tl;dr -> Ich habe einen impliziten Suggestions-Datensatz zusammen mit Nebeninformationen zu den Artikeln gesammelt. Dieser Datensatz enthält etwa 62.000 Benutzer und 28.000 Artikel. Alle Daten leben Hier Innen Das Repo. Viel Spaß!
In einer früheren Put uphabe ich darüber geschrieben, wie man Matrixfaktorisierung und explizite Suggestions-Daten verwendet, um Empfehlungssysteme aufzubauen. Dabei handelt es sich um Daten, bei denen ein Benutzer eine klare Präferenz für einen Artikel angegeben hat, wie etwa eine Sternebewertung für ein Amazon-Produkt oder eine numerische Bewertung für einen Movie wie in der Filmobjektiv Daten. Ein natürlicher nächster Schritt ist die Diskussion von Empfehlungssystemen für implizites Suggestions, additionally Daten, bei denen ein Benutzer eine Präferenz für einen Eintrag wie „Anzahl der Hörminuten“ für einen Tune auf Spotify oder „Anzahl der Klicks“ für ein Produkt auf einer Web site.
Implizite Suggestions-basierte Techniken machen wahrscheinlich den Großteil moderner Empfehlungssysteme aus. Als ich mich daran machte, einen Beitrag über diese Techniken zu schreiben, fiel es mir schwer, geeignete Daten zu finden. Das ist verständlich – die meisten Unternehmen scheuen sich, Klick- oder Nutzungsdaten von Benutzern weiterzugeben (und das aus gutem Grund). Eine oberflächliche Google-Suche ergab ein paar Datensätze, die von Leuten verwendet werden, aber ich fand immer wieder Probleme mit diesen Datensätzen. Beispielsweise zeigte sich, dass die Million Tune-Datenbank manche Probleme mit der Datenqualität, während viele andere Menschen habe die MovieLens- oder Netflix-Daten einfach zweckentfremdet, als wären sie implizit (was sie nicht sind).
Das fühlte sich an wie eine dieser „Scheiß drauf, ich mach das selbst“-Situationen. Und das tat ich dann auch.
Der gesamte Code zum Sammeln dieser Daten befindet sich auf meinem github. Die tatsächlich gesammelten Daten befinden sich ebenfalls in diesem Repo.
Als ich noch Scholar struggle, dachte ich eine Zeit lang, dass ich vielleicht im {Hardware}-Bereich arbeiten würde (oder in einem Museum, in der Regierung oder in einer Unmenge anderer Dinge). Ich wollte einen öffentlichen, digitalen Beweis meiner (beschissen) CAD-Kenntnisse, und ich stieß auf Skizzenfabeine Web site, auf der Sie 3D-Renderings teilen können, die jeder andere mit einem Browser drehen, vergrößern oder animiert ansehen kann. Es ist so etwas wie YouTube für 3D (und jetzt auch VR!).
Benutzer können 3D-Modelle „liken“, was ein hervorragendes implizites Sign ist. Es stellt sich heraus, dass man tatsächlich sehen kann, welchem Benutzer welches Modell gefallen hat. Dies ermöglicht vermutlich die Rekonstruktion der klassischen Empfehlungssystem-„Bewertungsmatrix“ von Benutzer als Zeilen und 3D-Modelle als Spalten mit Likes als Elemente in der dünn besetzten Matrix.
Okay, ich kann die Likes auf der Web site sehen, aber wie komme ich eigentlich an die Daten?
Als ich bei Einblicke in die Datenwissenschaftbaute ich ein hässliches Skript um eine Nachhilfe-Web site zu scrapen. Das struggle relativ einfach. Die Web site struggle größtenteils statisch, additionally habe ich BeautifulSoup verwendet, um einfach das HTML zu analysieren.
Sketchfab ist eine modernere Web site mit umfangreichem JavaScript. Man muss warten, bis das JavaScript das HTML rendert, bevor man es analysiert. Eine Methode zur Automatisierung dieses Vorgangs ist die Verwendung von Selen. Mit dieser Software program können Sie im Wesentlichen Code schreiben, um einen echten Webbrowser zu steuern.
Um Selenium nutzen zu können, müssen Sie zunächst einen Treiber für Ihren Browser herunterladen. Ich habe Hier um einen Chrome-Treiber zu erhalten. Das Python Selenium-Paket kann dann mit Anaconda auf dem Conda-Forge-Kanal installiert werden:
conda set up --channel https://conda.anaconda.org/conda-forge selenium
Das Öffnen eines Browserfensters mit Selenium ist ganz einfach:
from selenium import webdriver
chromedriver = '/path/to/chromedriver'
BROWSER = webdriver.Chrome(chromedriver)
Jetzt müssen wir entscheiden, wohin der Browser zeigen soll.
