
OpenAI Canvas ist ein vielseitiges Device zur Optimierung der kollaborativen Codierung und Textbearbeitung. Mit seiner intuitiven Benutzeroberfläche bietet Canvas neben der KI-gesteuerten Unterstützung von ChatGPT eine dynamische Plattform für Entwickler zum Schreiben, Bearbeiten und Debuggen von Code. Dies macht es besonders nützlich für eine Vielzahl von Aufgaben, von der einfachen Skripterstellung bis hin zur Verwaltung komplexer Projekte. In diesem Artikel werde ich das Codieren mit Canvas untersuchen und meine Gesamterfahrung teilen.
Hauptmerkmale und Vorteile von Canvas
- Nahtlose Zusammenarbeit: Canvas integriert Konversationsschnittstellen und ermöglicht es Benutzern, Ideen in Echtzeit zu ändern, Suggestions anzufordern oder zu erkunden, ohne das Device wechseln zu müssen.
- Dynamische Codierungsumgebung: Canvas wurde für Python-Entwickler entwickelt und unterstützt die Codeausführung, was es supreme für Aufgaben wie Datenanalyse, Codierung und Visualisierung macht.
- Multifunktionale Plattform: Canvas dient nicht nur der Textbearbeitung; Es ist ein vielseitiger Raum für Brainstorming, Programmierung und strukturierte Arbeitsabläufe.
Kasse – Warum o1-Modell besser als GPT-4o
Praktisches Codieren mit Canvas
Erste Schritte
