picture
with open(image_path, "rb") as img_file:
image_data = base64.standard_b64encode(img_file.learn()).decode()
# Decide the MIME sort based mostly on file extension
mime_type = "picture/jpeg" # Default
if image_path.endswith(".png"):
mime_type = "picture/png"
elif image_path.endswith(".pdf"):
mime_type = "utility/pdf"
elif image_path.endswith(".gif"):
mime_type = "picture/gif"
elif image_path.endswith(".webp"):
mime_type = "picture/webp"
# Name the Gemini API with multimodal content material
response = consumer.fashions.generate_content(
mannequin="gemini-3-pro-preview",
contents=(
{
"textual content": """Extract and construction all info from this doc picture.
Return the information as JSON with these fields:
- document_type: What sort of doc is that this?
- key_entities: Listing of vital names, dates, quantities, and so on.
- main_content: Transient abstract of the doc's objective
- action_items: Any duties or deadlines talked about
- confidence: How assured you're within the extraction (excessive/medium/low)
Return ONLY legitimate JSON, no markdown formatting."""
},
{
"inline_data": {
"mime_type": mime_type,
"knowledge": image_data
}
}
)
)
# Parse the JSON response
strive:
end result = json.masses(response.textual content)
return end result
besides json.JSONDecodeError:
return {
"error": "Did not parse response",
"uncooked": response.textual content
}
# Instance utilization with a pattern doc
print("=" * 70)
print("GEMINI 3 PRO - MULTI-MODAL DOCUMENT INTELLIGENCE")
print("=" * 70)
document_path = "Gemini-3-Professional-Mannequin-Card.pdf" # Change this to your precise doc path
strive:
print(f"nAnalyzing doc: {document_path}")
print("Processing...n")
document_info = analyze_document_image(document_path)
print("Extracted Doc Info:")
print("-" * 70)
print(json.dumps(document_info, indent=2))
besides FileNotFoundError:
print(f"Error: Doc file '{document_path}' not discovered.")
print("Please present a legitimate path to a doc picture (JPG, PNG, PDF, and so on.)")
print("nExample:")
print(' document_info = analyze_document_image("bill.pdf")')
print(' document_info = analyze_document_image("contract.png")')
print(' document_info = analyze_document_image("receipt.jpg")')
besides Exception as e:
print(f"Error processing doc: {str(e)}")
print("n" + "=" * 70)Ausgabe:
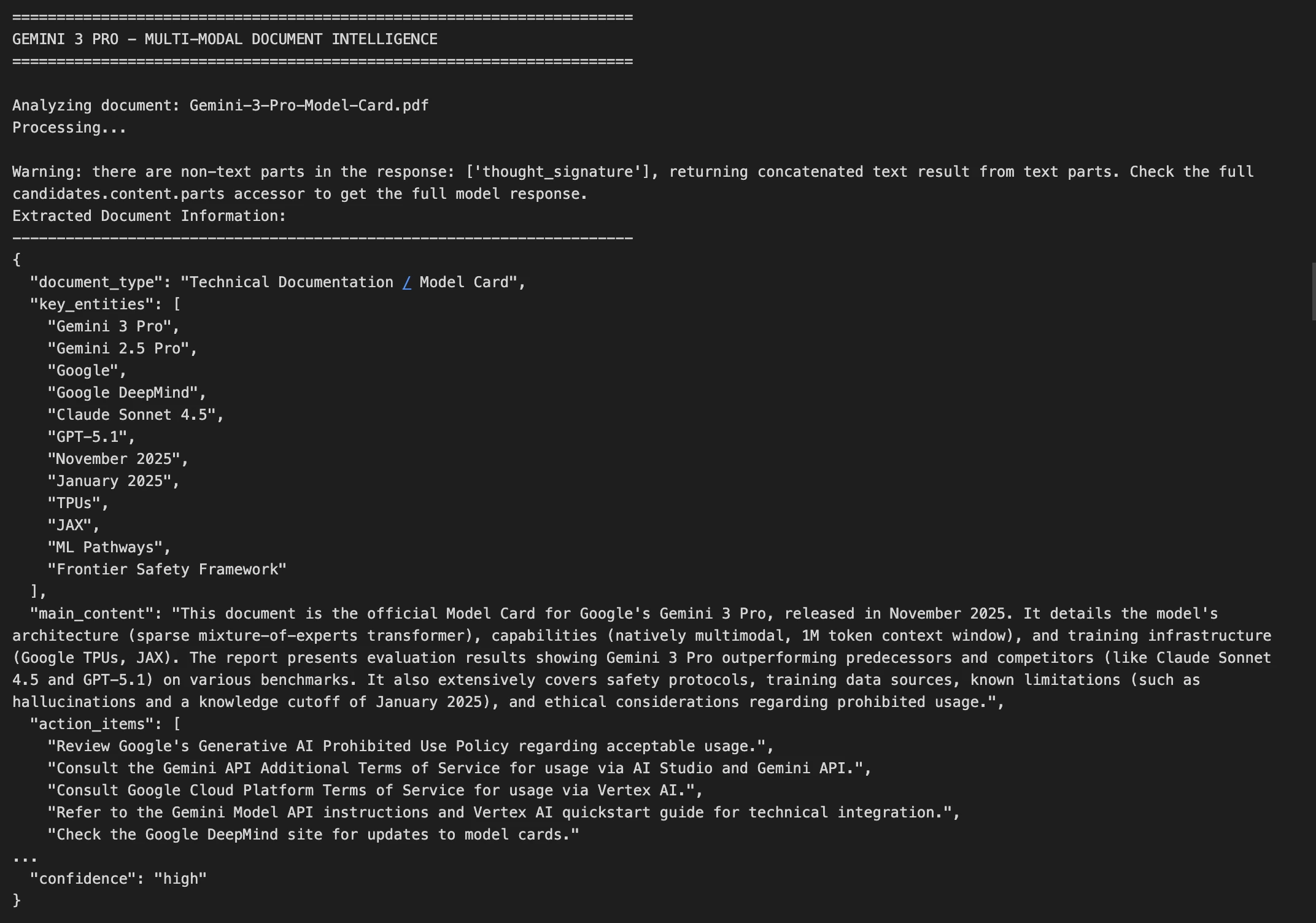
Schlüsseltechniken hier:
- Bildbearbeitung: Wir kodieren das Bild für die Auslieferung im Base64-Format
- Maximale Qualitätsoption: Für Textdokumente bewerben wir uns
media_resolution_highum eine perfekte OCR zu gewährleisten - Geordnetes Ergebnis: Wir verlangen ein JSON-Format, das sich leicht mit anderen Systemen verbinden lässt
- Fehlerbehandlung: Wir machen es so, dass JSON-Parsing-Fehler nicht auffallen
Erweiterte Funktionen: Über die einfache Eingabeaufforderung hinaus
Gedankensignaturen: Argumentationskontext aufrechterhalten
