Spoiler-Alarm: Die Antwort ist vielleicht! Allerdings verrät die Verwendung des Wortes „eigentlich“ meine Voreingenommenheit.
Vektordatenbanken haben derzeit ihren großen Durchbruch. Drei verschiedene Vektordatenbank-Unternehmen haben Geld mit Bewertungen von bis zu 700 Millionen Greenback eingesammelt (Paywall-Hyperlink). Überraschenderweise liegt ihr Popularitätsanstieg nicht an ihrem „ursprünglichen“ Zweck in Empfehlungssystemen, sondern eher an ihrer Verwendung als Hilfswerkzeug für Massive Language Fashions (LLMs). Viele On-line-Beispiele für die Kombination von Embeddings mit LLMs zeigen Ihnen, wie sie die Embeddings in einer Vektordatenbank speichern.
Während dies für einen Proof of Idea intestine und schnell ist, ist die Einführung einer neuen Infrastruktur immer mit Kosten verbunden, insbesondere wenn es sich bei dieser Infrastruktur um eine Datenbank handelt. Ich werde in diesem Blogbeitrag ein wenig auf diese Kosten eingehen, aber mich interessiert vor allem, ob es überhaupt einen greifbaren Nutzen gibt.
Warum eine Vektordatenbank?
Ich denke, ich werde die obligatorische Erklärung der Einbettungen überspringen. Andere haben Erledigt Das viel besser als ich. Nehmen wir additionally an, Sie wissen, was Einbettungen sind und dass Sie planen, einige davon einzubetten. Dinge (wahrscheinlich Dokumente, Bilder oder „Entitäten“ für ein Empfehlungssystem). Normalerweise verwenden die Leute eine Vektordatenbank, damit sie schnell die Am ähnlichsten Einbettungen zu einer gegebenen Einbettung. Vielleicht haben Sie eine Reihe von Bildern eingebettet und möchten andere Hunde finden, die einem bestimmten Hund ähnlich sehen. Oder Sie betten den Textual content einer Suchanfrage ein und möchten die 10 Dokumente finden, die der Suchanfrage am ähnlichsten sind. Mit Vektordatenbanken können Sie dies sehr schnell erledigen.
Vorsätzliche Berechnung
Vektordatenbanken können Ähnlichkeiten schnell berechnen, weil sie diese bereits vorab berechnet haben. Ähm, um honest zu sein, sie haben etwa vorab berechnet. Für $N$ Entitäten sind $O(N^{2})$ Berechnungen erforderlich, um die Ähnlichkeit zwischen jedem einzelnen Ingredient und jedem anderen Ingredient zu berechnen. Wenn Sie Spotify sind und über 100 Millionen Titel haben, kann dies eine ziemlich große Berechnung sein! (Zum Glück ist es zumindest peinlich parallel). Vektordatenbanken ermöglichen es Ihnen, etwas Genauigkeit gegen Geschwindigkeit einzutauschen, sodass Sie die (ungefähr) ähnlichsten Entitäten zu einer bestimmten Entität problemlos berechnen können.
Musst du Vor-aber die Ähnlichkeit zwischen jeder Entität berechnen? Ich denke dabei an Batch versus Streaming für Knowledge Engineering oder Batch-Vorhersage versus Echtzeit-Inferenz für ML-Modelle. Ein Vorteil von Batch ist, dass es Echtzeit vereinfacht. Ein Nachteil von Batch ist, dass Sie berechnen müssen allesunabhängig davon, ob Sie es wirklich brauchen oder nicht.
Um Ähnlichkeiten zu messen, können Sie diese Berechnung in Echtzeit durchführen. Für insgesamt $N$ Entitäten beträgt die Zeitkomplexität für die Berechnung der okay ähnlichsten Entitäten zu einer bestimmten Entität $O(N)$. Dies ergibt sich aus einigen Annahmen: Wir verwenden Kosinusähnlichkeit als Ähnlichkeitsmetrik und gehen davon aus, dass die Einbettungen bereits normalisiert wurden. Dann beträgt es für eine Einbettungsdimension $d lt lt N$ $O(Nd)$, die Ähnlichkeit zwischen einer bestimmten Einbettung und allen anderen $N$ Einbettungen zu berechnen. Um die okay ähnlichsten Entitäten zu finden, müssen wir ein weiteres $O(N + okay log(okay))$ hinzufügen. Das ergibt insgesamt ungefähr $O(N)$.