Ich habe die Codierungsfunktionen von Canvas mit dem Ziel untersucht, einen Datensatz anzuhängen und grundlegende Funktionen auszuführen explorative Datenanalyse (EDA). Obwohl die Benutzeroberfläche intuitiv und vielversprechend conflict, stieß ich bei der Integration externer Datensätze auf Herausforderungen.
Die Herausforderung: Zugriff auf Daten in der Sandbox
Beim Versuch, einen Datensatz anzuhängen, stellte ich fest, dass die Sandbox-Umgebung nicht auf die Datei zugreifen konnte. Um dieses Downside zu umgehen, habe ich eine Teilmenge der Daten direkt in Canvas eingefügt, das Downside wurde dadurch jedoch nicht behoben. Selbst bei korrekt geschriebenem Code blieb eine Fehlermeldung bestehen, die darauf hinweist, dass die Daten nicht gefunden werden konnten. Diese Einschränkung unterstreicht die Notwendigkeit verbesserter Datenintegrationsfunktionen in Canvas.
Synthetische Daten und Visualisierungen
Nachdem ich auf diese Einschränkungen gestoßen conflict, forderte ich Canvas auf, synthetische Daten zu generieren und Visualisierungen durchzuführen. Der folgende Code wurde generiert und erfolgreich ausgeführt:
Eingabeaufforderung: Erstellen Sie einen Datensatz und führen Sie anschließend einige Visualisierungen daraus durch.
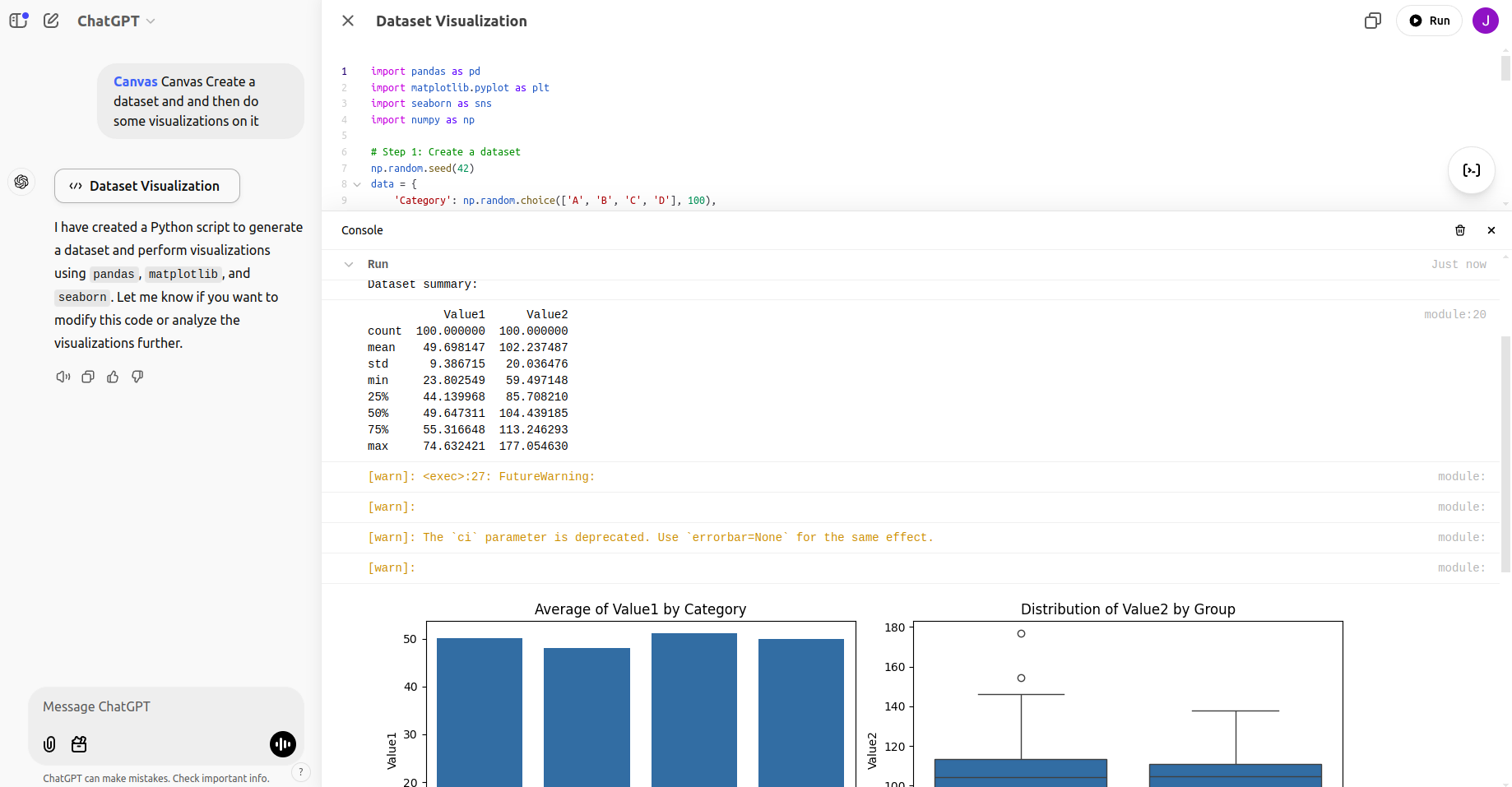
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Step 1: Create a dataset
np.random.seed(42)
knowledge = {
'Class': np.random.selection(('A', 'B', 'C', 'D'), 100),
'Value1': np.random.regular(50, 10, 100),
