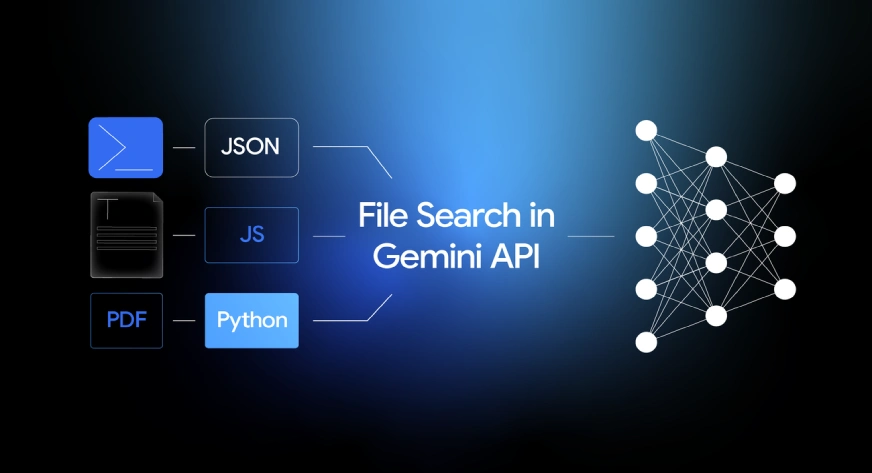
Der Aufbau eines RAG-Methods ist jetzt viel einfacher. Google hat die Dateisuche eingeführt, eine verwaltete Dateisuche LAPPEN Funktion für die Gemini-API, die die schwere Arbeit beim Verbinden von LLMs mit Ihren Daten übernimmt. Vergessen Sie die Verwaltung von Chunking, Einbettungen oder Vektordatenbanken: File Search erledigt alles. Dadurch können Sie die Infrastrukturprobleme überspringen und sich auf das Wesentliche konzentrieren: die Erstellung einer großartigen Anwendung. In diesem Leitfaden untersuchen wir die Funktionsweise der Dateisuche und gehen anhand praktischer Python-Beispiele durch die Implementierung.
Was bewirkt die Dateisuche?
Mit der Dateisuche kann Gemini Informationen aus proprietären Datenquellen wie Berichten, Dokumenten und Codedateien verstehen und darauf verweisen.
Wenn eine Datei hochgeladen wird, teilt das System den Inhalt in kleinere Teile, sogenannte Chunks, auf. Anschließend erstellt es eine Einbettung, eine numerische Darstellung der Bedeutung für jeden Block, und speichert sie in einem Dateisuchspeicher.
Wenn ein Benutzer eine Frage stellt, durchsucht Gemini diese gespeicherten Einbettungen, um die relevantesten Abschnitte für den Kontext zu finden und abzurufen. Dieser Prozess ermöglicht es Gemini, genaue Antworten auf der Grundlage Ihrer spezifischen Informationen zu liefern, was eine Kernkomponente von RAG darstellt.
Lesen Sie auch: Erstellen eines LLM-Modells mit der Google Gemini API
Wie funktioniert die Dateisuche?
Die Dateisuche basiert auf der semantischen Vektorsuche. Anstatt Wörter direkt zuzuordnen, werden Informationen basierend auf Bedeutung und Kontext gefunden. Dies bedeutet, dass die Dateisuche relevante Informationen für Sie finden kann, selbst wenn der Wortlaut der Suchanfrage unterschiedlich ist.
Benötigte Zeit: 4 Minuten
So funktioniert es Schritt für Schritt:
- Laden Sie eine Datei hoch
Die Datei wird in kleinere Abschnitte unterteilt, die als „Chunks“ bezeichnet werden.
- Einbettungsgenerierung
Jeder Block würde in einen numerischen Vektor umgewandelt, der die Bedeutung dieses Blocks darstellt.
- Lagerung
Die Einbettungen werden in einem File Search Retailer gespeichert, einem eingebetteten Speicher, der speziell für den Abruf entwickelt wurde.
- Abfrage
Wenn ein Benutzer eine Frage stellt, wandelt File Search diese Frage in eine Einbettung um.
- Abruf
Der Abrufschritt vergleicht die Einbettung der Frage mit den gespeicherten Einbettungen und findet heraus, welche Blöcke am ähnlichsten sind (falls vorhanden).
- Erdung
Der Eingabeaufforderung des Gemini-Modells werden relevante Teile hinzugefügt, sodass die Antwort auf den Faktendaten aus den Dokumenten basiert.
Dieser gesamte Prozess wird über die Gemini-API abgewickelt. Der Entwickler muss keine zusätzliche Infrastruktur oder Datenbanken verwalten.
Setup-Anforderungen
Um das Dateisuchtool nutzen zu können, benötigen Entwickler einige grundlegende Komponenten. Sie benötigen Python 3.9 oder höher, die Google-Genai-Clientbibliothek und einen gültigen Gemini-API-Schlüssel, der Zugriff auf entweder gemini-2.5-pro oder gemini-2.5-flash hat.