In numpyDie „Echtzeit“-Berechnung umfasst 3 Codezeilen:
# vec -> 1D numpy array of form D
# mat -> 2D numpy array of form N x D
# okay -> variety of most comparable entities to search out.
similarities = vec @ mat.T
partitioned_indices = np.argpartition(-similarities, kth=okay)(:okay)
top_k_indices = partitioned_indices(np.argsort(-similarities(partitioned_indices)))
Beweisbasierte Behauptungen
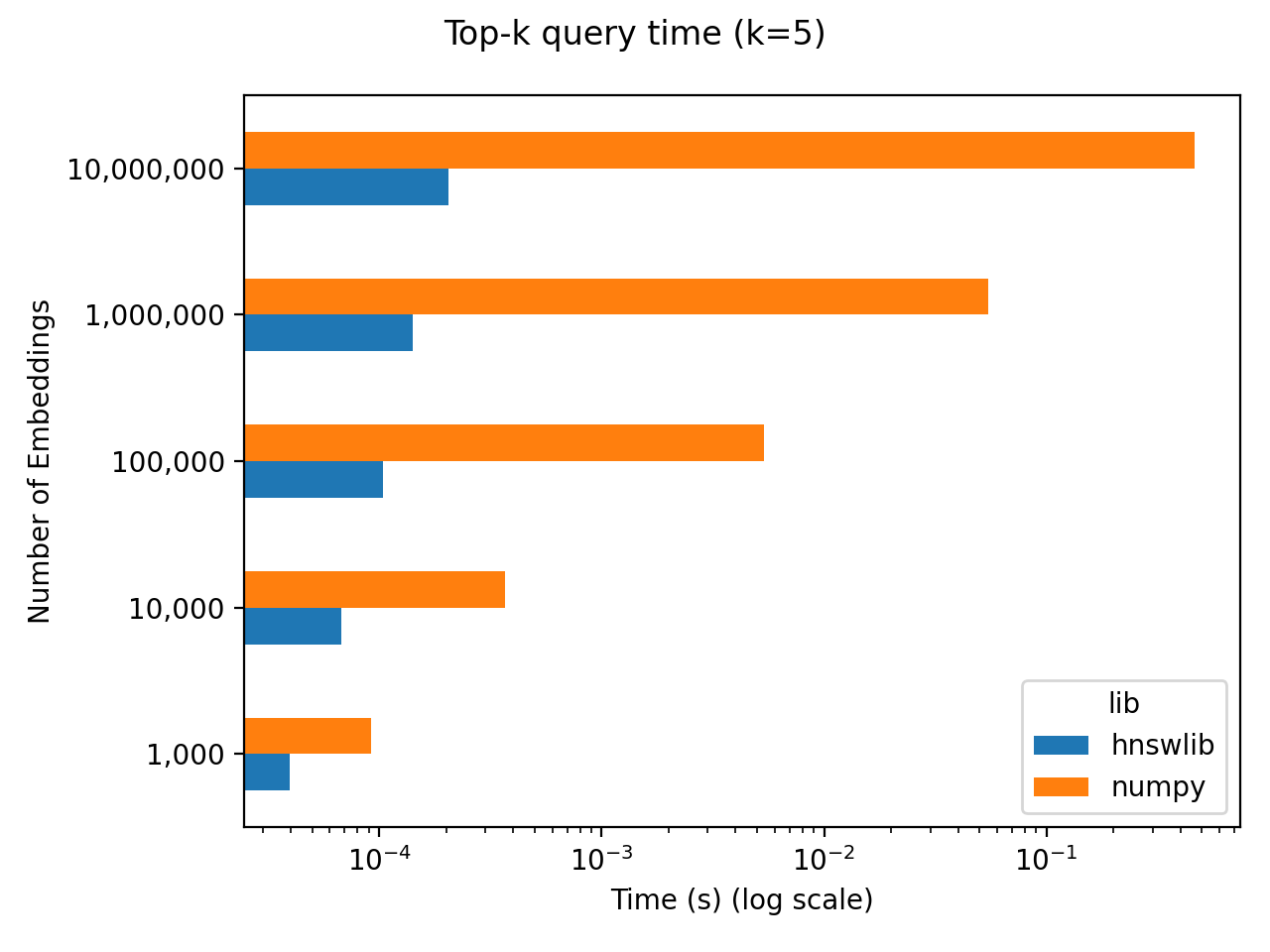
Abhängig von Ihrer Größe von $N$ und Ihren Latenzanforderungen kann $O(N)$ sehr vernünftig sein! Um meinen Standpunkt zu beweisen, habe ich einen kleinen Benchmark zusammengestellt. Den gesamten Code für den Benchmark finden Sie hier nn-gegen-ann GitHub-Repository.
Für meinen Benchmark initialisiere ich zufällig $N$ Einbettungen mit jeweils 256 Dimensionen. Dann messe ich die Zeit, die es braucht, um die 5 „nächsten Nachbarn“ (additionally die ähnlichsten) Einbettungen zu einer bestimmten Einbettung auszuwählen. Ich führe diesen Benchmark für einen Bereich von $N$ Werten mit zwei verschiedenen Ansätzen durch:
numpyist die „Echtzeit“-Berechnung, die die nächste Nachbarberechnung mit voller Genauigkeit und ohne Vorkalkulation durchführt.hnswlibVerwendet hnswlib um ungefähre nächste Nachbarn vorab zu berechnen.
Die Ergebnisse sind unten dargestellt, wobei beide Achsen logarithmisch sind. Es ist schwer zu erkennen, wenn wir es mit logarithmisch-logischen Skalen zu tun haben, aber numpy skaliert linear mit $N$. Die Latenz beträgt ungefähr 50 Millisekunden professional Million Einbettungen. Je nach Ihren $N$- und Latenzanforderungen können 50 ms für 1 Million Einbettungen vollkommen ausreichend sein! Darüber hinaus sparen Sie sich die Komplikation, eine Vektordatenbank einzurichten und die ~100 Sekunden zu warten, um diese Millionen Einbettungen zu indizieren.