'Value2': np.random.regular(100, 20, 100),
'Group': np.random.selection(('X', 'Y'), 100)
}
df = pd.DataFrame(knowledge)
# Step 2: Show primary details about the dataset
print("Dataset preview:")
print(df.head())
print("nDataset abstract:")
print(df.describe())
# Step 3: Visualizations
plt.determine(figsize=(12, 8))
# Bar plot: Common of Value1 by Class
plt.subplot(2, 2, 1)
sns.barplot(x='Class', y='Value1', knowledge=df, ci=None)
plt.title('Common of Value1 by Class')
# Field plot: Distribution of Value2 by Group
plt.subplot(2, 2, 2)
sns.boxplot(x='Group', y='Value2', knowledge=df)
plt.title('Distribution of Value2 by Group')
# Scatter plot: Value1 vs. Value2
plt.subplot(2, 2, 3)
sns.scatterplot(x='Value1', y='Value2', hue="Class", knowledge=df)
plt.title('Scatter plot of Value1 vs Value2')
# Histogram: Distribution of Value1
plt.subplot(2, 2, 4)
sns.histplot(df('Value1'), kde=True, bins=20)
plt.title('Histogram of Value1')
plt.tight_layout()
plt.present()
Und beim Ausführen conflict dies die Ausgabe:
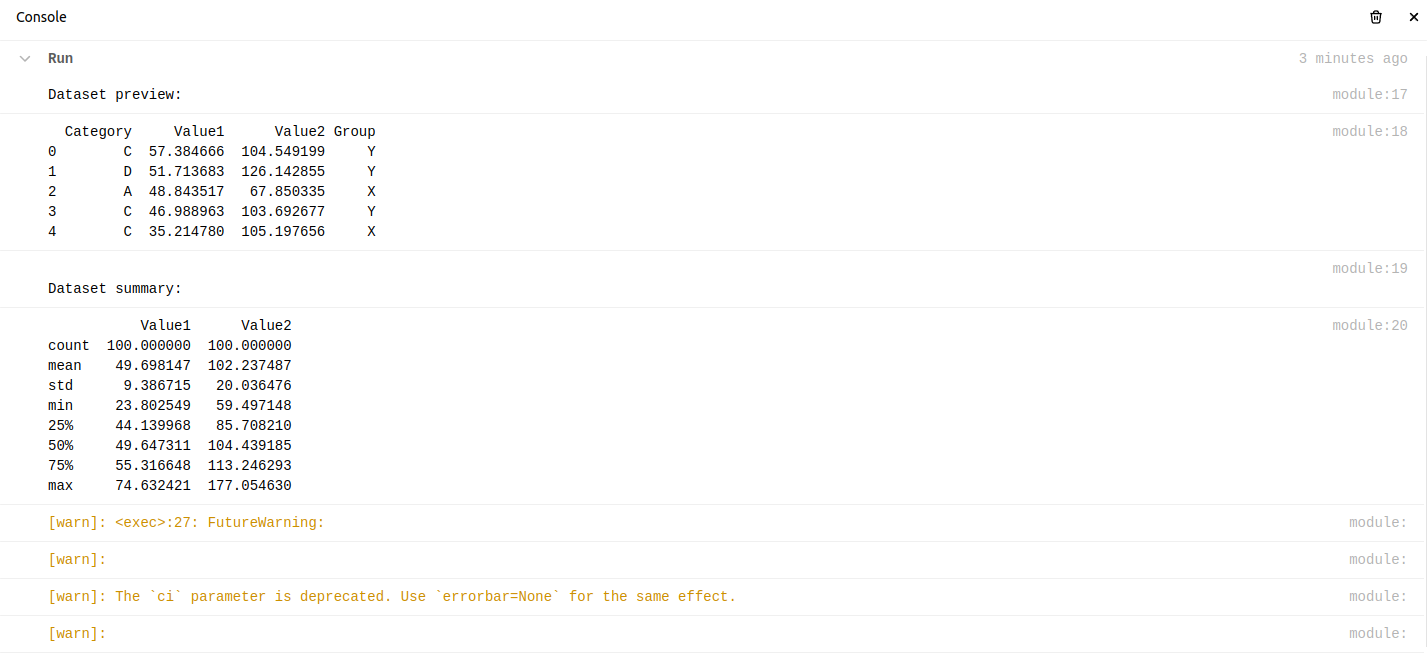
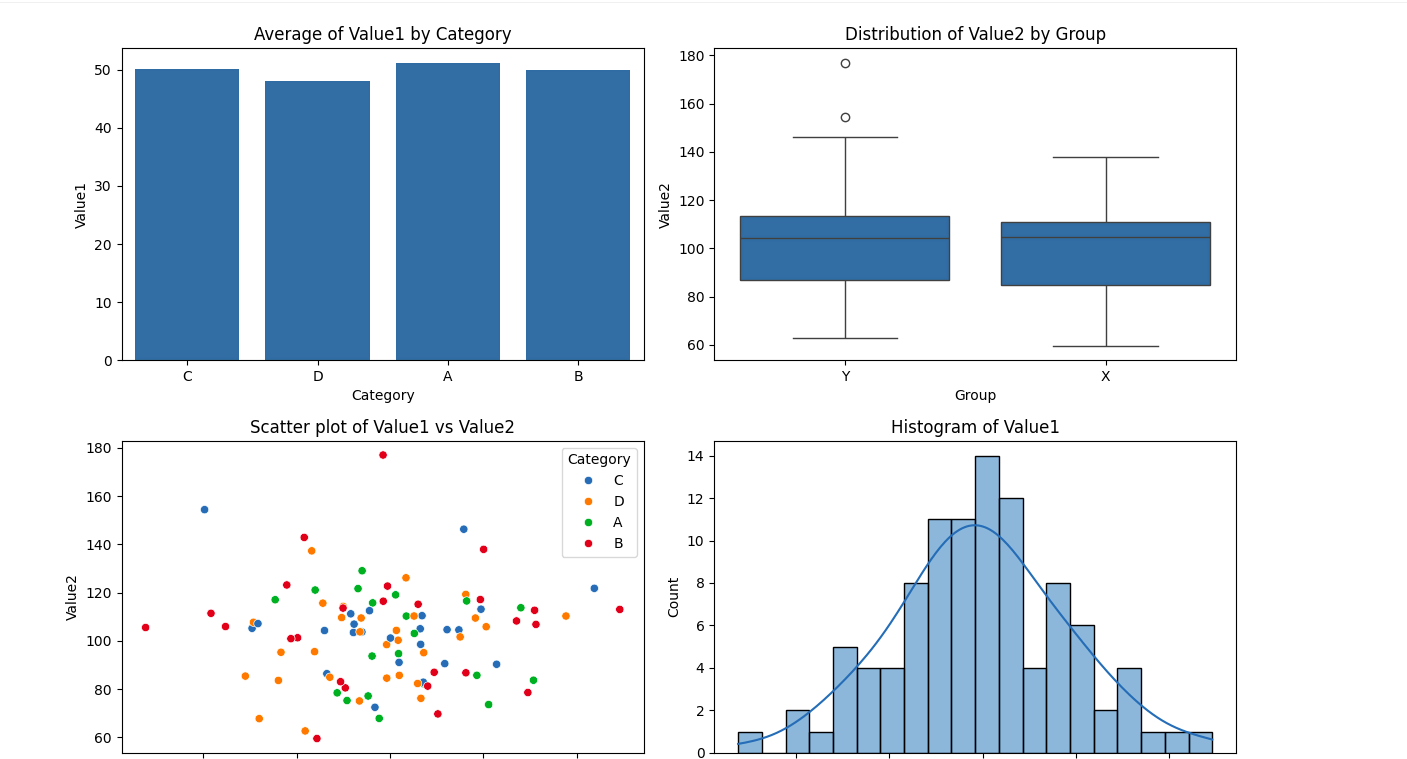
Die Ergebnisse waren visuell aufschlussreich und zeigten die Fähigkeit der Plattform, grundlegende EDA-Aufgaben effektiv zu bewältigen. Anschließend führte ich eine erweiterte EDA durch, um tiefere Erkenntnisse zu gewinnen:
Beim Ausführen dieses erweiterten EDA ist dieser Fehler aufgetreten:
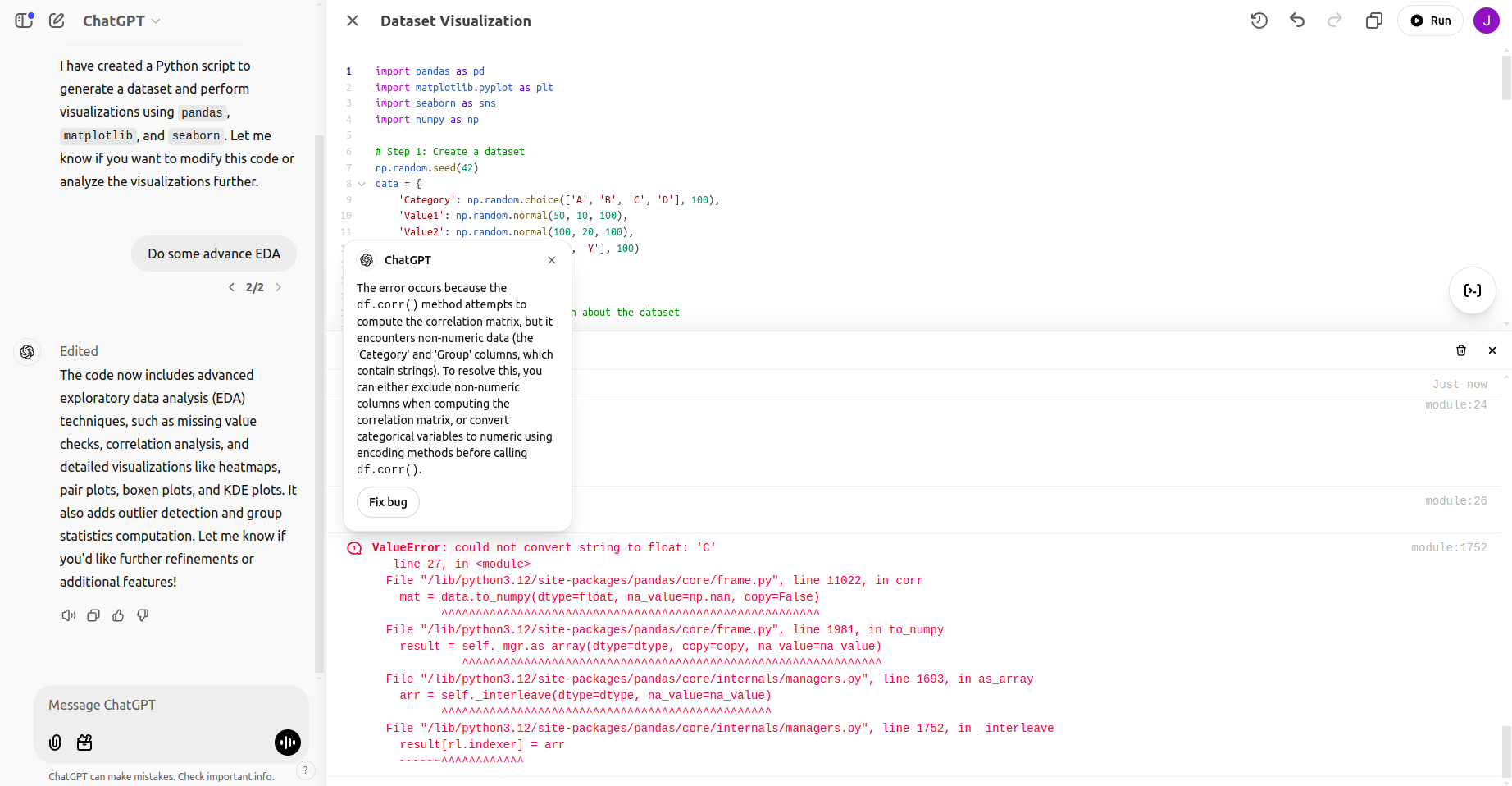
Nach Behebung des Fehlers:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Step 1: Create a dataset
np.random.seed(42)
knowledge = {
'Class': np.random.selection(('A', 'B', 'C', 'D'), 100),
'Value1': np.random.regular(50, 10, 100),
'Value2': np.random.regular(100, 20, 100),
'Group': np.random.selection(('X', 'Y'), 100)
}
df = pd.DataFrame(knowledge)
# Step 2: Show primary details about the dataset
print("Dataset preview:")
print(df.head())
print("nDataset abstract:")
print(df.describe())
# Superior EDA
print("nChecking for lacking values:")
print(df.isnull().sum())
# Guarantee solely numeric knowledge is used for correlation matrix
print("nCorrelation matrix:")
numeric_df = df.select_dtypes(embody=(np.quantity))
correlation_matrix = numeric_df.corr()
print(correlation_matrix)
# Visualizations for superior EDA
plt.determine(figsize=(15, 12))
# Heatmap of correlation matrix
plt.subplot(3, 2, 1)
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Matrix Heatmap')
# Pairplot for relationships
sns.pairplot(df, hue="Class", nook=True, diag_kind='kde')
plt.suptitle('Pairplot of Variables', y=1.02)
plt.present()
# Boxen plot: Distribution of Value1 by Class and Group
plt.subplot(3, 2, 2)
sns.boxenplot(x='Class', y='Value1', hue="Group", knowledge=df)
