Das ist Bob.
JAX im Kopf
Ich habe viel darüber nachgedacht JAX in letzter Zeit. Für einen Informatiker wie mich ist JAX aufgrund seiner wunderbar kompositorischen Architektur zum Codieren von Autodiff auf GPUs attraktiv. Hätte es JAX gegeben, als wir 2011 mit der Codierung von Stan begonnen haben, hätten wir es verwendet, anstatt unser eigenes Autodiff-System einzuführen. Anscheinend existierte Theano zu dieser Zeit, aber wir hörten davon erst lange nach der Veröffentlichung der ersten Model von Stan.
Warum JAX?
Ursprünglich wurde mein Interesse durch Matt Hoffmans Arbeit an Cheese-and-Meads-Samplern geweckt (zu faul, deren Großschreibungsmuster nachzuschlagen, additionally im Andrew-Stil), die massiv parallele HMC-Schritte auf der GPU verwenden (Matt warfare gezwungen, NUTS aufzugeben, weil es eine rekursive Struktur hat). ein Gräuel für die GPU-Beschleunigung). Es wird weiterhin durch Aussagen von Leuten wie z Elizaveta Semenovadie während der jüngsten StanCon in Oxford bekannt gab, dass sie Stan aufgeben musste und zu NumPyro wechselte, weil sie in Stan nicht einfach neuronale Netze programmieren konnte und Stan nicht auf der GPU skaliert (wir haben einige Operationen, an die gesendet werden kann). GPU, aber wir können nicht die gesamte Auswertung im Kernel behalten). Das große Feuer ist auf die Arbeit von Justin Domke und Abhinav Agrawal zur Normalisierung der Ströme zurückzuführen – sie haben ein Repo, Vistadas ihre Methoden implementiert, einschließlich einer stark verbesserten Model von Autodiff Variational Inference (ADVI) und einer Model von Actual Non-Quantity Preserving (realNVP) normalisierenden Flüssen. Gilad Turok, der hier als Forschungsanalyst arbeitet und sich für das nächste Jahr an der Graduiertenschule bewirbt, ist quick fertig mit einer besser entwickelten Model, die wir einreichen können Blackjax.