Installieren Sie die Shopper-Bibliothek, indem Sie Folgendes ausführen:
pip set up google-genai -U Legen Sie dann Ihre Umgebungsvariable für den API-Schlüssel fest:
export GOOGLE_API_KEY="your_api_key_here"Erstellen eines Dateisuchspeichers
In einem Dateisuchspeicher speichert und indiziert Gemini Einbettungen, die aus Ihren hochgeladenen Dateien erstellt wurden. Die Einbettungen kapseln die Bedeutung Ihres Textes und werden weiterhin im Speicher gespeichert, wenn Sie die Originaldatei löschen.
from google import genai from google.genai import varieties
consumer = genai.Shopper()
retailer = consumer.file_search_stores.create( config={'display_name': 'my_rag_store'} ) print("File Search Retailer created:", retailer.identify)
Jedes Projekt kann insgesamt 10 Shops haben, wobei die Basisstufe ein Retailer-Restrict von 1 GB und ein höheres Degree von 1 TB hat.
Der Speicher ist ein persistentes Objekt, in dem Ihre indizierten Aufbewahrungsdaten gespeichert sind.
Laden Sie eine Datei hoch
Nachdem der Retailer geladen ist, können Sie eine Datei hochladen. Wenn eine Datei hochgeladen wird, teilt das Dateisuchtool die Datei automatisch auf, generiert Einbettungen und einen Index für einen schnellen Abrufvorgang.
# Add and import a file into the file search retailer, provide a novel file identify which shall be seen in citations
operation = consumer.file_search_stores.upload_to_file_search_store(
file="/content material/Paper2Agent.pdf",
file_search_store_name=file_search_store.identify,
config={
'display_name' : 'my_rag_store',
}
)
# Wait till import is full
whereas not operation.executed:
time.sleep(5)
operation = consumer.operations.get(operation)
print("File efficiently uploaded and listed.")
Die Dateisuche unterstützt PDF, DOCX, TXT, JSON und Programmierdateien mit den Erweiterungen .py und .js.
Nach dem Add-Schritt ist Ihre Datei aufgeteilt, eingebettet und bereit zum Abruf.
Stellen Sie Fragen zur Datei
Nach der Indexierung kann Gemini auf Anfragen basierend auf Ihrem Dokument antworten. Es findet die relevanten Abschnitte im Dateisuchspeicher und verwendet diese Abschnitte als Kontext für die Antwort.
# Ask a query in regards to the file
response = consumer.fashions.generate_content(
mannequin="gemini-2.5-flash",
contents="""Summarize what's there within the analysis paper""",
config=varieties.GenerateContentConfig(
instruments=(
varieties.Software(file_search=varieties.FileSearch(
file_search_store_names=(file_search_store.identify)
))
)
)
)
print("Mannequin Response:n")
print(response.textual content)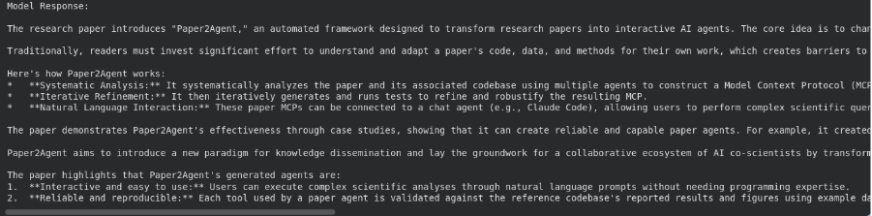
Hier wird die Dateisuche als Software innerhalb von generic_content() verwendet. Das Modell durchsucht zunächst Ihre gespeicherten Einbettungen, ruft die relevantesten Abschnitte ab und generiert dann eine Antwort basierend auf diesem Kontext.
Passen Sie die Chunking-Funktion an
Standardmäßig entscheidet die Dateisuche, wie Dateien in Blöcke aufgeteilt werden. Sie können dieses Verhalten jedoch steuern, um eine bessere Suchgenauigkeit zu erzielen.
operation = consumer.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.identify,
file="path/to/your/file.txt",
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 200,
'max_overlap_tokens': 20
}
}
}
) Diese Konfiguration legt jeden Block auf 200 Token mit 20 überlappenden Token fest, um eine reibungslosere Kontextkontinuität zu gewährleisten. Kürzere Abschnitte liefern feinere Suchergebnisse, während größere Abschnitte eine allgemeinere Bedeutung behalten, die für Forschungsarbeiten und Codedateien nützlich ist.