plt.title('Boxen plot of Value1 by Class and Group')
# Violin plot: Distribution of Value2 by Class
plt.subplot(3, 2, 3)
sns.violinplot(x='Class', y='Value2', knowledge=df, hue="Group", break up=True)
plt.title('Violin plot of Value2 by Class')
# Rely plot: Frequency of Classes
plt.subplot(3, 2, 4)
sns.countplot(x='Class', knowledge=df, hue="Group")
plt.title('Frequency of Classes by Group')
# KDE plot: Distribution of Value1 and Value2
plt.subplot(3, 2, 5)
sns.kdeplot(x='Value1', y='Value2', hue="Class", knowledge=df, fill=True, alpha=0.6)
plt.title('KDE plot of Value1 vs Value2')
plt.tight_layout()
plt.present()
# Outlier detection
print("nIdentifying potential outliers:")
for column in ('Value1', 'Value2'):
Q1 = df(column).quantile(0.25)
Q3 = df(column).quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df((df(column) < lower_bound) | (df(column) > upper_bound))
print(f"Outliers in {column}:n", outliers)
# Group statistics
print("nGroup statistics:")
print(df.groupby(('Class', 'Group')).agg({'Value1': ('imply', 'std'), 'Value2': ('imply', 'std')}))
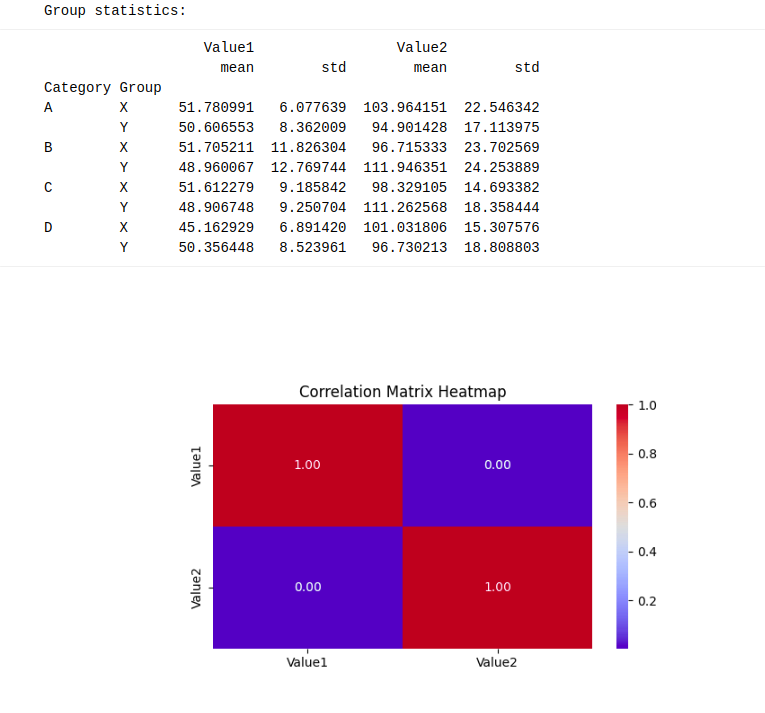
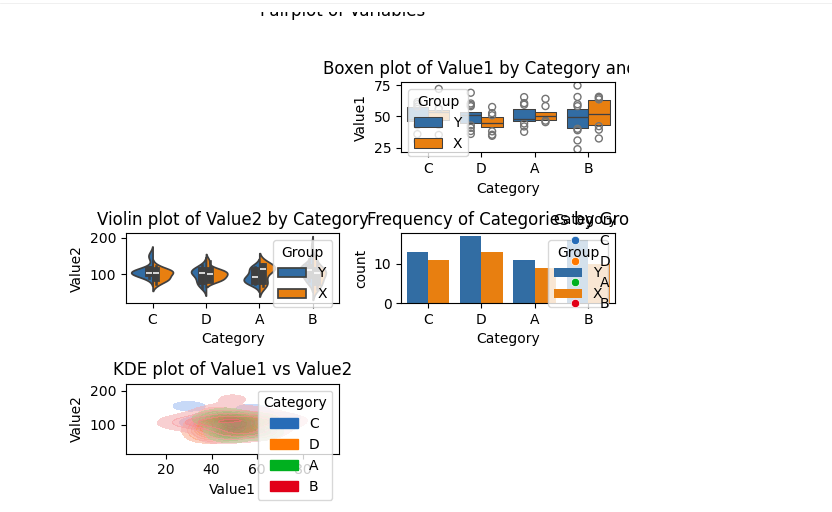
Diese erweiterten Analysen verdeutlichten die Fähigkeiten von Canvas für explorative Aufgaben, verdeutlichten aber auch die Einschränkungen der Plattform bei der Integration externer Datensätze.
Code in andere Sprachen portieren