Gemini 3 Professional führt eine erstaunliche Funktion ein, die als Gedankensignaturen bekannt ist und verschlüsselte Darstellungen der internen Argumentation dieses Modells enthält. Diese Modellsignaturen halten den Kontext über die API-Aufrufe hinweg fest, wenn Funktionsaufrufe oder Konversationen mit mehreren Runden verwendet werden.
Wenn Sie lieber den Beamten verwenden möchten Python oder Node.js SDKs-Methode verwenden, werden diese Gedankensignaturen automatisch und unsichtbar verarbeitet. Wenn Sie jedoch einen Roh-API-Aufruf durchführen, müssen Sie die Signatur genau so zurückgeben, wie sie empfangen wurde.
Kontext-Caching zur Kostenoptimierung
Planen Sie, ähnliche Anfragen mehrmals zu senden? Nutzen Sie das Kontext-Caching, das die ersten 2.048 Token Ihrer Eingabeaufforderung zwischenspeichern kann, und sparen Sie Geld bei nachfolgenden Anfragen. Dies ist immer dann fantastisch, wenn Sie eine Reihe von Dokumenten verarbeiten und zwischendurch eine Systemeingabeaufforderung wiederverwenden können.
Batch-API: Prozess im Maßstab
Bei nicht zeitkritischen Arbeitslasten können Sie mit der Batch-API bis zu 90 % einsparen. Dies ist ideally suited für Arbeitslasten, bei denen viele Dokumente verarbeitet werden müssen oder wenn Sie über Nacht eine große Analyse durchführen möchten.
Abschluss
Google Gemini 3 Professional markiert einen Wendepunkt in dem, was mit KI-APIs möglich ist. Die Kombination aus fortschrittlichem Denken, umfangreichen Kontextfenstern und erschwinglichen Preisen bedeutet, dass Sie jetzt Systeme erstellen können, die zuvor unpraktisch waren.
Fangen Sie klein an: Baue ein Chatboteinige Dokumente analysieren oder eine Routineaufgabe automatisieren. Wenn Sie sich dann mit der API vertraut gemacht haben, erkunden Sie komplexere Szenarien wie autonome Agenten, Codegenerierung und multimodale Analyse.
Häufig gestellte Fragen
A. Seine fortschrittliche Argumentation, die multimodale Unterstützung und das große Kontextfenster ermöglichen intelligentere und leistungsfähigere Anwendungen.
A. Stellen Sie „Thinking_Level“ für schnelle/einfache Aufgaben auf „niedrig“ und für komplexe Analysen auf „hoch“ ein.
A. Verwenden Sie Kontext-Caching oder die Batch-API, um Eingabeaufforderungen wiederzuverwenden und Workloads effizient auszuführen.
Information Science Trainee bei Analytics Vidhya
Derzeit arbeite ich als Information Science Trainee bei Analytics Vidhya, wo ich mich auf die Entwicklung datengesteuerter Lösungen und die Anwendung von KI/ML-Techniken zur Lösung realer Geschäftsprobleme konzentriere. Meine Arbeit ermöglicht es mir, fortschrittliche Analysen, maschinelles Lernen und KI-Anwendungen zu erforschen, die es Unternehmen ermöglichen, intelligentere, evidenzbasierte Entscheidungen zu treffen.
Mit einem starken Fundament in den Bereichen Informatik, Softwareentwicklung und Datenanalyse ist es mir eine Leidenschaft, KI zu nutzen, um wirkungsvolle, skalierbare Lösungen zu schaffen, die die Lücke zwischen Technologie und Geschäft schließen.
📩 Du kannst mich auch erreichen unter (e mail protected)
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.