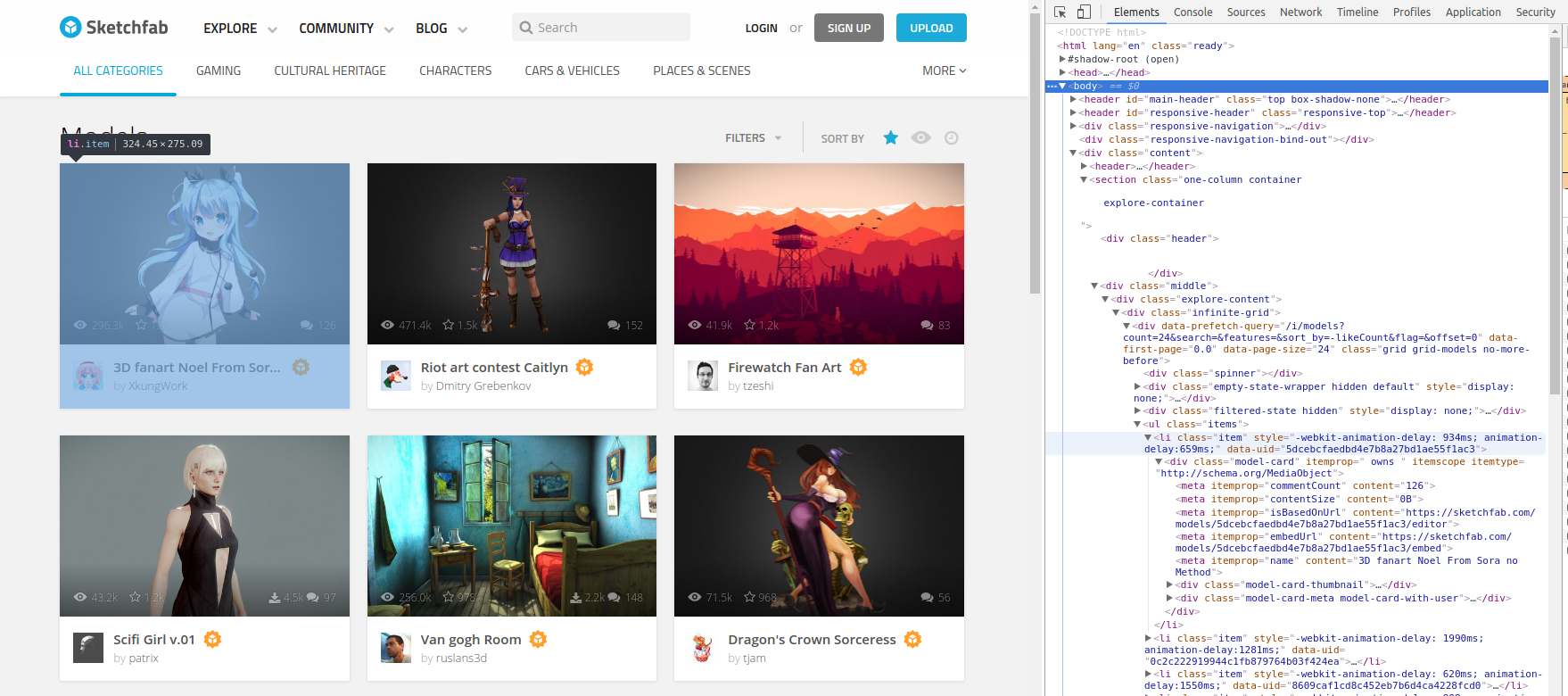
Sketchfab hat über 1 Million 3D-Modelle und mehr als 600.000 Benutzer. Allerdings hat nicht jeder Benutzer ein Modell geliked, und nicht jedes Modell wurde von einem Benutzer geliked. Ich beschloss, meine Suche auf Modelle zu beschränken, die von mindestens 5 Benutzern geliked wurden. Um mit dem Crawlen zu beginnen, ging ich zu „alle“ Seite für beliebte Modelle (sortiert nach Anzahl der Likes, absteigend) und begann von oben zu kriechen.