Verwalten Sie Ihre Dateisuchspeicher
Mithilfe der API können Sie Dateisuchspeicher ganz einfach auflisten, anzeigen und löschen.
print("n Accessible File Search Shops:")
for s in consumer.file_search_stores.record():
print(" -", s.identify)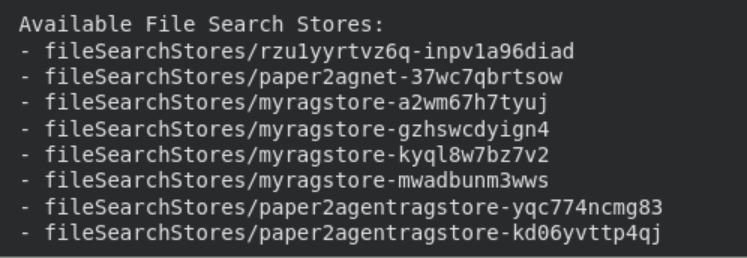
# Get detailed information
particulars = consumer.file_search_stores.get(identify=file_search_store.identify)
print("n Retailer Particulars:n", particulars
# Delete the shop (elective cleanup)
consumer.file_search_stores.delete(identify=file_search_store.identify, config={'pressure': True})
print("File Search Retailer deleted.")
Diese Verwaltungsoptionen tragen dazu bei, Ihre Umgebung organisiert zu halten. Indizierte Daten bleiben bis zur manuellen Löschung gespeichert, während über die temporäre Datei-API hochgeladene Dateien nach 48 Stunden automatisch entfernt werden.
Lesen Sie auch: 12 Dinge, die Sie mit der kostenlosen Gemini-API tun können
Preise und Limits
Das Dateisuchtool soll für jeden Entwickler einfach und erschwinglich sein. Jede hochgeladene Datei kann bis zu 100 MB groß sein und Sie können bis zu 10 Dateisuchspeicher professional Projekt erstellen. Die kostenlose Stufe ermöglicht 1 GB Gesamtspeicher in Dateisuchspeichern, während die höheren Stufen respektvoll 10 GB, 100 GB und 1 TB für Stufe 1, Stufe 2 und Stufe 3 zulassen.
Die Indizierungseinbettungen kosten 0,15 US-Greenback professional einer Million verarbeiteter Token, aber sowohl Speichereinbettungen als auch Einbettungsabfragen, die Daten zur Laufzeit indizieren, sind kostenlos. Abgerufene Dokument-Tokens werden als reguläre Kontext-Tokens abgerechnet, wenn sie bei der Generierung verwendet werden. Der Speicher beansprucht etwa das Dreifache Ihrer Dateigröße, da die Einbettungen zusätzlichen Speicherplatz beanspruchen.
Das Dateisuchtool wurde für Reaktionszeiten mit geringer Latenz entwickelt und antwortet selbst bei großen Dokumentenmengen schnell und zuverlässig auf Anfragen. Dies gewährleistet ein reibungsloses Reaktionserlebnis für Ihre Abrufe und generativen Aufgaben.
Unterstützte Modelle
Die Dateisuche ist auf beiden verfügbar Gemini 2.5 Professional und Gemini 2.5 Flash-Modelle. Beide unterstützen Begründung, Metadatenfilterung und Zitate. Dies bedeutet, dass es auf die genauen Abschnitte der Dokumente verweisen kann, die zur Formulierung der Antworten verwendet wurden, und so die Genauigkeit und Verifizierung der Antworten erhöht.
Lesen Sie auch: Wie kann ich auf die Gemini-API zugreifen und sie verwenden?
Abschluss
Das Gemini File Search Software soll RAG für alle einfacher machen. Es kümmert sich um die komplizierten Aspekte wie Chunking, Einbettung und Suche direkt innerhalb der Gemini-API. Entwickler müssen keine Abrufpipelines selbst erstellen oder mit einer externen Datenbank arbeiten. Nachdem Sie eine Datei hochgeladen haben, erfolgt alles automatisch.
Mit kostenlosem Speicherplatz, integrierten Zitaten und schnellen Reaktionszeiten hilft Ihnen File Search dabei, fundierte, zuverlässige und datenbewusste KI-Systeme zu erstellen. Es entlastet Entwickler vom mühsamen und sorgfältigen Bauen, spart Zeit und behält gleichzeitig die Kontrolle, Genauigkeit und Integrität.
Sie können jetzt mit der Einrichtung der Dateisuche in Google AI Studio oder über die Gemini-API beginnen. Es ist eine wirklich einfache, schnelle und sichere Möglichkeit, robuste, intelligente Anwendungen zu erstellen, die tatsächliche Daten verantwortungsvoll nutzen.
Hallo, ich bin Janvi, ein leidenschaftlicher Information-Science-Fanatic, der derzeit bei Analytics Vidhya arbeitet. Meine Reise in die Welt der Daten begann mit einer tiefen Neugier, wie wir aus komplexen Datensätzen aussagekräftige Erkenntnisse gewinnen können.
Melden Sie sich an, um weiterzulesen und von Experten kuratierte Inhalte zu genießen.