Während Canvas das Codieren hauptsächlich in Python unterstützt, ermöglicht die Plattform Benutzern die Portierung von Python-Code in andere Sprachen, beispielsweise Java. Es führt jedoch keinen Code in anderen Sprachen als Python aus. Hier ist ein Beispiel für einen Python-zu-Java-Port:
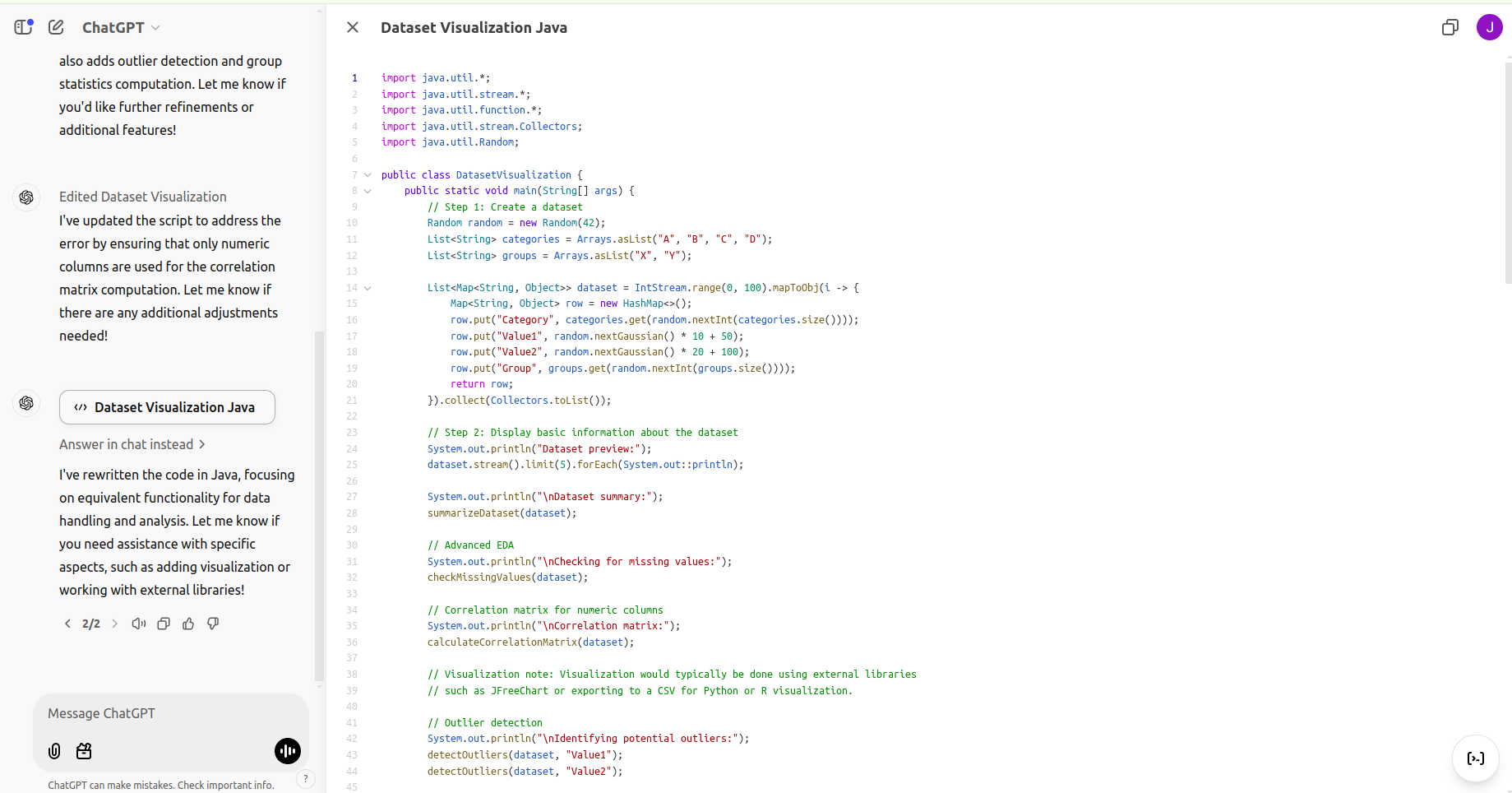
import java.util.*;
import java.util.stream.Collectors;
public class DatasetVisualization {
public static void primary(String() args) {
// Step 1: Create an artificial dataset
Random random = new Random(42); // For reproducibility
Checklist<Integer> ages = random.ints(200, 18, 70).boxed().acquire(Collectors.toList());
Checklist<Integer> incomes = random.ints(200, 30000, 120000).boxed().acquire(Collectors.toList());
Checklist<String> genders = random.ints(200, 0, 2).mapToObj(i -> i == 0 ? "Male" : "Feminine").acquire(Collectors.toList());
Checklist<Integer> spendScores = random.ints(200, 1, 101).boxed().acquire(Collectors.toList());
Checklist<String> cities = random.ints(200, 0, 5).mapToObj(i -> {
swap (i) {
case 0: return "New York";
case 1: return "Los Angeles";
case 2: return "Chicago";
case 3: return "Houston";
default: return "Phoenix";
}
}).acquire(Collectors.toList());
// Step 2: Create demographic segments
Checklist<String> ageGroups = ages.stream().map(age -> {
if (age <= 30) return "Younger";