Wir sind noch nicht weit gekommen, aber bisher haben wir noch keine Dichte gefunden, bei der die realen NVP-Flüsse, gefolgt von der Wichtigkeits-Resampling, nicht annähernd perfekt passten. Beispielsweise könnte es zu einem hierarchischen IRT 2PL mit 1000 Parametern passen, ohne dass es eine andere Identifizierungsstrategie als Priors gibt, ein Modell, das Stan aufgrund des Produkts aus der Trichterstruktur der hinteren Geometrie überhaupt nicht intestine anpassen kann. Die ADVI- und realNVP-Varianten von Justin und Abhinav basieren auf der Fähigkeit von JAX, die logarithmischen Dichte- und Gradientenberechnungen massiv zu parallelisieren, um die stochastischen Gradienten, die zur Berechnung der KL-Divergenz verwendet werden, bis zu einer Konstanten (d. h. dem ELBO) zu stabilisieren.
Vergleich der Leistung von Stan und JAX
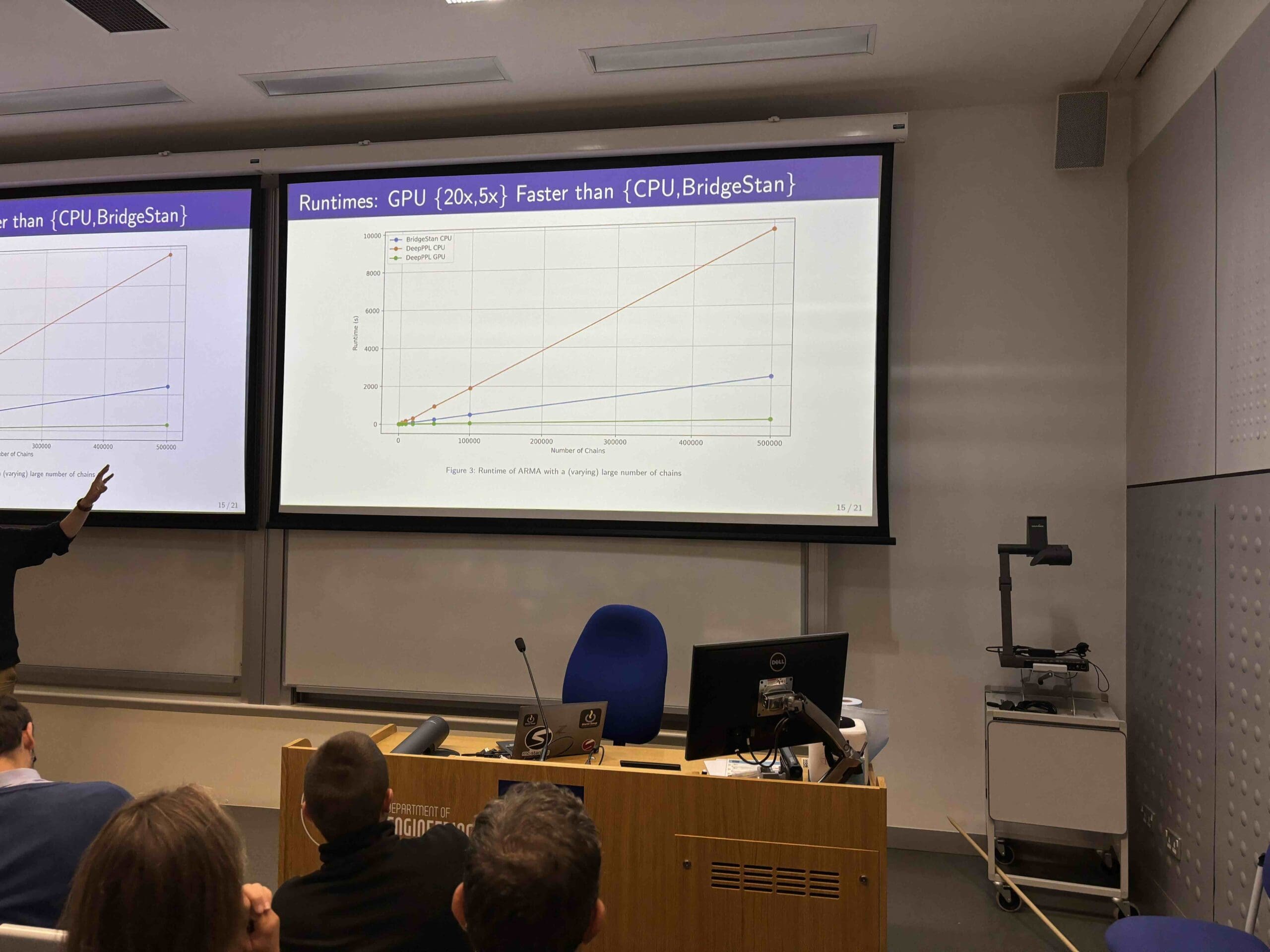
Auf der jüngsten StanCon in Oxford Simon Maskell präsentierte ein Ergebnis, das ich schon seit ein oder zwei Jahren generieren wollte, nämlich einen Vergleich von JAX und Stan auf der CPU. Hier präsentiert Simon (oder zumindest sein Arm!) das Ergebnis:

Wenn wir das Algebra-Drawback lösen, das Simons Folientitel darstellt (JG = 20 * JC, JG = 5 * SC, wobei JG JAX auf der GPU ist, JC JAX auf der CPU ist und SC Stan auf der CPU ist), sehen wir, dass JAX auf der GPU ist 5-mal schneller als Stan auf der CPU, was wiederum 4-mal schneller als JAX auf der CPU ist. Für die Bewertung verwendete Simon eine Excessive-Finish-NVIDIA-GPU der Verbraucherklasse (RTX). Wir werden Simons Ergebnisse in den nächsten Monaten auf unseren hochmodernen GPUs erneut ausführen und darüber berichten. Tensorflow hat vor ein paar Jahren eine ähnliche Auswertung mit ähnlichen Ergebnissen durchgeführt, aber ich konnte sie nicht finden.
CPU zu GPU im nächsten Jahrzehnt?
Das ist eigentlich ein bisschen schade, denn es bedeutet, dass wir für die meisten unserer Benutzer nicht wirklich auf JAX als Again-Finish umsteigen konnten, weil es auf CPUs nicht sehr leistungsfähig ist. Ich vermute, dass der durchschnittliche Stan-Benutzer in Bezug auf die Rechenleistung ein 5 Jahre altes Home windows-Pocket book ohne GPU besitzt. Ein Teil meines Interesses an Dingen wie JAX ist mein Gefühl, dass dies in 10 Jahren nicht mehr der Fall sein wird und quick jeder, der versucht, ein statistisches Modell anzupassen, an einem Cluster arbeiten wird.