Pünktlich zu Halloween haben wir eine schaurig-effektive Umsetzung von Stan im Netz, vollgestopft mit einem wahren Spukhaus voller köstlicher Leckereien.
Brian Ward, Jeff Soules und Jeremy Magland schreiben:
Stan-Spielplatz ist ein neuer browserbasierter Open-Supply-Editor und eine Laufzeitumgebung für Stan-Modelle. Benutzer können Modelle bearbeiten, kompilieren und ausführen sowie die Ergebnisse mithilfe integrierter Diagramme und Statistiken oder benutzerdefinierten Analysecodes in Python oder R analysieren, ohne dass eine lokale Set up erforderlich ist. . . .
Egal, ob Sie ein neuer Benutzer sind, ein Pädagoge, der Stan etwas beibringen möchte, oder ein erfahrener Benutzer, der seinen neuen Laptop computer einfach noch nicht konfiguriert hat, wir hoffen, Ihnen das Leben ein wenig einfacher zu machen.
Die Dwell-Web site können Sie hier besuchen: https://stan-playground.flatironinstitute.org
Funktionsübersicht
Für Benutzer, die mit Instruments wie dem Compiler Explorer 1, repl.it oder JSFiddle vertraut sind, hofft Stan Playground, ein ähnliches Erlebnis für Stan-Modelle bieten zu können.
Stan-Herausgeber
Die Web site verfügt über einen Editor für Stan-Code mit Syntaxhervorhebung und stellt Warnungen und Fehler vom Stan-Compiler für sofortiges Suggestions bereit.
Kompilieren von Modellen
Die Zusammenstellung der Modelle ist der einzige Teil von Stan Playground, der nicht lokal betrieben wird. Der Einfachheit halber stellen wir einen öffentlichen Server zur Verfügung, Sie können aber auch Ihren eigenen hosten.
Daten vorbereiten
Daten können im JSON-Format in einem eigenen Editor bereitgestellt oder aus Code generiert werden, der in R (mit webR) oder Python (mit Pyodide) geschrieben wurde, einschließlich Code, der veröffentlichte Datensätze importiert.
Probenahme
Nachdem ein Modell kompiliert wurde, kann die Probenahme vollständig in Ihrem lokalen Browser ausgeführt werden.
Ergebnisse anzeigen und analysieren
Stan Playground verfügt über mehrere integrierte Möglichkeiten zum Anzeigen der Beispiele, unterstützt aber auch die Durchführung Ihrer eigenen Analyse, wiederum in R oder Python.
Teilen
Stan Playground verfügt über integrierte Freigabefunktionen, mit denen Sie eine Kopie Ihres Projekts herunterladen, ein vorhandenes Projekt hochladen oder über einen Github Gist teilen können. . . Sie können auch benutzerdefinierte Hyperlinks vorbereiten. . . Über diesen Hyperlink wird beispielsweise die Fallstudie „Golf“ aus dem Beispielmodell-Repository geladen: https://stan-playground.flatironinstitute.org/?title=Knitrpercent20-%20Golfpercent20-%20Golfpercent20Angle&stan=https://uncooked.githubusercontent.com/stan-dev/example-models/grasp/knitr /golf/golf_angle.stan&information=https://uncooked.githubusercontent.com/stan-dev/example-models/grasp/knitr/golf/golf1.information.json
ICH habe es ausprobiert und es hat wirklich funktioniert!
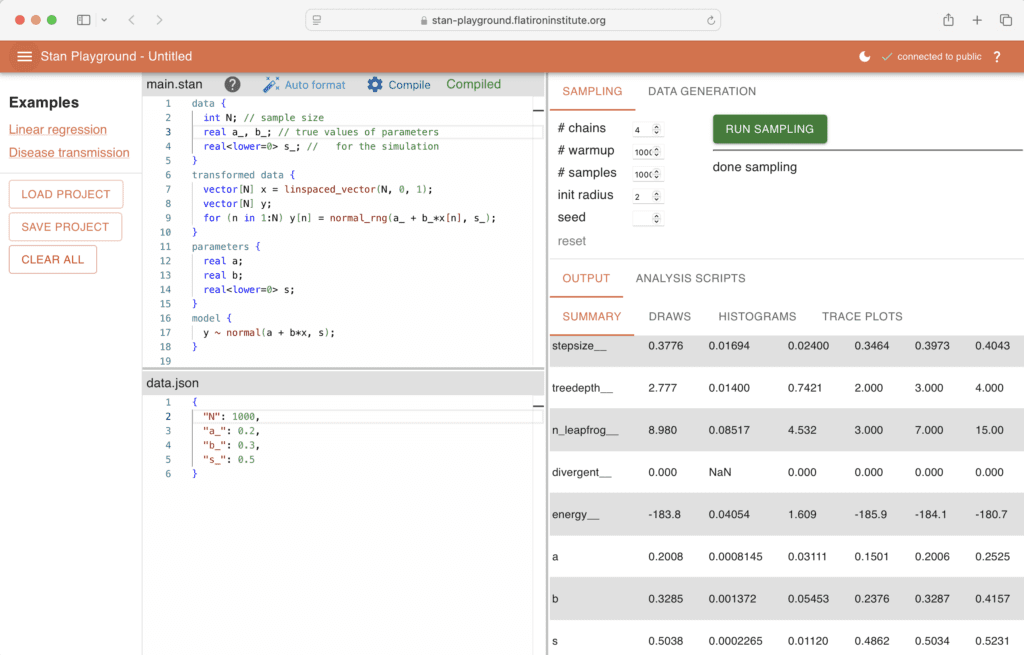
Ich habe ein einfaches Beispiel geschrieben, das gefälschte Daten aus einer linearen Regression mit bekannten Parametern (im transformierten Datenblock) simuliert und dann die Log-Posteriori-Dichte (im Modellblock) ausdrückt:
information {
int N; // pattern dimension
actual a_, b_; // true values of parameters
actual<decrease=0> s_; // for the simulation
}
reworked information {
vector(N) x = linspaced_vector(N, 0, 1);
vector(N) y;
for (n in 1:N) y(n) = normal_rng(a_ + b_*x(n), s_);
}
parameters {
actual a, b;
actual<decrease=0> s;
}
mannequin {
y ~ regular(a + b*x, s);
}
Mit Daten:
{
"N": 1000,
"a_": 0.2,
"b_": 0.3,
"s_": 0.5
}
Es ist so einfach
Dies einzurichten und in Stan Playground zu betreiben, ist die einfachste Sache der Welt:
1. Fügen Sie das Stan-Programm in das Stan-Programmfenster ein.
2. Geben Sie die Daten (in diesem Fall die Stichprobengröße der Regression und die wahren Parameterwerte) als .json in das Datenfenster ein und klicken Sie zum Speichern.
3. Klicken Sie im Befehlsfenster einmal zum Kompilieren und erneut zum Ausführen.
4. Die Ausgabe (in tabellarischer und grafischer Type) erscheint im Ausgabefenster.
Das ist es! Das Bild oben in diesem Beitrag zeigt die Ergebnisse.
Außerdem werden viele Fehler in der Kompilierungs- und Sampling-Part entdeckt.