else if (age <= 50) return "Center-aged";
else return "Senior";
}).acquire(Collectors.toList());
Checklist<String> incomeGroups = incomes.stream().map(revenue -> {
if (revenue < 40000) return "Low";
else if (revenue <= 70000) return "Medium";
else return "Excessive";
}).acquire(Collectors.toList());
// Step 3: Print a abstract of the dataset
System.out.println("Pattern of the dataset:");
for (int i = 0; i < 5; i++) {
System.out.printf("Age: %d, Earnings: %d, Gender: %s, Spend Rating: %d, Metropolis: %s, Age Group: %s, Earnings Group: %sn",
ages.get(i), incomes.get(i), genders.get(i), spendScores.get(i), cities.get(i), ageGroups.get(i), incomeGroups.get(i));
}
// Step 4: Carry out a correlation-like evaluation (simplified for Java)
double ageIncomeCorrelation = calculateCorrelation(ages, incomes);
double ageSpendScoreCorrelation = calculateCorrelation(ages, spendScores);
double incomeSpendScoreCorrelation = calculateCorrelation(incomes, spendScores);
System.out.println("nCorrelation Evaluation:");
System.out.printf("Age-Earnings Correlation: %.2fn", ageIncomeCorrelation);
System.out.printf("Age-Spend Rating Correlation: %.2fn", ageSpendScoreCorrelation);
System.out.printf("Earnings-Spend Rating Correlation: %.2fn", incomeSpendScoreCorrelation);
// Visualizations would usually require a separate library for Java, corresponding to JFreeChart or JavaFX.