Aber das ist nicht honest
Eyyyyy, du hast mich erwischt! Ich habe viele Faktoren in diesem Argument übersehen und ignoriert. Hier sind ein paar Gegenargumente, die related sein könnten:
- Der
numpyDieser Ansatz erfordert, dass ich alles im Speicher behalte, was nicht skalierbar ist. - Wie kann man das überhaupt in die Produktion umsetzen?
numpyAnsatz? Einlegen undarray? Das klingt schrecklich, und wie aktualisiert man es dann? - Was ist mit all den anderen Vorteilen einer Vektordatenbank, wie beispielsweise der Metadatenfilterung?
- Was ist, wenn ich wirklich viele Einbettungen habe?
- Sollten Sie nicht mit dem Hacken aufhören und stattdessen einfach das richtige Werkzeug für die jeweilige Aufgabe verwenden?
Lassen Sie mich nun meine eigenen Gegenargumente vorbringen:
1. Die numpy Dieser Ansatz erfordert, dass ich alles im Speicher behalte, was nicht skalierbar ist.
Ja, obwohl Vektordatenbanken auch erfordern, dass Dinge im Speicher gehalten werden (glaube ich?). Außerdem können Sie heutzutage Maschinen mit sehr viel Speicher erwerben. Außerdem können Sie Ihre Einbettungen im Speicher abbilden, wenn Sie Speicher gegen Zeit tauschen möchten.
2. Wie kann man das überhaupt produzieren? numpy Ansatz? Einlegen und array? Das klingt schrecklich, und wie aktualisiert man es dann?
Ich bin froh, dass du gefragt hast! Ich habe tatsächlich produziert diesen Ansatz bei einem Startup, bei dem ich gearbeitet habe. Jeden Tag habe ich ein kontrastives Lernmodell für Bildähnlichkeiten trainiert, um gute Bilddarstellungen zu lernen. Ich habe die Bildeinbettungen als JSON in S3 geschrieben. Ich hatte eine API, die die ähnlichsten Bilder für ein Eingabebild berechnete, indem ich die numpy Methode im Benchmark. Diese API hatte einen asynchronen Hintergrundjob, der von Zeit zu Zeit nach neuen Einbettungen auf S3 suchte. Wenn neue Einbettungen gefunden wurden, wurden sie einfach in den Speicher geladen.
3. Was ist mit all den anderen Vorteilen einer Vektordatenbank, wie beispielsweise der Metadatenfilterung?
Ja, und deshalb sollten Sie vielleicht einfach Ihre vorhandene Datenbank verwenden (oder sogar Erweitern Sie es!) oder eine bewährte Dokumentendatenbank wie Elasticsearch anstelle einer Vektordatenbank. Wenn Sie nach verschiedenen Metadaten filtern müssen, speichern Sie diese Metadaten bereits in Ihrer „normalen“ Datenbank? Wenn ja, wird es ärgerlich sein, diese Daten mit einem neuen System synchronisieren zu müssen. Ich bin sicherlich kein Fan von diesem.
4. Was ist, wenn ich wirklich viele Einbettungen habe?
Dann müssen Sie vielleicht einfach eine spezialisierte Vektor-Datenbank verwenden (obwohl ich glaube, dass Elasticsearch unterstützt ungefähre nächste Nachbarn). Eine Sache, die ich noch einmal überprüfen würde, ist, dass Sie Ihre Suche nicht auf eine vernünftige Anzahl von Einbettungen reduzieren können, bevor Sie Ihre Ähnlichkeitsberechnungen durchführen. Wenn Sie beispielsweise nach den ähnlichsten Hemden zu einem bestimmten Hemd suchen, müssen Sie keine Ähnlichkeiten für Nicht-Hemden berechnen!
5. Sollten Sie nicht mit dem Hacken aufhören und stattdessen einfach das richtige Werkzeug für die jeweilige Aufgabe verwenden?
Wie bei den meisten Dingen gehe ich davon aus, dass das richtige Instrument für die Aufgabe wahrscheinlich das Instrument ist, das Sie bereits verwenden. Und dieses Instrument ist wahrscheinlich Postgres oder Elasticsearch, wenn Sie es wirklich brauchen.
Schöne neue Welt
Meine Argumente sind vielleicht alle hinfällig, wenn man bedenkt, dass wir uns in eine Welt großer, offener LLMs bewegen, die Zugriff auf beispielsweise die gesamte Wikipedia benötigen, um Fragen beantworten zu können. Für diese Anwendungen sind Vektordatenbanken sicherlich sinnvoll. Mich interessieren jedoch eher nicht offene LLMs, und ich frage mich, inwieweit diese Vektordatenbanken erfordern werden. Mal sehen, was passiert! Bei dem Tempo, in dem die Dinge voranschreiten, kann ich den Nachmittag nicht vorhersagen, additionally werde ich einfach versuchen, mein Mittagessen zu genießen.