BROWSER.get('https://sketchfab.com/fashions?sort_by=-likeCount&web page=1')
Wenn Sie die Hauptseite der Modelle öffnen, können Sie die Chrome-Entwicklertools öffnen (Strg-Umschalt-I unter Linux), um die HTML-Struktur der Seite anzuzeigen. Diese sieht wie folgt aus (klicken, um sie in voller Größe anzuzeigen):
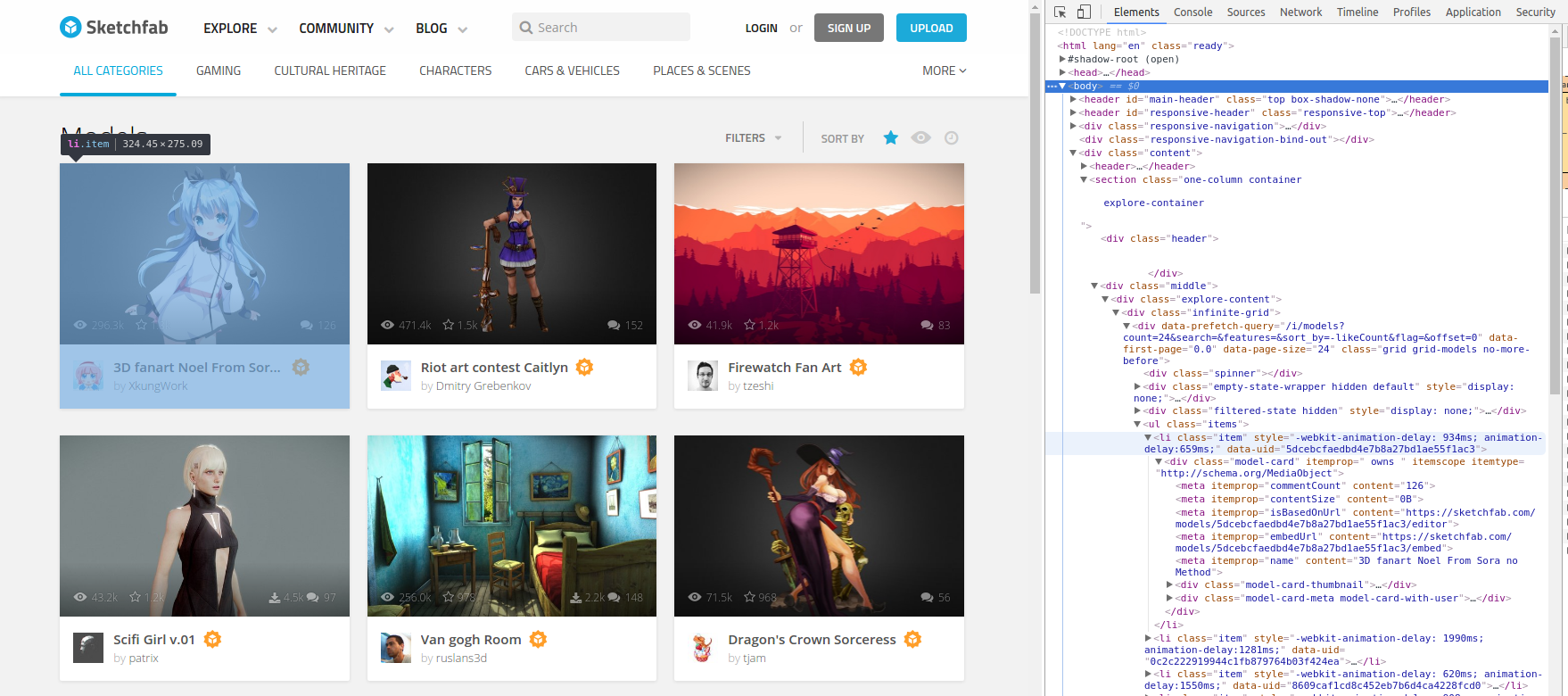
Ein Blick in das HTML zeigt, dass alle angezeigten 3D-Modelle in einem <div> der Klasse infinite-gridJedes 3D-Modell befindet sich in einem <li> Component mit Klasse merchandiseDie Liste aller dieser Listenelemente kann man sich wie folgt holen:
elem = BROWSER.find_element_by_xpath("//div(@class='infinite-grid')")
item_list = elem.find_elements_by_xpath(".//li(@class='merchandise')")
Es stellt sich heraus, dass jedes Sketchfab-Modell eine eindeutige ID hat, die wir als Modell-ID bezeichnen werden, oder mid. Das mid finden Sie in jedem Listenelement über die data-uid Attribut.
merchandise = item_list(0)
mid = merchandise.get_attribute('data-uid')
Die URL für das Modell lautet dann einfach https://sketchfab.com/fashions/mid wo Sie ersetzen mid durch die tatsächliche eindeutige ID.