System.out.println("nVisualizations will not be applied on this text-based instance.");
}
// Helper technique to calculate a simplified correlation
non-public static double calculateCorrelation(Checklist<Integer> x, Checklist<Integer> y) {
if (x.dimension() != y.dimension()) throw new IllegalArgumentException("Lists will need to have the identical dimension");
int n = x.dimension();
double meanX = x.stream().mapToDouble(a -> a).common().orElse(0);
double meanY = y.stream().mapToDouble(a -> a).common().orElse(0);
double covariance = 0;
double varianceX = 0;
double varianceY = 0;
for (int i = 0; i < n; i++) {
double deltaX = x.get(i) - meanX;
double deltaY = y.get(i) - meanY;
covariance += deltaX * deltaY;
varianceX += deltaX * deltaX;
varianceY += deltaY * deltaY;
}
return covariance / Math.sqrt(varianceX * varianceY);
}
}
Obwohl der Java-Code Funktionen für die Erstellung von Datensätzen und einfache Analysen bereitstellt, wären für die weitere Entwicklung zusätzliche Bibliotheken erforderlich Visualisierung.
Meine Erfahrung mit Canvas
Obwohl Canvas Python unterstützt, kann die Integration externer Datensätze aufgrund von Sandbox-Einschränkungen eine Herausforderung darstellen. Allerdings können diese Probleme durch die Generierung synthetischer Daten in Canvas oder den Import von Teilmengen von Datensätzen gemildert werden. Darüber hinaus kann Python-Code in andere Sprachen portiert werden, obwohl die Ausführung außerhalb von Python in Canvas nicht unterstützt wird.
Insgesamt bietet Canvas eine benutzerfreundliche und kollaborative Umgebung. Eine verbesserte Fähigkeit zur Integration externer Daten und die Unterstützung weiterer Programmiersprachen würden es noch vielseitiger und nützlicher machen.
Abschluss
Das Codieren mit ChatGPT Canvas kombiniert KI-Unterstützung mit einem kollaborativen Arbeitsbereich und macht es so zu einem praktischen Werkzeug für Entwickler. Egal, ob Sie Code debuggen, Daten analysieren oder Ideen sammeln, Canvas vereinfacht den Prozess und steigert die Produktivität.
Haben Sie versucht, mit Canvas zu programmieren? Teilen Sie Ihre Erfahrungen mit und lassen Sie mich im Kommentarbereich unten wissen, wie es für Sie funktioniert hat.
Bleiben Sie dran Analytics Vidhya Weblog für weitere solcher Updates!
Häufig gestellte Fragen
ChatGPT Canvas ist eine Funktion, die es Benutzern ermöglicht, lange Dokumente oder Code direkt neben ihren Gesprächen mit ChatGPT zu bearbeiten, zusammenzuarbeiten und zu verfeinern.
OpenAI bietet kostenlosen Zugriff auf einige Funktionen von ChatGPT, für erweiterte Funktionen und Modelle ist jedoch häufig ein kostenpflichtiges Abonnement erforderlich.
Ja, mit OpenAI Canvas können Benutzer Code direkt neben KI-gestützten Vorschlägen bearbeiten und verfeinern.
Hallo, ich bin Janvi, ein leidenschaftlicher Knowledge-Science-Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Welt der Daten begann mit einer tiefen Neugier, wie wir aus komplexen Datensätzen aussagekräftige Erkenntnisse gewinnen können.