Ich habe ein Skript geschrieben, das diese Sammlung von jedem automatisiert midDieses Skript heißt crawlen.py im Wesentlichen repoUm alle Modell-URLs zu protokollieren, führt man
python crawl.py config.yml --type urls
Insgesamt habe ich 28.825 Modelle (Stand Oktober 2016) gefunden. Der Modellname und die dazugehörigen mid sind in der Datei model_urls.psv Hier.
Um zu protokollieren, welchem Benutzer welches Modell gefallen hat, habe ich ursprünglich ein Selenium-Skript geschrieben, um zur URL jedes Modells zu gehen und durch die Benutzer zu scrollen, denen das Modell gefallen hat. Das hat verdammt lange gedauert. Mir wurde klar, dass Sketchfab diese Informationen vielleicht über eine API bereitstellt. Ich habe eine schnelle Google-Suche durchgeführt und bin auf Folgendes gestoßen Greg Redas Weblog Put up Darin wurde beschrieben, wie man halbgeheime APIs zum Sammeln von Daten verwendet. Und tatsächlich hat das für meine Aufgabe perfekt funktioniert!
Mit einem mid in der Hand kann man die API erreichen, indem man die folgenden Parameter übergibt
import requests
mid = '522e811044bc4e09bf84431e6c1cc109'
rely = 24
params = {'mannequin':mid, 'rely':rely, 'offset':0}
url = 'https://sketchfab.com/i/likes'
response = requests.get(url, params=params).json()
Innen response('outcomes') ist eine Liste mit Informationen zu jedem Benutzer, dem das Modell gefallen hat. crawl.py verfügt über eine Funktion zum Einlesen der Modell-URL-Datei, die ausgegeben wird von crawl.py und sammeln Sie dann alle Benutzer, denen dieses Modell gefallen hat.
python crawl.py config.yml --type likes
Nachdem ich dieses Skript Anfang Oktober 2016 ausgeführt und Likes für 28.825 Modelle gesammelt hatte, hatte ich Daten zu 62.583 Benutzern und 632.840 Modell-Benutzer-ähnlichen Kombinationen! Diese Daten sind zum Glück klein genug, um noch in ein GitHub-Repo (52 MB) zu passen und leben Hier
Obwohl diese Likes öffentlich sind, hatte ich ein schlechtes Gewissen, weil ich diese Daten so einfach öffentlich analysieren konnte. Ich schrieb ein kleines Skript namens anonymize.py das die Benutzer-IDs für die Modell-Likes hasht. Das Ausführen dieses Skripts ist einfach (stellen Sie nur sicher, dass Sie Ihren eigenen geheimen Schlüssel angeben):
python anonymize.py unanonymized_likes.csv anonymized_likes.csv "SECRET KEY"
Die Like-Daten im Haupt-Repo wurden anonymisiert.
Ein spannender Bereich der Empfehlungsforschung ist die Kombination von Benutzer- und Artikelinformationen mit implizitem oder explizitem Suggestions. In späteren Beiträgen werde ich diesen Bereich ansprechen, aber jetzt wollen wir erst einmal versuchen, einige Nebeninformationen zu erfassen. Sketchfab-Benutzer können Modelle, die sie hochladen, kategorisieren (z. B. „Figuren“, „Orte und Szenen“ usw.) und ihre Modelle mit relevanten Bezeichnungen versehen (z. B. „Vogel“, „Maya“, „Mixer“, „Skulptur“ usw.). Vermutlich könnten diese zusätzlichen Informationen über Modelle hilfreich sein, um genauere Empfehlungen abzugeben.
crawl.py hat eine weitere Funktion zum Erfassen der zugehörigen Kategorien und Tags eines Modells. Ich konnte keine API-Möglichkeit dafür finden und das Selenium-Crawlen ist extrem langsam. Zum Glück habe ich die Daten bereits für Sie 🙂 Die Datei „Options“ des Modells heißt model_feats.psv und befindet sich im Verzeichnis /information des Hauptrepos.
python crawl.py config.yml --type options
Mit all unseren Daten in der Hand werden nachfolgende Blogbeiträge in den Wilden Westen der impliziten Suggestions-Empfehlungssysteme eintauchen. Ich zeige Ihnen, wie Sie diese Modelle trainieren, verwenden und dann eine einfache Flask-App namens Rec-a-Sketch erstellen, um 3D-Sketchfab-Empfehlungen bereitzustellen.